Would love to discuss - these are all *opinions*, and I only seek to share my own thinking and the "bitter" lessons I have learned, having spent several years working on 3D computer vision-even though folks smarter than me confronted me with some of these same questions early on!
17.02.2026 14:03 —
👍 1
🔁 0
💬 0
📌 0
I believe that the differentiation between "robot learning" and "computer vision" does not make sense anymore in our present time. We as computer vision researchers should proactively tackle the question of decision-making, and should not shy away from learning policies :)
17.02.2026 14:03 —
👍 4
🔁 1
💬 1
📌 0
I present this as a corollary of the bitter lesson, which folks readily apply to *model architectures*, purging models of inductive biases, but less so to *intermediate representations* - yet, point clouds, NeRFs, camera poses, etc. are clever, task-specific tricks just the same.
17.02.2026 14:03 —
👍 2
🔁 0
💬 1
📌 0
The flavor of the bitter lesson for computer vision - Vincent Sitzmann
Personal website
In my recent blog post, I argue that "vision" is only well-defined as part of perception-action loops, and that the conventional view of computer vision - mapping imagery to intermediate representations (3D, flow, segmentation...) is about to go away.
www.vincentsitzmann.com/blog/bitter_...
17.02.2026 14:03 —
👍 22
🔁 3
💬 2
📌 1

History-Guided Video Diffusion
Classifier-free guidance (CFG) is a key technique for improving conditional generation in diffusion models, enabling more accurate control while enhancing sample quality. It is natural to extend this ...
For more information, please visit our paper arxiv.org/abs/2502.06764 and project website boyuan.space/history-guidance and. All credit goes to my students Kiwhan Song (still in his undergrad!) and Boyuan Chen, as well as awesome collaborators Yilun Du, Max Simchowitz, and Russ Tedrake. (7/7)
11.02.2025 20:37 —
👍 4
🔁 0
💬 0
📌 0
We show that DFoT alone is already a competitive model, matching or beating industry SOTA with way more compute than us. Together with HG, it can stably rollout very long videos, stay robust to out-of-distribution context, and stitch sub-trajectories (6/7)
11.02.2025 20:37 —
👍 2
🔁 0
💬 1
📌 0
DFoT enables History Guidance (HG), a family of history-conditioned guidance methods that composes diffusion scores from different histories. From its simplest form to its most advanced variant, HG significantly enhances video diffusion and unlocks new abilities. (5/7)
11.02.2025 20:37 —
👍 2
🔁 0
💬 1
📌 0
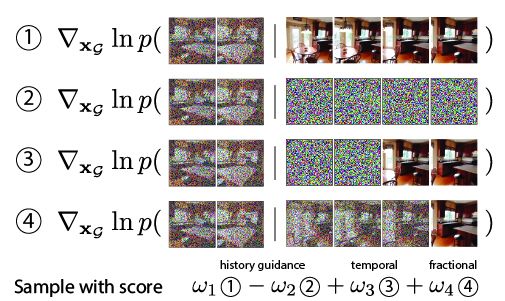
Unlike previous methods, DFoT views history or target alike as tokens of different noise levels. DFoT trains diffusion with varying noise levels per frame. To conditionally sample, one simply masks out a portion of history with noise before computing the diffusion score. (4/7)
11.02.2025 20:37 —
👍 0
🔁 0
💬 1
📌 0
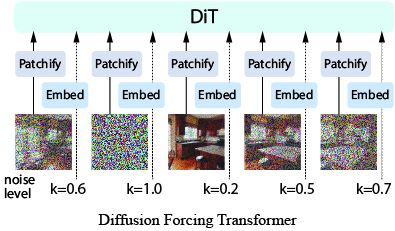
Can we train a single model to perform conditional diffusion with different portions of history - variable lengths, subsets of frames, and even different image-domain frequencies? Introducing DFoT, a simple yet flexible add-on that requires no architectural changes. (3/7)
11.02.2025 20:37 —
👍 0
🔁 0
💬 1
📌 0
Classifier-free Guidance (CFG) has been widely used by video diffusion models to boost sample quality. However, researchers rarely perform CFG beyond the first frame. Our paper finds that an equally important conditioning variable, the history, is the long-ignored key. (2/7)
11.02.2025 20:37 —
👍 0
🔁 0
💬 1
📌 0
Announcing Diffusion Forcing Transformer (DFoT), our new video diffusion algorithm that generates ultra-long videos of 800+ frames. DFoT enables History Guidance, a simple add-on to any existing video diffusion models for a quality boost. Website: boyuan.space/history-guidance (1/7)
11.02.2025 20:37 —
👍 35
🔁 6
💬 1
📌 0
Cool!
11.01.2025 11:31 —
👍 5
🔁 0
💬 0
📌 0
hey everyone - I am now also active here and excited about computer vision and machine learning stuff. 🎉
08.01.2025 14:07 —
👍 47
🔁 5
💬 3
📌 0
Friends in industry: As 2024 comes to a close, if your budget has room, consider joining the sponsors of the Summer Geometry Initiative (SGI)! SGI is entering year 5 with a proven track record bringing a diverse set of brilliant students into graphics/vision/ML/math research.
18.12.2024 15:59 —
👍 15
🔁 8
💬 2
📌 0
Was great chatting with your students, cool work!!
12.12.2024 16:45 —
👍 3
🔁 0
💬 0
📌 0
Wow, indeed!!
12.12.2024 16:44 —
👍 1
🔁 0
💬 0
📌 0
Hi NeurIPS crowd! Meet Boyuan Chen and I at the Diffusion Forcing poster today at 11 am, East Exhibit Hall A-C #2701! Concurrently, @justinmsolomon.bsky.social is jumping in for our student Artem to present "Score Distillation via Reparametrized DDIM" at #2402! - Artem had visa issues :(
12.12.2024 16:42 —
👍 13
🔁 3
💬 0
📌 0
If you are looking to do a PhD on inverse graphics, 3D computer vision, differentiable rendering, etc, please apply to Ayush's lab at the University of Cambridge! He is brilliant, very patient, and a kind human :)
02.12.2024 15:31 —
👍 7
🔁 0
💬 0
📌 0
Wow, what a warm welcome! Thanks, Kosta 🙃
23.11.2024 00:58 —
👍 2
🔁 0
💬 0
📌 0




