We performed a similar amount of elicitation as with other frontier models. However, our usual scaffolds weren’t purpose-built to elicit performance from the Grok model family specifically, so it’s possible that performance could be even higher with a different scaffold.
31.07.2025 02:12 — 👍 1 🔁 0 💬 1 📌 0
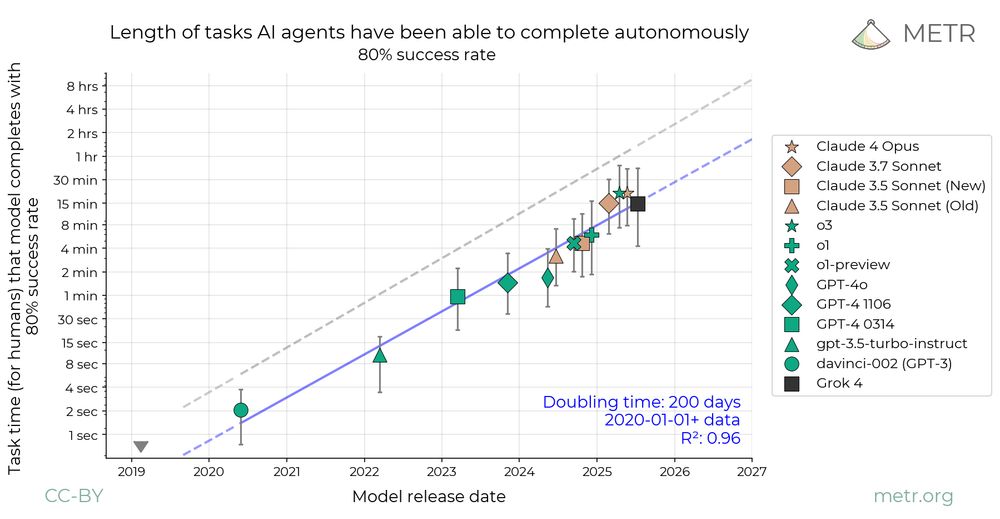
Grok 4’s 50%-time-horizon is slightly above o3, but not by a statistically significant margin – it reaches a higher 50%-time-horizon than o3 in about 3/4 of our bootstrap samples. Additionally, Grok 4’s 80%-time-horizon is lower than that of o3 and Claude Opus 4.
31.07.2025 02:12 — 👍 1 🔁 0 💬 1 📌 0
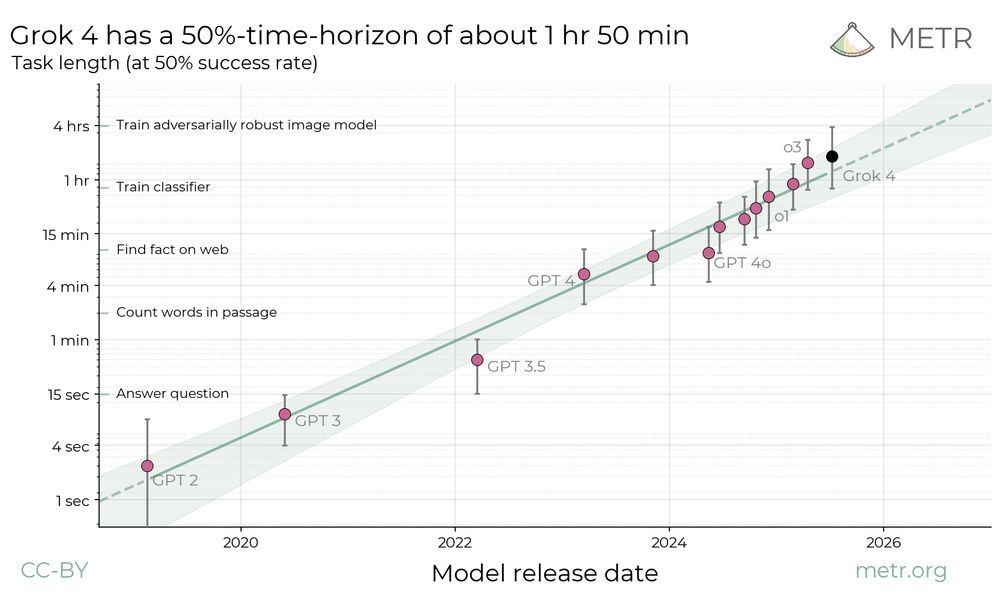
We found that Grok 4’s 50%-time-horizon on our agentic multi-step software engineering tasks is about 1hr 50min (with a 95% CI of 48min to 3hr 52min) compared to o3 (previous SOTA) at about 1hr 30min. However, Grok 4’s time horizon is below SOTA at higher success rate thresholds.
