Mañana a estas horas estaré en #CodemotionMadrid25 contándote cómo procesar y analizar datos rápidos en tiempo real usando open source. Hablaré de proyectos como Kafka, #QuestDB, o Grafana, pero tambien de formatos para datos y de qué problemas te vas a encontrar.
20.05.2025 12:05 — 👍 1 🔁 0 💬 0 📌 0
HOYGAN! Este viernes estaré en @commit-conf.com. Aprovechando que no es un evento virtual podemos hacer networking sin LinkedIn de por medio. Networking de café y sobao pasiego. Ya si eso, yo hablaré de cosas como Iceberg, Arrow o Parquet, y de cómo afectan a las bases de datos rápidas
01.04.2025 08:20 — 👍 4 🔁 1 💬 0 📌 0
This is what happens when you put together QuestDB and github.com/finos/perspe..., a data visualization tool designed for large and streaming data. Look at this cool blotter updating every 50ms with market data coming from QuestDB.
20.02.2025 15:42 — 👍 5 🔁 1 💬 0 📌 0
Screenshot from slack, showing Jaromir saying:
That's excellent news :tada:
I included a PHP test runner in the fix. So from now on PHP PDO has the same test coverage as we have for Python, Rust or C#. This should prevent future regressions.
Many thanks for your help: The report, reproducer and now the confirmation - it all helped greatly.
And that, kids, is how PHP made it into our codebase.
A user on PHP hit a QuestDB 8.2.2 issue. We gave an immediate workaround, then @jerrinot.bsky.social shipped a permanent fix 11 days later—with a new PHP test runner for coverage on par with Python or Rust. Community collaboration FTW!
19.02.2025 10:26 — 👍 1 🔁 1 💬 0 📌 0

Headshot of Javier with the title OSA CON 24 on top and to the right it says "INGESTING AND ANALYZING MILLIONS OF EVENTS PER SECOND IN REAL-TIME USING OPEN SOURCE TOOLS", "Javier Ramirez, Developer Advocate at QuestDB", "November 19-21, 2024, Free, online"
i'll be presenting tomorrow at #OSA conference about how you can analyze large amounts of streaming data in real-time using open source tools (AVRO+Kafka+QuestDB+Grafana+Jupyter Notebook). It is free to join and they have a ton of other interesting talks osacon.io
20.11.2024 12:40 — 👍 7 🔁 0 💬 0 📌 0

Gloomy landscape reminiscing of the batman call signal, but the city is Brussels as we can see the atomium and the grand place tower. There is a gear in the beam light, representing FOSDEM
Calling all open source data analytics lovers! This year at
@fosdem
we will have a DevRoom for the whole Saturday to talk about anything and everything data. Call for Presentations is open until the end of November. More info at javier.github.io/data_analyti...
31.10.2024 16:30 — 👍 8 🔁 2 💬 0 📌 0
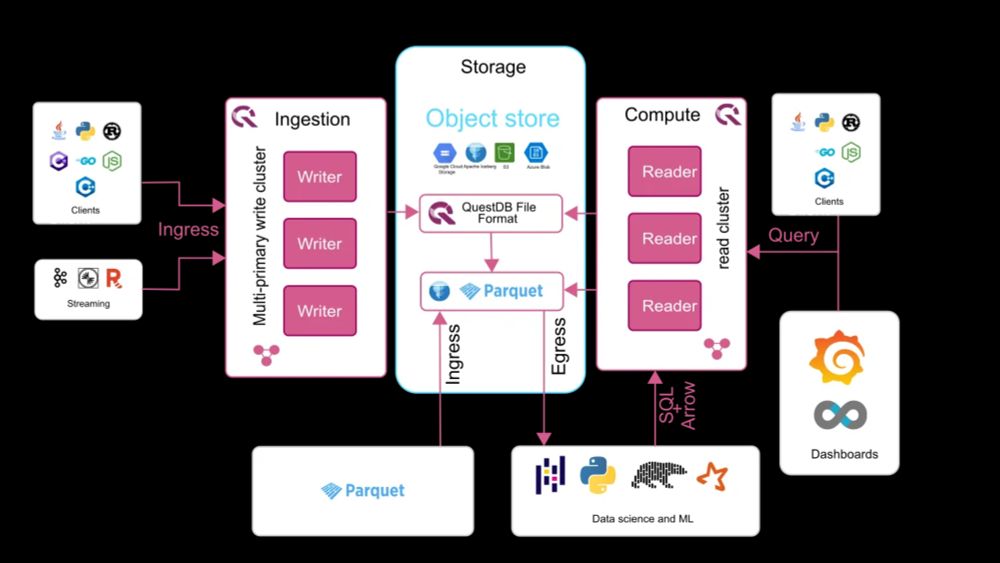
Some fast databases are already implementing some of these ideas, but to the best of my knowledge there is still none implementing them all. At #questdb we are working to make this happen. Stay tuned!
