
🧮 Does quantization (GPTQ) impact cross-lingual knowledge transfer?
LLaMA-3.1-70B: 4-bit > 8-bit ⏩ accuracy drops MORE at 8-bit (up to 25%)
LLaMA-3.1-8B: 8-bit > 4-bit ⏩ accuracy drops MORE at 4-bit (up to 8%)
🧠 Bigger models aren’t always more robust to quantization.
30.05.2025 15:37 — 👍 2 🔁 0 💬 1 📌 0

🔊 LLMs can transfer knowledge across modalities (Text → Audio).
On GPT-4o-Audio vs Text:
📖 Direct Probing: 75.5% (vs. 92.3%)
👤 Name Cloze: 15.9% (vs. 38.6%)
✍️ Prefix Probing: 27.2% (vs. 22.6%)
Qwen-Omni shows similar trends but lower accuracy.
30.05.2025 15:37 — 👍 2 🔁 0 💬 1 📌 0

What if we perturb the text?
🧩 shuffled text
🎭 masked character names
🙅🏻♀️ passages w/o characters
🚨Reduce accuracy with the degree varying across languages BUT models can still identify the books better than newly published books (0.1%) 🚨
30.05.2025 15:37 — 👍 2 🔁 0 💬 1 📌 0

LLMs can identify book titles and authors across languages - even those not seen during pre-training:
63.8% accuracy on English passages
47.2% on official translations (Spanish, Turkish, Vietnamese) 🇪🇸 🇹🇷 🇻🇳
36.5% on completely unseen languages like Sesotho & Maithili 🌍
30.05.2025 15:37 — 👍 2 🔁 0 💬 1 📌 0
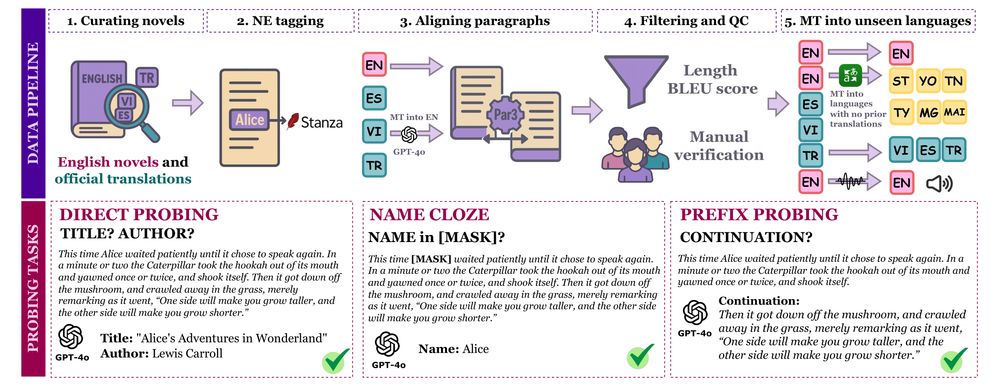
OWL has aligned excerpts from 20 EN novels, with translations in ES 🇪🇸, TR 🇹🇷, VI 🇻🇳 + 6 new low-resource languages 🌍 & EN audio 🔊
We probe LLMs to:
1️⃣ identify book/author (direct probing)
2️⃣ predict masked names (name cloze)
3️⃣ generate continuation (prefix probing)
30.05.2025 15:37 — 👍 3 🔁 0 💬 1 📌 0

LLMs memorize novels 📚 in English. But what about existing translations? Or translations into new languages?
Our 🦉OWL dataset (31K/10 languages) shows GPT4o recognizes books:
92% English
83% official translations
69% unseen translations
75% as audio (EN)
30.05.2025 15:37 — 👍 7 🔁 2 💬 1 📌 3