31.07.2025 02:12 — 👍 4 🔁 0 💬 1 📌 0
We have open-sourced anonymized data and core analysis code for our developer productivity RCT.
The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.
30.07.2025 20:10 — 👍 28 🔁 8 💬 1 📌 0
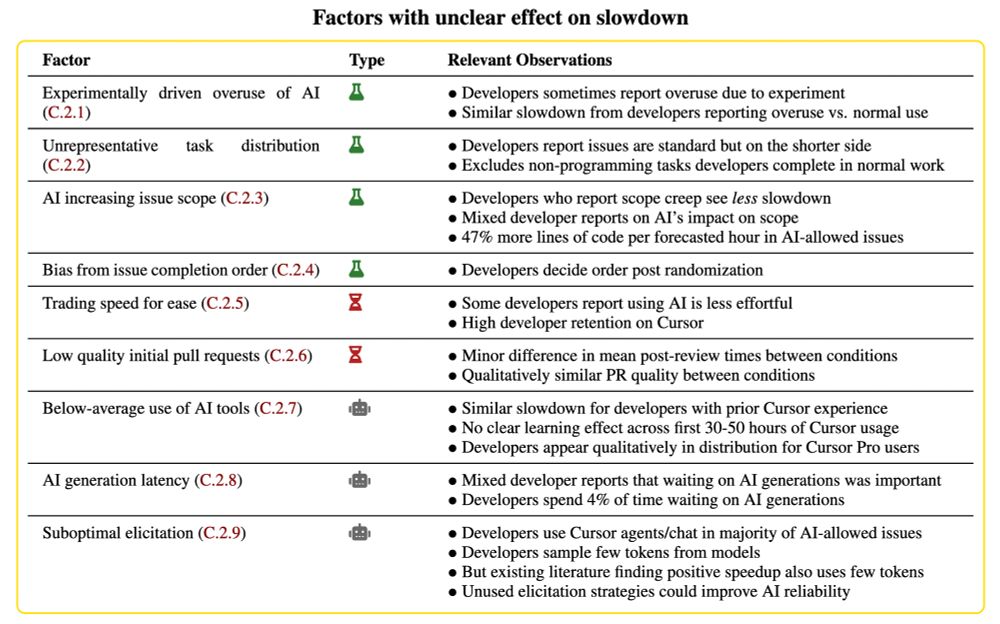
Other limitations: Many of the task distributions we analyzed have the limitations of benchmarks in general, e.g. being easily verifiable, contained, and not requiring human or multi-agent interaction.
14.07.2025 18:21 — 👍 0 🔁 0 💬 1 📌 0
Because we didn’t run these evals ourselves and had to estimate human time (and sometimes other key parameters), these are necessarily rougher estimates of time horizon than our work on HCAST, RE-Bench, and SWAA. GPQA Diamond is an exception, thanks to @epochai.bsky.social data.
14.07.2025 18:21 — 👍 0 🔁 0 💬 1 📌 0
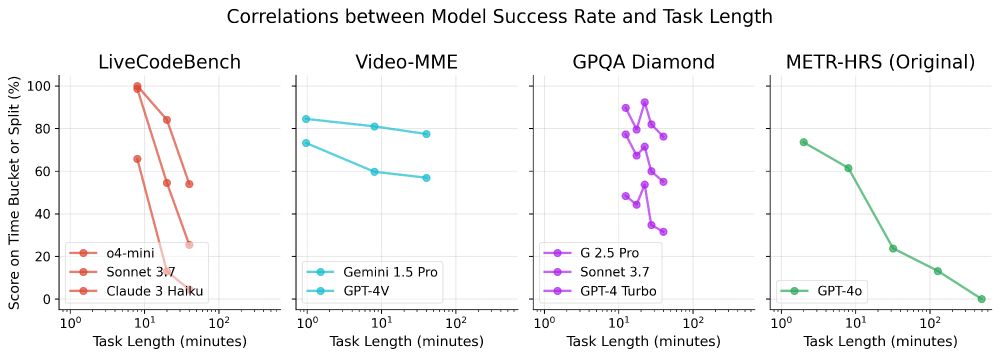
Time horizon isn’t relevant on all benchmarks. Hard LeetCode problems (LiveCodeBench) and math problems (AIME) are much harder for models than easy ones, but Video-MME questions on long videos aren’t much harder than on short ones.