30.10.2024 10:35 — 👍 3 🔁 0 💬 0 📌 0
Lastly, compute and storage need to be decoupled, so the divide between recent and batch data is blurred. Deleting or downsampling old data might be acceptable, but it should not be mandatory. The query engine should be able to query over petabytes of storage if needed.
30.10.2024 10:34 — 👍 0 🔁 0 💬 1 📌 0
ngesting massive amounts of very fast data, querying quickly, and outputting small result sets to dashboards or apps is still useful; but you also need to support streaming out massive query result sets to other apps (e.g., ML apps).
30.10.2024 10:34 — 👍 0 🔁 0 💬 1 📌 0
The query engine should be able to efficiently query data produced by third parties just by pointing the engine to the parquet files and registering some metadata. Queries should support the whole range of features and perform as if data was ingested through the database.
30.10.2024 10:34 — 👍 0 🔁 0 💬 1 📌 0
Third parties wanting to use the data ingested via the database should have the option to skip completely the query engine and just read from the parquet files.
30.10.2024 10:34 — 👍 0 🔁 0 💬 1 📌 0
Fast databases should stop being gatekeepers of your data, and should be able to both store and consume data in open (parquet and friends) formats.
30.10.2024 10:34 — 👍 0 🔁 0 💬 1 📌 0
The future of fast databases: Lessons from a decade of QuestDB
Explore lessons from a decade of QuestDB and a look at the future of fast databases, presented at Big Data London 2024.
A few weeks ago I spoke at #bigdataldn about how the #questdb team sees the future of fast databases. I've now written a summary for our blog questdb.io/blog/the-fut.... Highlights of our thinking in the thread 🧵
30.10.2024 10:33 — 👍 4 🔁 2 💬 1 📌 0
Sandra Gómez Canaval
Ingeniera y Doctora en Informática
Máster en Ingeniería del Software
Profesora de la ETSISI desde 2010
Candidata a Director/a de la ETSISI
29 de abril: Vota
https://votasandra.es/
AI tinkerer and protagonist. Pro-democracy. Resisting fascism. The Singularity is near.
Musician.
romance is a place
she/her
Born in Rio, living in São Paulo
Economist, city enthusiast. Nothing is better than a good movie and TV show with a glass of wine
Digital Intelligence Mentor empowering your success. Amplify your human intelligence with AI.
UX / UI Designer
Crafting Captivating User Experiences with passion.
Search Engineer, LLM whisperer, Local First curious
Historian 🗃️ | US Civil War era, History of Medicine | My book *Opium Slavery: Civil War Veterans and America’s First Opioid Crisis* is now out from UNC Press, tinyurl.com/opiumslavery) | proud #firstgen | jonathansjones.net
👱🏻♀️Taylor Swift. ✈️Traveling. 👨🏼🍳Baking. 🖥️Nerd. 🏳️🌈Gay.
Me educaron libre y cuestionando todo.
Hago robots y chocolate.
Ingeniero, jurista y chocolatero.
https://piol.in/javi

















