Paper: arxiv.org/abs/2501.13824
24.01.2025 13:56 — 👍 1 🔁 1 💬 0 📌 0
@eos.bsky.social
Building with AI agents • Prev: Meta AI, Elastic, Galactica LLM, PhD • Prompting Guide (~6M+ learners) • I also teach how to build with AI: https://dair-ai.thinkific.com/
Paper: arxiv.org/abs/2501.13824
24.01.2025 13:56 — 👍 1 🔁 1 💬 0 📌 0In addition, hallucinations generated by GPT-4o provide the most consistent improvements across models.
24.01.2025 13:56 — 👍 0 🔁 0 💬 1 📌 0A new paper claims that LLMs can achieve better performance in drug discovery tasks with text hallucinations compared to input prompts without hallucination.
Llama-3.1-8B achieves an 18.35% gain in ROC-AUC compared to the baseline without hallucination.

Hallucinations are generally bad for real-world LLM applications.
Folks like Karpathy have suggested that hallucination is an LLM's greatest feature.
Is there any evidence for the latter?

Google recently published this great whitepaper on Agents.
2025 is a huge year for AI Agents.
Here's what's included:
- Introduction to AI Agents
- The role of tools in Agents
- Enhancing model performance
- Quick start to Agents with LangChain
- Production applications with Vertex AI Agents
paper: arxiv.org/abs/2412.20512
06.01.2025 14:18 — 👍 1 🔁 0 💬 0 📌 0
Dive into Time-Series Anomaly Detection: A Decade Review
Provides a survey of time-series anomaly detection solutions.
- metrics to assess the efficiency of o1-like models
- several strategies to tackle overthinking and reduce token generation
Very informative paper.
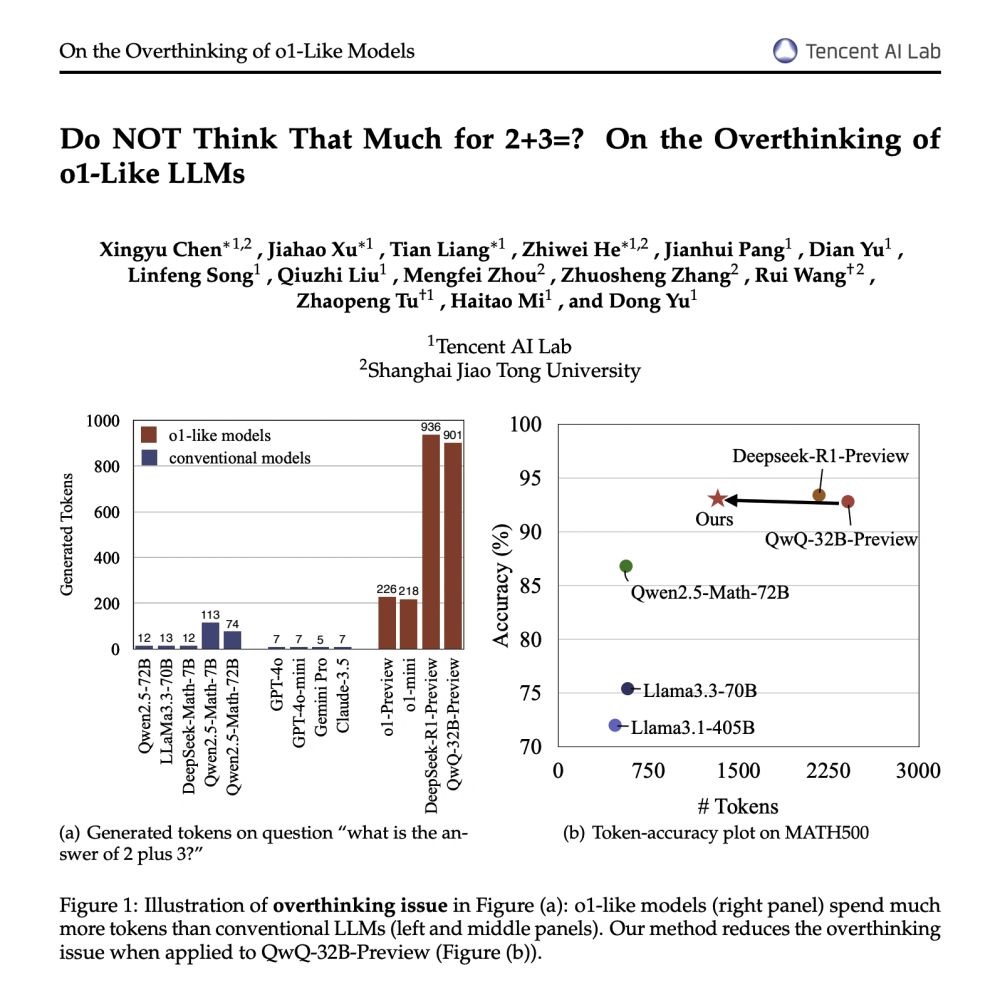
Proposes a self-training strategy to mitigate overthinking in o1-like LLMs.
This approach can reduce token output by 48.6% while maintaining accuracy on the widely-used MATH500 test set as applied to QwQ-32B-Preview.
There are three parts to this study:
- analysis of the overthinking issue
www.rwkv.com/
02.01.2025 15:15 — 👍 0 🔁 0 💬 0 📌 0
Just came across this interesting project.
RWKV combines the best of RNN and transformers.
There is code for training your own model, fine-tuning, GUI, API, fast WebGPU inference, and more.
Cool project!
• 🌍 Flexible Environment Configuration: Define custom environments with YAML configuration files
• 🛠️ Extensible Architecture: Easy to extend and customize for your specific needs
• 🔄 Robust Interaction Management: Coordinate complex interactions between agents
• 💾 Checkpoint System: Save and restore agent states and interactions
• 📊 Data Generation: Generate synthetic data through agent interactions
• ⚡ Performance Optimized: Built for efficiency and scalability