14.07.2025 18:21 — 👍 0 🔁 0 💬 1 📌 0
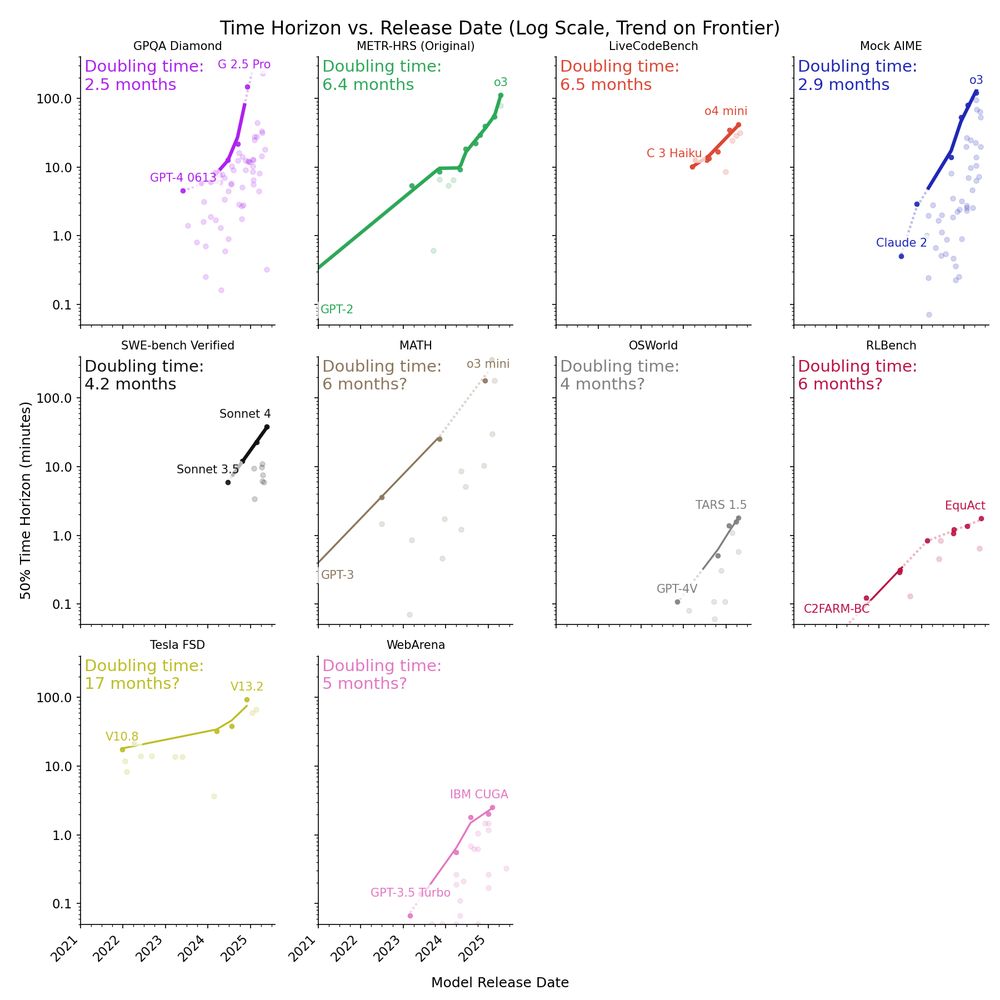
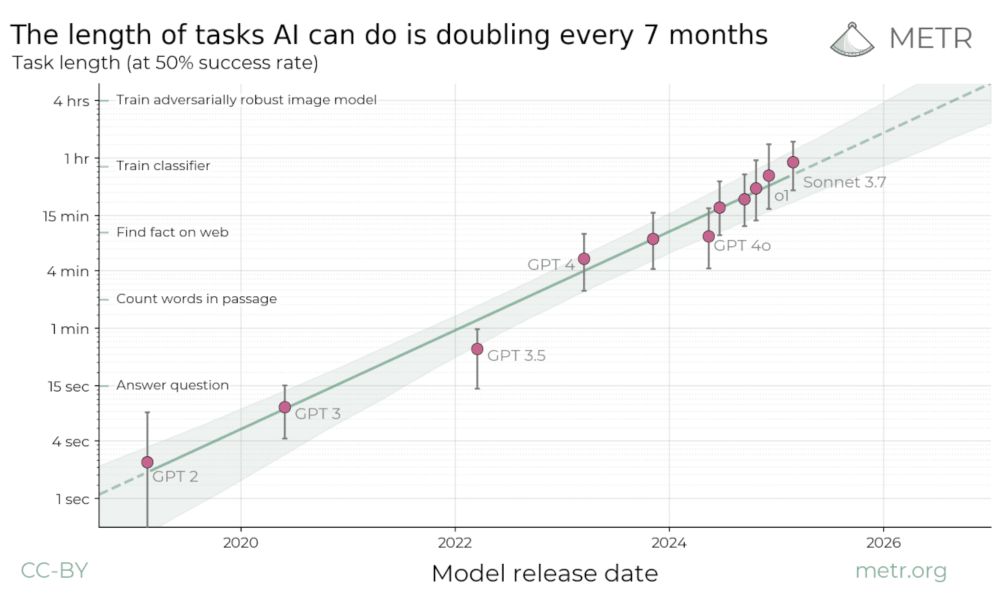
Since the release of the original report, new frontier models like o3 have been above trend on METR’s tasks, suggesting a doubling time faster than 7 months.
The median doubling time across 9 benchmarks is ~4 months (range is 2.5 - 17 months).
