
Transcript of Hard Fork ep 111: Yeah. And I could talk for an hour about transformers and why they are so important.
But I think it's important to say that they were inspired by the alien language in the film Arrival, which had just recently come out.
And a group of researchers at Google, one researcher in particular, who was part of that original team, was inspired by watching Arrival and seeing that the aliens in the movie had this language which represented entire sentences with a single symbol. And they thought, hey, what if we did that inside of a neural network? So rather than processing all of the inputs that you would give to one of these systems one word at a time, you could have this thing called an attention mechanism, which paid attention to all of it simultaneously.
That would allow you to process much more information much faster. And that insight sparked the creation of the transformer, which led to all the stuff we see in Al today.
Did you know that attention across the whole input span was inspired by the time-negating alien language in Arrival? Crazy anecdote from the latest Hard Fork podcast (by @kevinroose.com and @caseynewton.bsky.social). HT nwbrownboi on Threads for the lead.
01.12.2024 14:50 —
👍 247
🔁 53
💬 19
📌 17
https://huggingface.co/openlm-research
All model checkpoints we used for this research are also available here: t.co/IlSmJ8Na1i
26.11.2024 22:37 —
👍 2
🔁 0
💬 0
📌 0
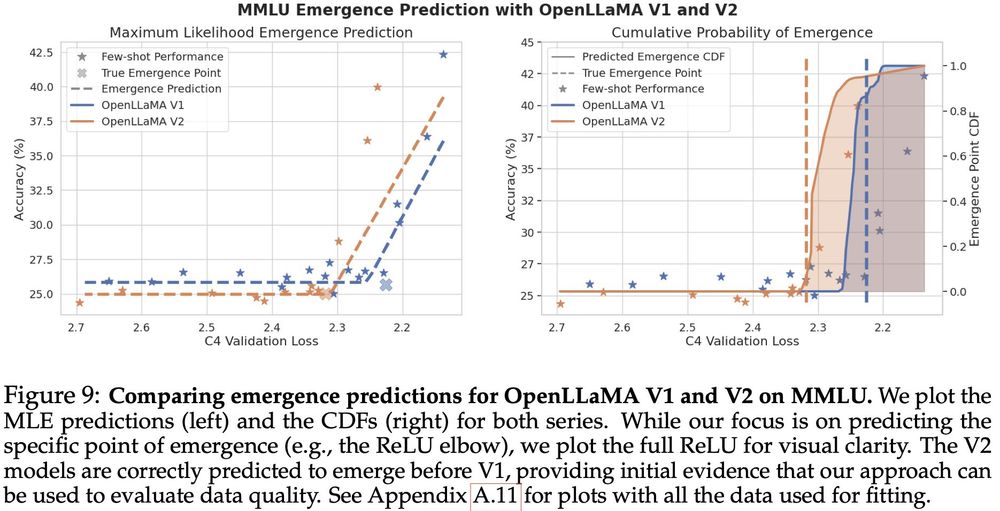

Finally, we present a case study of two real world uses for emergence prediction:
1) cheaply assessing pretraining data quality (left).
2) predicting more complex capabilities, closer to those of future frontier models, using the difficult APPS coding benchmark (right).
