
What if the way we verify synthetic code is limiting model performance?
In our latest work we uncover the Verification Ceiling Problem: strict “all tests must pass” rules throw away useful data, while weak tests let errors through.

@mziizm.bsky.social
seeks to understand language. Head of Cohere Labs @Cohere_Labs @Cohere PhD from @UvA_Amsterdam https://marziehf.github.io/
What if the way we verify synthetic code is limiting model performance?
In our latest work we uncover the Verification Ceiling Problem: strict “all tests must pass” rules throw away useful data, while weak tests let errors through.

We’re not your average lab. We’re a hybrid research environment dedicated to revolutionizing the ML space.
And we’re hiring a Senior Research Scientist to co-create with us.
If you believe in research as a shared, global effort — this is your chance.
At its core, @cohereforai.bsky.social is about advancing open science, exploring fundamental research questions, and sharing knowledge broadly
always guided by the pleasure of finding things out.
Excited for what’s next!
Very grateful to @sarahooker.bsky.social for shaping the lab into what it is today, and looking forward to working with Joelle whose guidance will be invaluable as we write our next chapter. Also big thanks to @nickfrosst.bsky.social
and @aidangomez.bsky.social Ivan for their support and trust.

I'm excited to share that I'll be stepping into the role of Head of @cohereforai.bsky.social. It's an honor and a responsibility to lead such an extraordinary group of researchers pushing the boundaries of AI research.
05.09.2025 17:26 — 👍 11 🔁 2 💬 1 📌 0
While effective for chess♟️, Elo ratings struggle with LLM evaluation due to volatility and transitivity issues.
New post in collaboration with AI Singapore explores why Elo falls short for AI leaderboards and how we can do better.

If you've been waiting for your moment to step into research, this could be it.
cohere.com/research/sch...
Over the years, I've watched scholars go from their very first project → to their first paper → to research careers they once thought were out of reach.
It’s been incredible to see what can happen when someone gets their first real chance and works hard to make it count 🏅
Breaking into AI research is harder than ever, and early-career researchers face fewer chances to get started.
Entry points matter.
We started the Scholars Program 3 years ago to give new researchers a real shot — excited to open applications for year 4✨

🌍 Language shapes how we think and connect—but most AI models still struggle beyond English.
@microsoft.com's July seminar discussed how we can bridge the gap and build #AIforEveryone with @mziizm.bsky.social of @cohere.com.
📽️ www.microsoft.com/en-us/resear...

ACL day 2 ✨
29.07.2025 06:55 — 👍 1 🔁 0 💬 0 📌 0There’s so much open space here: how to better integrate language nuances, how to curate and align cross-modal data well, how to go beyond six languages.
Excited to keep exploring it and even more excited to see what the community builds on top of this 💫
Huge kudos to my collaborators: @mmderakhshani.bsky.social Dheeraj Varghese @cgmsnoek.bsky.social 🙌
We’re releasing the model, data, and evals soon to help make multilingual image generation more robust, inclusive, and reproducible.
neobabel.github.io
arxiv.org/abs/2507.061...

One of my favorite parts of NeoBabel is multilingual inpainting & extrapolation: you can mask part of an image generated in language A, prompt it in language B, and it fills in the scene naturally—no special tuning needed.
09.07.2025 13:27 — 👍 0 🔁 0 💬 1 📌 0
We used a multistage training setup: starting from class-label grounding, then scaling up to massive multilingual image-text pairs, and finally instruction tuning with high-res, diverse prompts.
This helped the model gradually learn structure, language, and fine-grained control.

We put a lot of effort into building a clean, well-aligned multilingual dataset (124M image-text pairs across 6 languages) and it paid off.
NeoBabel generates well in every language. And it’s only 2B params—beating much larger models on benchmarks.

This was my first project in image generation, and coming from language I was shocked at how little care is given to text quality in many vision datasets.
Captions are often noisy, shallow, or poorly formatted.

🖼️ Most text-to-image models only really work in English.
This limits who can use them and whose imagination they reflect.
We asked: can we build a small, efficient model that understands prompts in multiple languages natively?