14.07.2025 18:21 — 👍 0 🔁 0 💬 1 📌 0
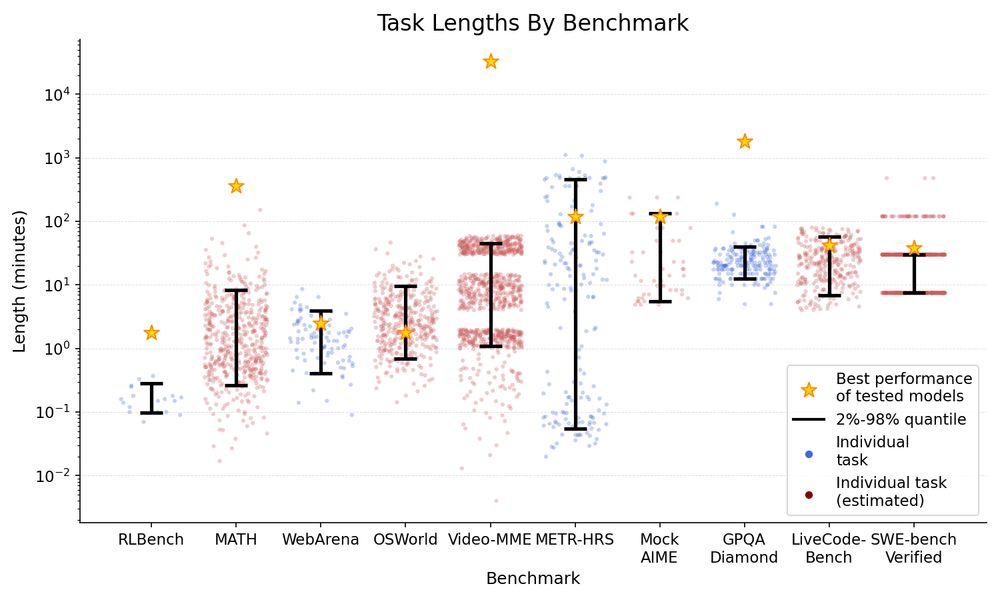
The frontier time horizon on different benchmarks differs by >100x. Many reasoning and coding benchmarks cluster at or above 1 hour, but agentic computer use (OSWorld, WebArena) is only ~2 minutes, possibly due to poor tooling.