26.11.2024 22:37 —
👍 5
🔁 0
💬 1
📌 0
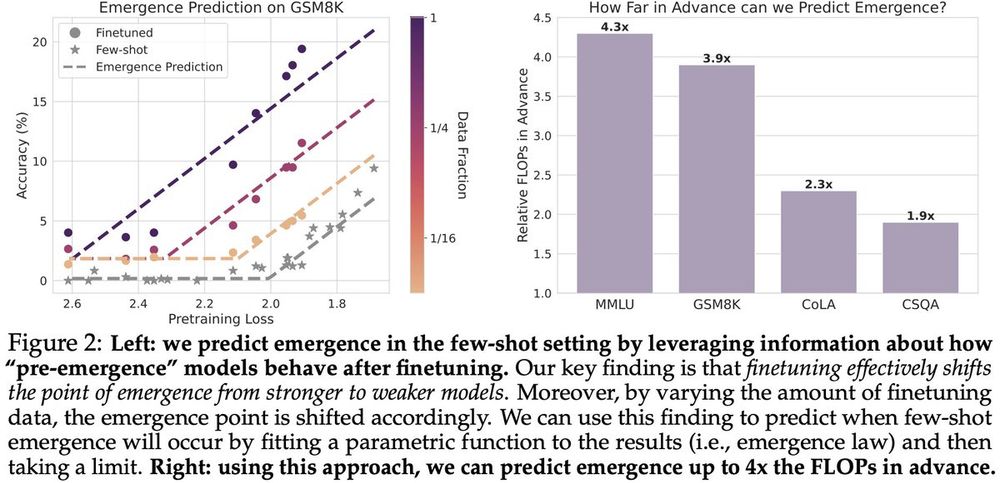
We validate our emergence law using four standard NLP benchmarks where large-scale open-source LLMs already demonstrate emergence, so we can easily check our predictions.
We find that our emergence law can accurately predict the point of emergence up to 4x the FLOPs in advance.
26.11.2024 22:37 —
👍 3
🔁 0
💬 1
📌 0
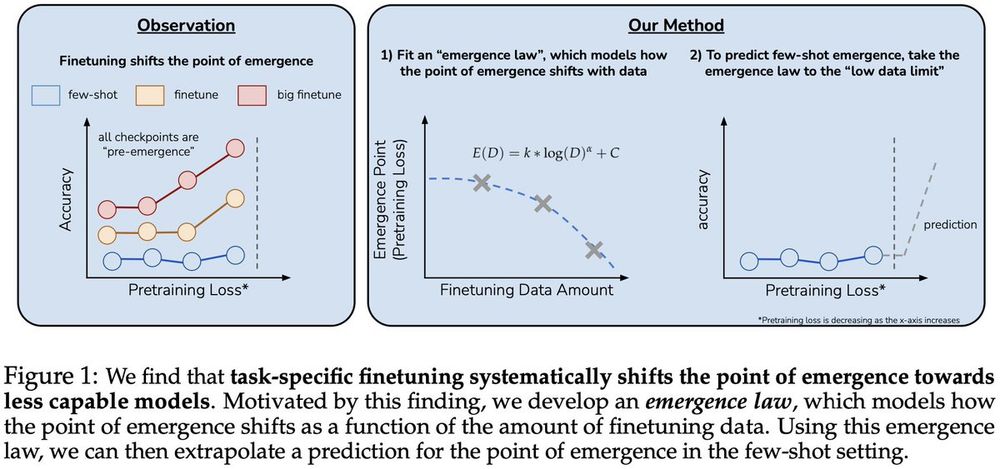
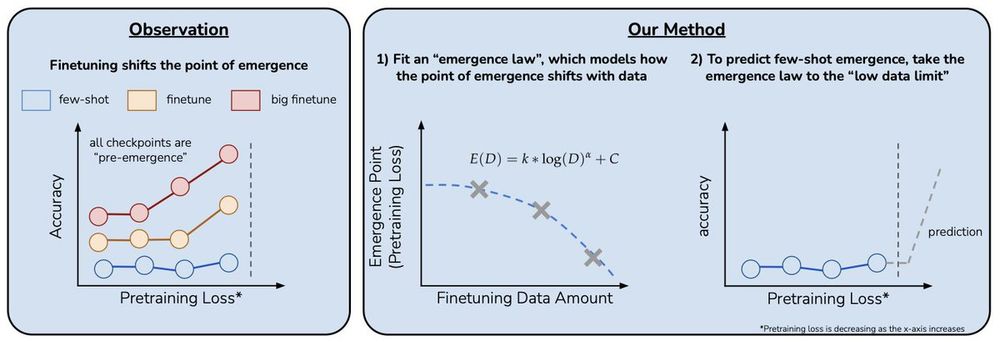
To operationalize this insight, we finetune LLMs on varying amounts of data and fit a parametric function (i.e., “emergence law”) which models how the point of emergence shifts with the amount of data. We can then extrapolate a prediction for emergence in the few-shot setting.