Agentarium is a new Python framework for managing and orchestrating AI agents.
Features include (from the repo):
• 🤖 Advanced Agent Management: Create and orchestrate multiple AI agents with different roles and capabilities

A Survey of Mathematical Reasoning in the Era of Multimodal LLMs
arxiv.org/abs/2412.11936
more here --> mixedbit.org/blog/2024/1...
17.12.2024 14:24 — 👍 0 🔁 0 💬 0 📌 0
Nice use case of Gemini
17.12.2024 14:24 — 👍 1 🔁 0 💬 1 📌 0more here: andrewkchan.dev/posts/yalm....
16.12.2024 15:10 — 👍 0 🔁 0 💬 0 📌 0
This is worth looking at.
16.12.2024 15:10 — 👍 1 🔁 0 💬 1 📌 0www.souzatharsis.com/tamingLLMs/...
13.12.2024 15:20 — 👍 0 🔁 0 💬 0 📌 0
Very exciting guide on working with LLMs.
A few chapters have been made available already like structured output and evals. More to come soon!
The authors claim that "With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space."
arxiv.org/abs/2412.07724

IBM open-sources Granite Guardian, a suite of safeguards for risk detection in LLMs.
11.12.2024 14:28 — 👍 5 🔁 1 💬 1 📌 0arxiv.org/abs/2412.05579