14.07.2025 18:21 — 👍 0 🔁 0 💬 1 📌 0
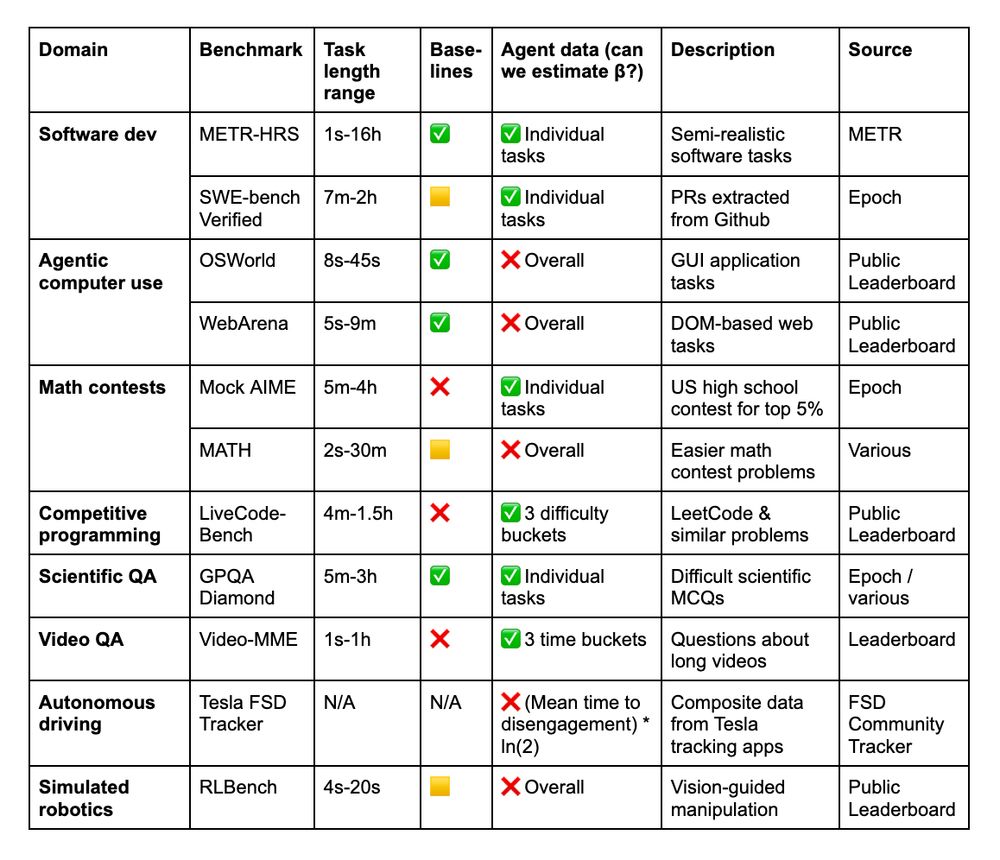
We analyze data from 9 existing benchmarks: MATH, OSWorld, LiveCodeBench, Mock AIME, GPQA Diamond, Tesla FSD, Video-MME, RLBench, and SWE-Bench Verified, which either include human time data or allow us to estimate it.
14.07.2025 18:21 — 👍 0 🔁 0 💬 1 📌 0
METR previously estimated that the time horizon of AI agents on software tasks is doubling every 7 months.
We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.
14.07.2025 18:21 — 👍 7 🔁 4 💬 1 📌 2
METR a few months ago had two projects going in parallel: a project experimenting with AI researcher interviews to track degree of AI R&D acceleration/delegation, and this project.
When the results started coming back from this project, we put the survey-only project on ice.
11.07.2025 00:22 — 👍 19 🔁 2 💬 2 📌 0

What we're NOT saying:
1. Our setting represents all (or potentially even most) software engineering.
2. Future models won't be better (or current models can’t be used more effectively).
10.07.2025 19:46 — 👍 180 🔁 8 💬 3 📌 5
Another implication:
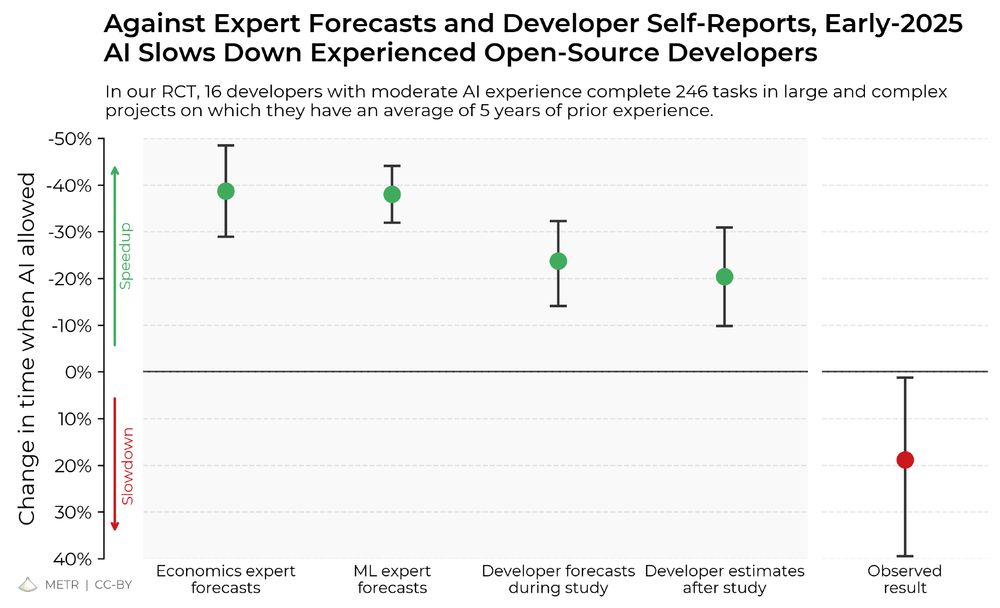
It is sometimes proposed that we should monitor AI R&D acceleration inside of frontier AI labs via simple employee surveys. We’re now more pessimistic about these, given how large of a gap we observe between developer-estimated and observed speed-up.
10.07.2025 19:46 — 👍 207 🔁 5 💬 2 📌 0
What do we take away?
1. It seems likely that for some important settings, recent AI tooling has not increased productivity (and may in fact decrease it).
2. Self-reports of speedup are unreliable—to understand AI’s impact on productivity, we need experiments in the wild.
10.07.2025 19:46 — 👍 301 🔁 41 💬 2 📌 4
Our RCT may underestimate capabilities for various reasons, and benchmarks and anecdotes may overestimate capabilities (likely some combination)—we discuss some possibilities in our accompanying blog post.
10.07.2025 19:46 — 👍 220 🔁 1 💬 3 📌 0
So how do we reconcile our results with other sources of data on AI capabilities, like impressive benchmark results, and anecdotes/widespread adoption of AI tools?
10.07.2025 19:46 — 👍 224 🔁 1 💬 2 📌 1
If we want an early warning system for whether AI R&D is being accelerated by AI itself, or even automated, it would be useful to be able to directly measure this in real-world engineer trials, rather than relying on proxies like benchmarks or even noisier information like anecdotes.
10.07.2025 19:46 — 👍 313 🔁 9 💬 1 📌 0