26.11.2024 22:37 —
👍 3
🔁 0
💬 1
📌 0
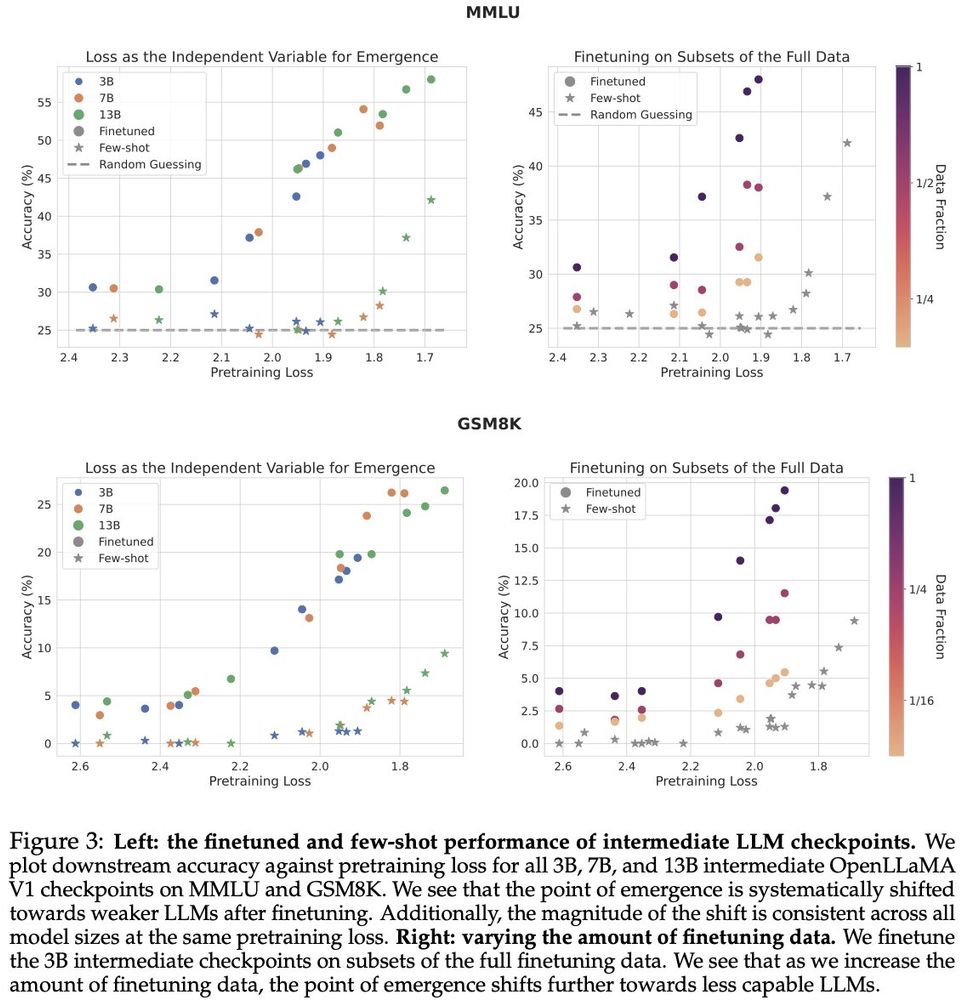
We then discover a simple insight for this problem:
finetuning LLMs on a given task can shift the point in scaling at which emergence occurs towards less capable LLMs, and the magnitude of this shift is modulated by the amount of finetuning data.
26.11.2024 22:37 —
👍 3
🔁 0
💬 1
📌 0
We first pose the task of emergence prediction:
given access to LLMs that have random few-shot accuracy on a task, can we predict the point in scaling (e.g., pretraining loss) at which performance will jump up beyond random-chance?
26.11.2024 22:37 —
👍 5
🔁 0
💬 1
📌 0
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
26.11.2024 22:37 —
👍 45
🔁 6
💬 3
📌 1