10.12.2024 17:52 — 👍 0 🔁 0 💬 0 📌 0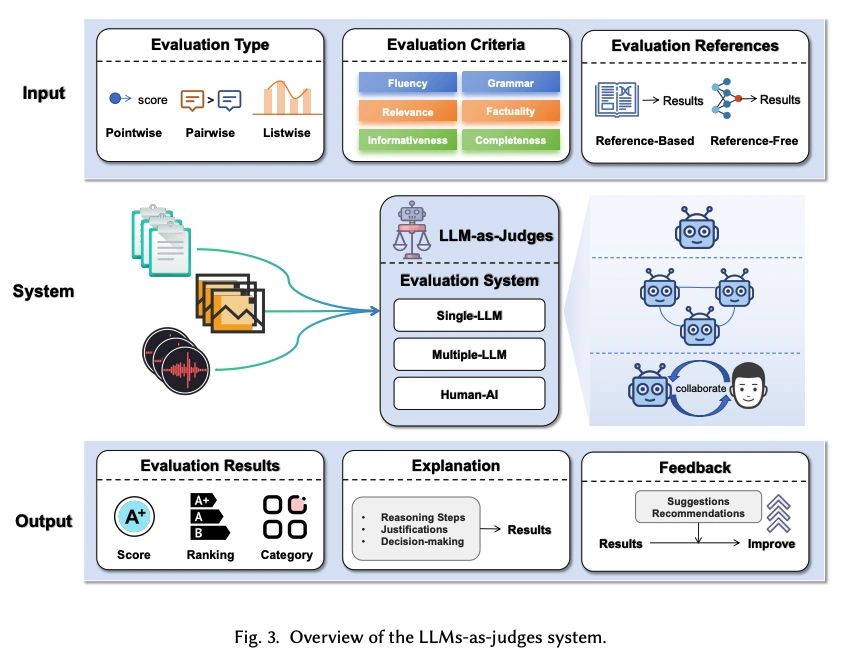
A Survey on LLMs-as-Judges
Presents a comprehensive survey of the LLMs-as-judges paradigm from five key perspectives: Functionality, Methodology, Applications, Meta-evaluation, and Limitations.
Reports that the generated synthetic data can improve agent performance on actual customer queries.
Finds that for trajectory verification "simple ML baselines with feature engineering can match the performance of more expensive and capable models."
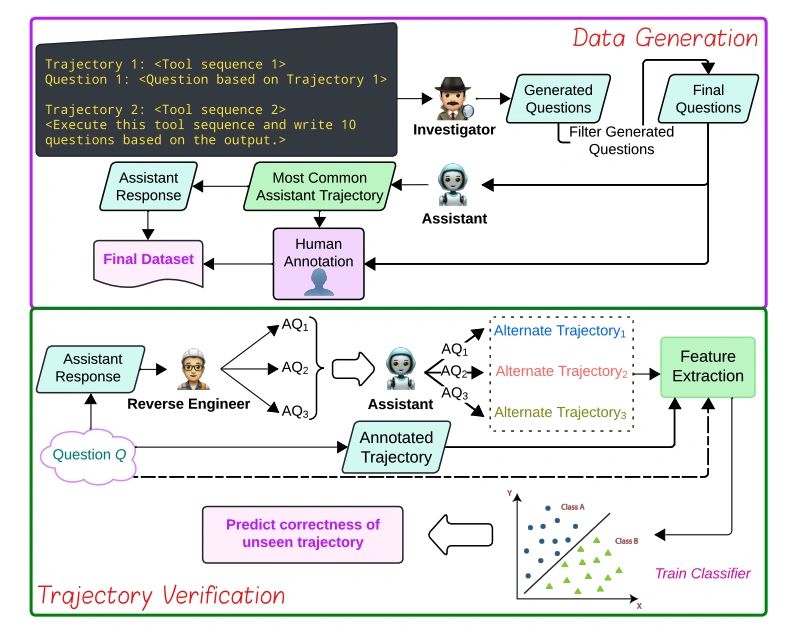
A Multi-Agent Framework for Synthetic Data Generation
Presents MAG-V, a multi-agent framework that first generates a dataset of questions that mimic customer queries. It then reverse engineer alternate questions from responses to verify agent trajectories.
arxiv.org/abs/2412.04494
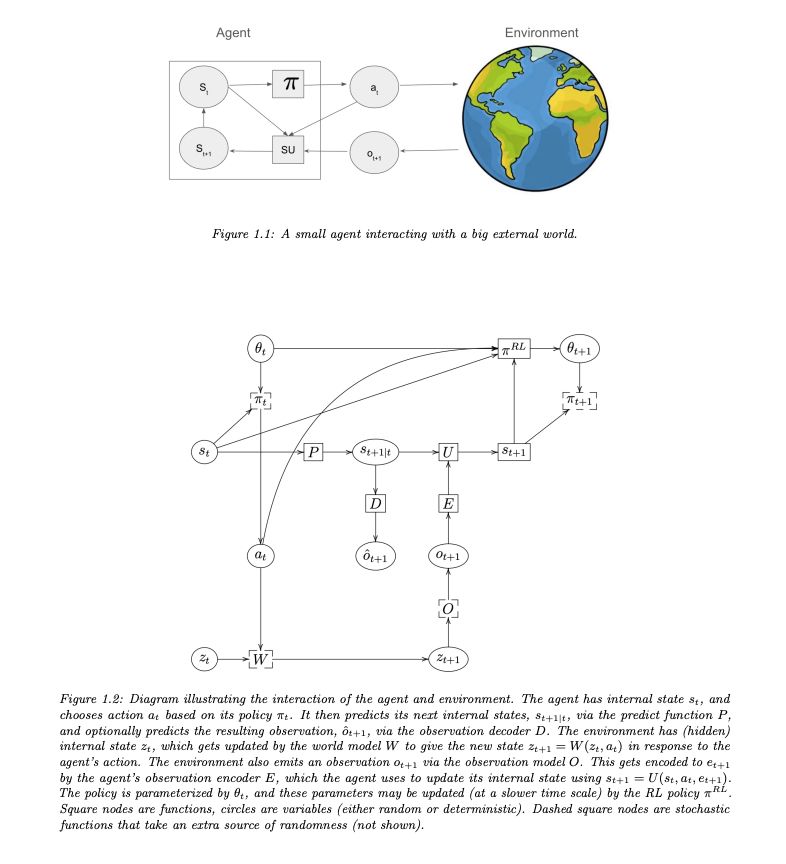
Reinforcement Learning: An Overview
This gem just dropped on arXiv.
An up-to-date overview of reinforcement learning and sequential decision-making.
arxiv.org/abs/2412.05265