Why did we run this study?
AI agent benchmarks have limitations—they’re self-contained, use algorithmic scoring, and lack live human interaction. This can make it difficult to directly infer real-world impact.
10.07.2025 19:46 — 👍 366 🔁 13 💬 2 📌 1
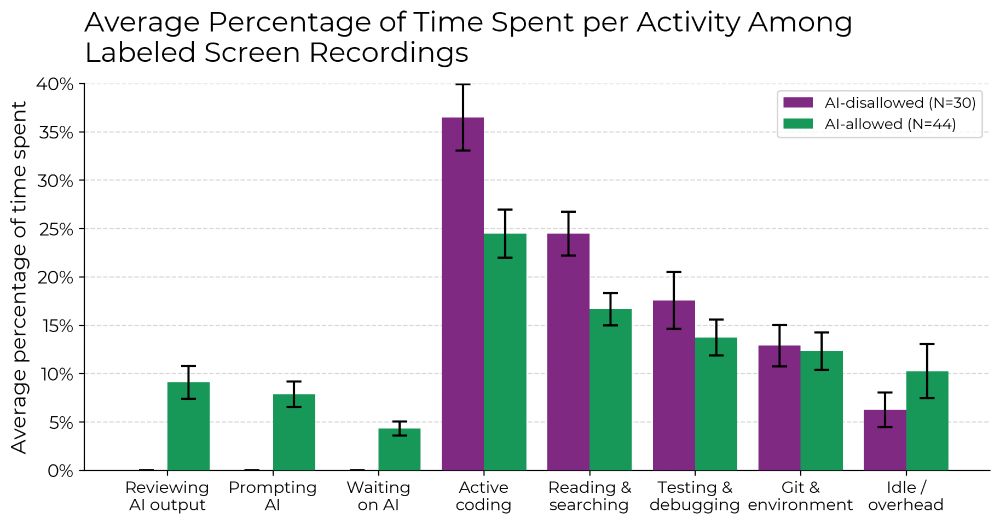
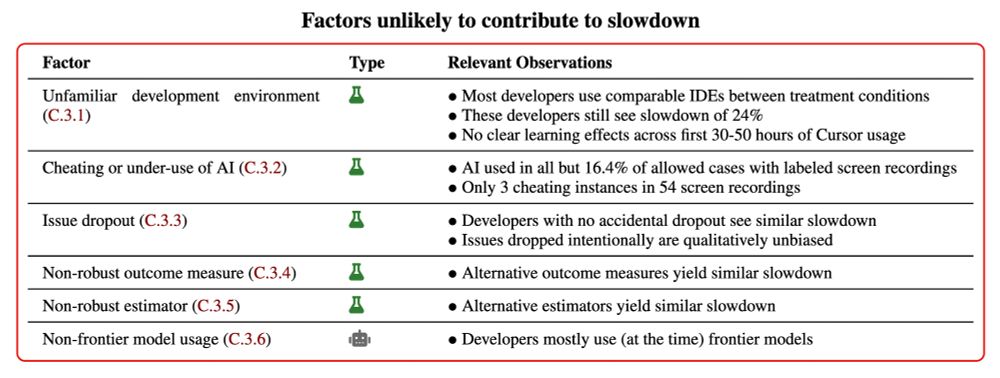
When AI is allowed, developers spend less time actively coding and searching for information, and instead spend time prompting AI, waiting on/reviewing AI outputs, and idle. We find no single reason for the slowdown—it’s driven by a combination of factors.
10.07.2025 19:46 — 👍 808 🔁 130 💬 3 📌 22
We were surprised by this, given a) impressive AI benchmark scores, b) widespread adoption of AI tooling for software development, and c) our own recent research measuring trends in the length of tasks that agents are able to complete.
10.07.2025 19:46 — 👍 426 🔁 9 💬 3 📌 1
At the beginning of the study, developers forecasted that they would get sped up by 24%. After actually doing the work, they estimated that they had been sped up by 20%. But it turned out that they were actually slowed down by 19%.
10.07.2025 19:46 — 👍 622 🔁 56 💬 3 📌 13

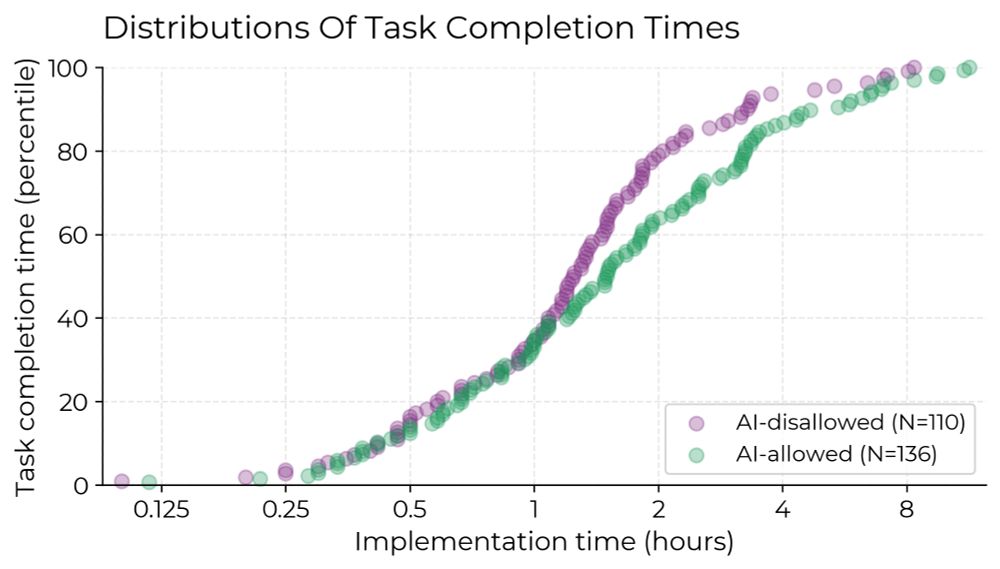
We recruited 16 experienced open-source developers to work on 246 real tasks in their own repositories (avg 22k+ stars, 1M+ lines of code).
We randomly assigned each task to either allow AI (typically Cursor Pro w/ Claude 3.5/3.7) or disallow AI help.
10.07.2025 19:46 — 👍 550 🔁 21 💬 4 📌 1
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
10.07.2025 19:46 — 👍 6895 🔁 3022 💬 112 📌 621