How many versions of the Iowa Gambling Task (IGT) exist? And how much does this affect research using the IGT? More than you might think. 🧵
25.01.2026 11:16 —
👍 95
🔁 44
💬 3
📌 6

Fig. 3. Scatter plots of the synthetic and empirical estimates, validation study (Stage 2). Showing N = 30,135 item-pair correlations, N = 257 scale reliabilities, and N = 1,568 scale-pair correlations for (top) the pretrained SBERT model and (bottom) the fine-tuned SurveyBot3000 model. SBERT = all-mpnet-base-v2 model.

Fig. 4. Prediction error of the synthetic estimates, validation study (Stage 2). Our prediction model allowed the error term to vary freely according to the predictor, the synthetic estimate. The thin-plate splines show that some synthetic estimates were predictably more accurate.

Fig. 5. Accuracy by domain. Accuracy differed across domains. SurveyBot3000 accuracy (colored) was always higher than SBERT accuracy (gray). Results were largely consistent whether accuracy of items was tested (left, circle) within domains or (right, cross) across domains.
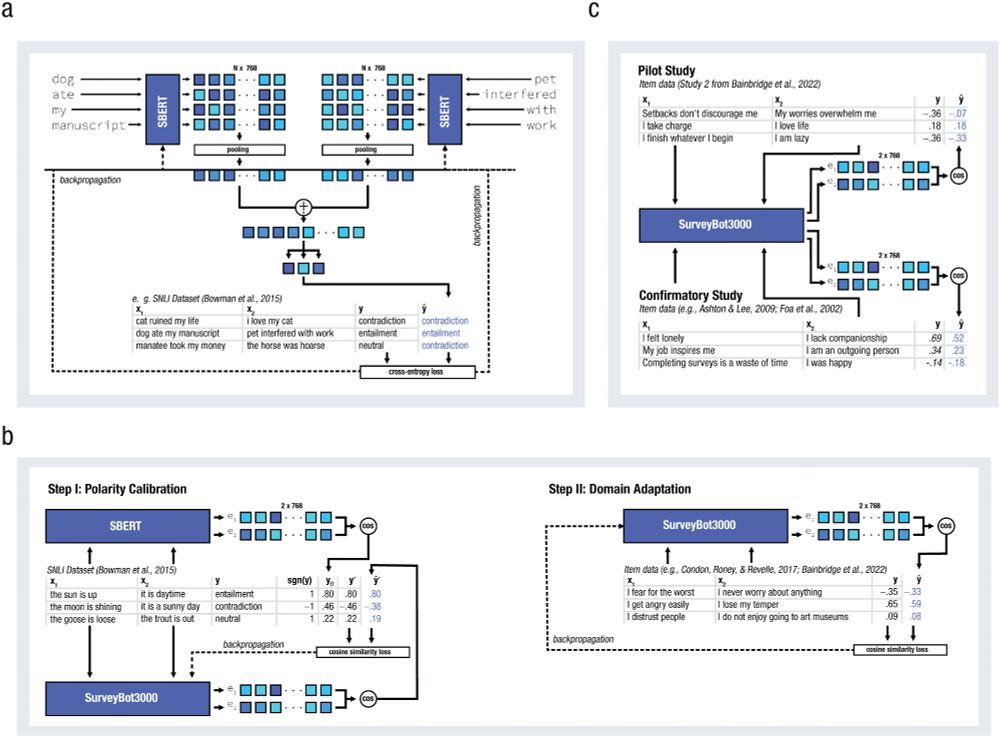
Fig. 1. Multistep training procedure for the SurveyBot3000, which produces synthetic estimates of interitem correlations. (a) Pretraining base model (SBERT). (b) Fine-tuning SurveyBot3000. (c) Validation. SBERT = all-mpnet-base-v2 model.
Finally, @bjoernhommel.bsky.social's and my paper introducing the SurveyBot3000 is officially out in AMPPS. It's a fine-tuned language model that guesstimates correlations between survey items from text alone. Not perfectly, but useful for search, for example.
journals.sagepub.com/doi/10.1177/...
18.12.2025 20:20 —
👍 81
🔁 33
💬 2
📌 6

‘A fragmented field: Construct and measure proliferation in psychology.’ (2025)

From ‘Language models accurately infer correlations between psychological items and scales from text alone.’ (2025)

From ‘Not within spitting distance: salivary immunoassays of estradiol have subpar validity for predicting cycle phase.’ (2023)

Work in progress with cycle tracking data from the app Clue
Want to make nice graphs with me, starting next year? I'm hiring for a position at the University of Witten/Herdecke.
uni-wh.softgarden.io/job/61280592...
03.12.2025 12:48 —
👍 59
🔁 52
💬 2
📌 4
Keeping SynthNet up to date is super important, and adding missing scales is definitely part of the plan. We’re currently building a data-donation platform, so researchers can contribute their own measures. It’s a top priority:)
28.11.2025 13:31 —
👍 3
🔁 0
💬 0
📌 0
OSF
📄 Preprint: osf.io/preprints/ps...
26.11.2025 11:42 —
👍 5
🔁 0
💬 1
📌 0
Solution: Survey items are text, so we use natural language processing to approximate empirical overlap between scales. SynthNet is powered by SurveyBot3000, a sentence transformer we developed to predict correlations from item wording alone. Scale-level accuracy against empirical data: r=.84. 🧵3/3
26.11.2025 11:42 —
👍 6
🔁 0
💬 1
📌 0
Problem: The measurement ecosystem in behavioral science is disorganized. Inconsistent labeling leads to jingle-jangle fallacies. Proving redundancy empirically requires pairwise comparisons. With hundreds of thousands of items, that means trillions of responses. Not feasible! 🧵2/3
26.11.2025 11:42 —
👍 6
🔁 1
💬 1
📌 0
🚨 SynthNet is out 🚨
Researchers propose new constructs and measures faster than anyone can track. We (@anniria.bsky.social @ruben.the100.ci) built a search engine to check what already exists and help identify redundancies; indexing 74,000 scales from ~31,500 instruments in APA PsycTests. 🧵1/3
26.11.2025 11:42 —
👍 158
🔁 86
💬 3
📌 3
Synthetic Correlations - a Hugging Face Space by magnolia-psychometrics
Discover amazing ML apps made by the community
One position is DFG-funded (75%, 3 years). Topic: Can LLMs help us defragment psychology? It builds on the SurveyBot3000 huggingface.co/spaces/magno...
You'll get to collaborate with @bjoernhommel.bsky.social, @jamiecummins.bsky.social, @malte.the100.ci and a mystery cool person.
18.03.2025 15:31 —
👍 14
🔁 5
💬 1
📌 0
Check out RegCheck, the latest research tool by the lab, headed by @jamiecummins.bsky.social: Automatically compare preregistrations with papers and reports deviations.
We might be hiring a postdoc to work on this full time nexyct year, so if this flips your pancake, please get in touch!
23.07.2024 17:15 —
👍 13
🔁 7
💬 0
📌 0

Predict survey response patterns (item & scale correlations + reliability) based on nothing but item text! Try our HuggingFace App huggingface.co/spaces/magno... accompanying @ruben.the100.ci
and my latest research #huggingface #llm #ai #psychometrics
22.04.2024 16:40 —
👍 6
🔁 0
💬 0
📌 1