Everyone talks about GEB (I agree, it's a gem) but Hofstadter's Analogy book is criminally underrated. If you're working on learning intelligence through language understanding, it’s a must-read.
29.06.2025 10:11 — 👍 4 🔁 0 💬 0 📌 0🍋 Squeezing the most of few samples - check out our LLMonade recipe for few-sample test-time scaling in multitask environments.
Turns out that standard methods miss out on gains on non-English languages. We propose more robust alternatives.
Very proud of this work that our scholar Ammar led! 🚀

London has me under its spell. every. single. visit.
09.06.2025 17:47 — 👍 3 🔁 0 💬 1 📌 0🚨LLM safety research needs to be at least as multilingual as our models.
What's the current stage and how to progress from here?
This work led by @yongzx.bsky.social has answers! 👇
I guess your next challenge is making veo-baby as cute as your actual baby 😍
28.05.2025 20:13 — 👍 1 🔁 0 💬 0 📌 0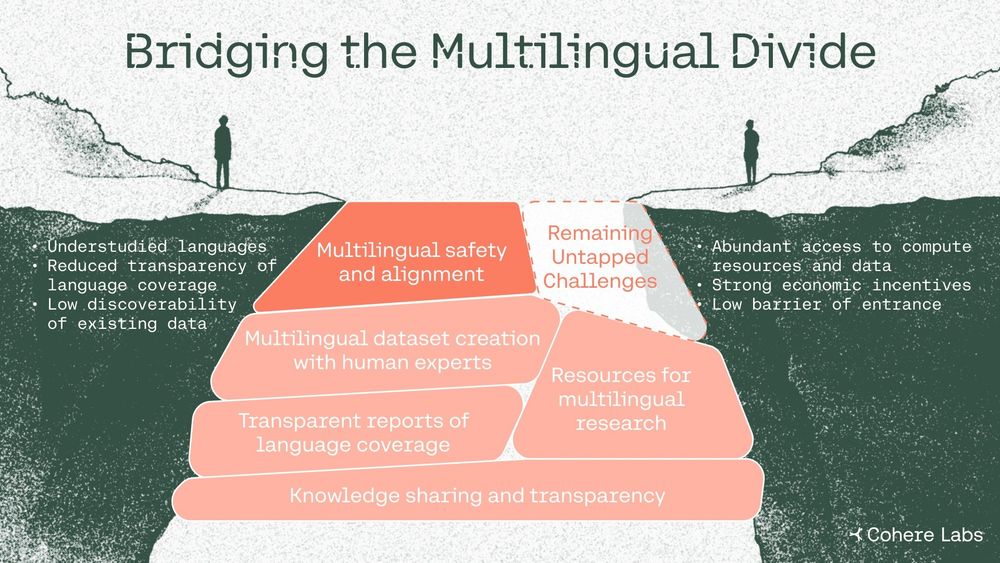
Over 7000 languages are spoken worldwide 🌐, but AI safety efforts focus on only a fraction of them.
Our latest paper draws on our multi-year efforts with the wider research community to explore why this matters and how we can bridge the AI language gap.
📢 The Copenhagen NLP Symposium on June 20th!
- Invited talks by @loubnabnl.hf.co (HF) @mziizm.bsky.social (Cohere) @najoung.bsky.social (BU) @kylelo.bsky.social (AI2) Yohei Oseki (UTokyo)
- Exciting posters by other participants
Register to attend and/or present your poster at cphnlp.github.io /1
again leading to disproportionate access to human annotations.
01.05.2025 10:21 — 👍 1 🔁 0 💬 0 📌 0The numbers in this chart are the number of prompts (according to the public number of battles each model provider participates in). Providers can ask for 20% of this data in full format (both their and the opponent's names, generations, and the human votes).
01.05.2025 10:19 — 👍 1 🔁 0 💬 1 📌 0
It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
Goodhart's law rules everything around me.
30.04.2025 08:54 — 👍 18 🔁 4 💬 0 📌 010/ This work involved months of careful analysis.
We encourage everyone to read the full paper (all 68 pages, I know!) and welcome any feedback or corrections.

















