Andy Yang, Christopher Watson, Anton Xue, Satwik Bhattamishra, Jose Llarena, William Merrill, Emile Dos Santos Ferreira, Anej Svete, David Chiang: The Transformer Cookbook https://arxiv.org/abs/2510.00368 https://arxiv.org/pdf/2510.00368 https://arxiv.org/html/2510.00368
02.10.2025 06:33 — 👍 0 🔁 2 💬 0 📌 0

The Transformer Cookbook
We present the transformer cookbook: a collection of techniques for directly encoding algorithms into a transformer's parameters. This work addresses the steep learning curve of such endeavors, a prob...
We present The Transformer Cookbook: a collection of recipes for programming algorithms directly into transformers!
Hungry for an induction head? Craving a Dyck language recognizer? We show you step-by-step how to cook up transformers for these algorithms and many more!
03.10.2025 16:24 — 👍 5 🔁 5 💬 1 📌 0
Introducing Asta—our bold initiative to accelerate science with trustworthy, capable agents, benchmarks, & developer resources that bring clarity to the landscape of scientific AI + agents. 🧵
26.08.2025 13:05 — 👍 21 🔁 4 💬 3 📌 1

As part of Asta, our initiative to accelerate science with trustworthy AI agents, we built AstaBench—the first comprehensive benchmark to compare them. ⚖️
26.08.2025 15:02 — 👍 6 🔁 3 💬 1 📌 0
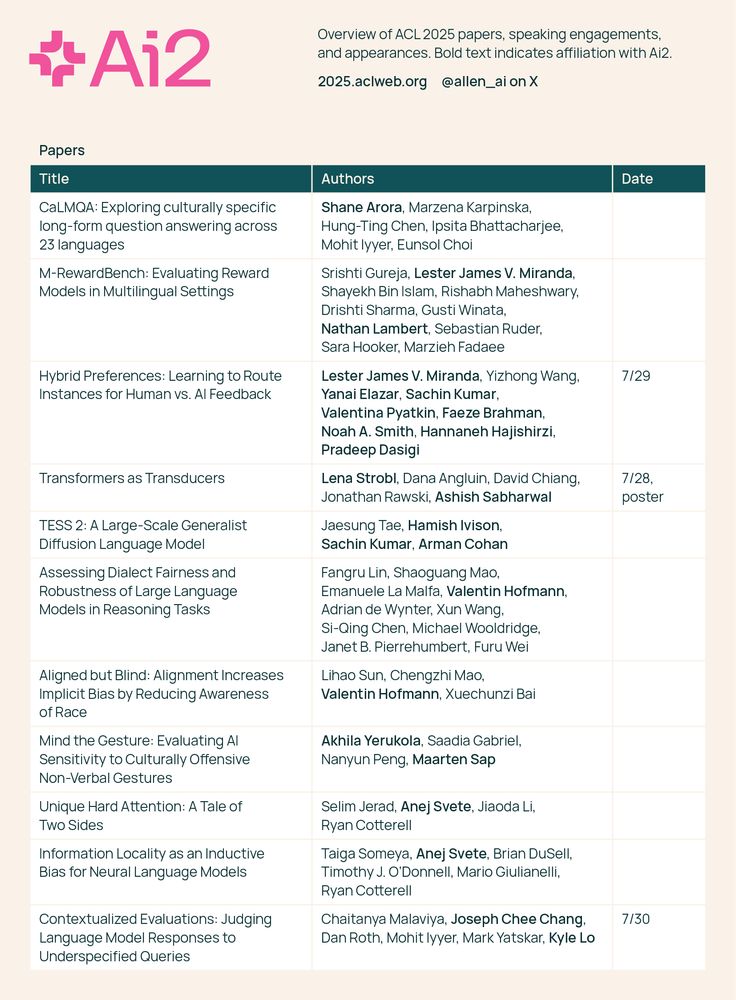

Ai2 is excited to be at #ACL2025 in Vienna, Austria this week. Come say hello, meet the team, and chat about the future of NLP. See you there! 🤝📚
28.07.2025 17:00 — 👍 9 🔁 3 💬 0 📌 0
6/ The work refines the landscape of transformer expressivity and demonstrates that seemingly minor implementation details can have major theoretical consequences for what neural architectures can represent.
17.05.2025 14:32 — 👍 0 🔁 0 💬 0 📌 0
5/ This might help explain why positional encodings that skew attention toward recent (rightmost) tokens—like ALiBi—work so well in practice. They're compensating for an inherent limitation in conventional attention mechanisms.
17.05.2025 14:32 — 👍 0 🔁 0 💬 1 📌 0
4/ Here's why this matters: leftmost-tiebreaking transformers are actually equivalent to soft-attention transformers in terms of expressivity! This suggests they might better approximate real-world transformers than right-attention models.
17.05.2025 14:32 — 👍 0 🔁 0 💬 1 📌 0
3/ Specifically, we show that leftmost tiebreaking models correspond to a strictly weaker fragment of Linear Temporal Logic (LTL). While rightmost tiebreaking enables the full power of LTL, leftmost models are limited to the "past" fragment.
17.05.2025 14:31 — 👍 0 🔁 0 💬 1 📌 0
2/ We analyzed future-masked unique hard attention transformers and found that those with leftmost tiebreaking are strictly less expressive than those with rightmost tiebreaking. The "Tale of Two Sides" nicely describes about how these two models differ.
17.05.2025 14:31 — 👍 0 🔁 0 💬 1 📌 0
1/ When multiple positions achieve the maximum attention score in a transformer, we need a tiebreaking mechanism. Should we pick the leftmost or rightmost position? Turns out, this trivial implementation detail dramatically affects what transformers can express!
17.05.2025 14:30 — 👍 0 🔁 0 💬 1 📌 0

Unique Hard Attention: A Tale of Two Sides
Understanding the expressive power of transformers has recently attracted attention, as it offers insights into their abilities and limitations. Many studies analyze unique hard attention transformers...
🧵 Excited to share our paper "Unique Hard Attention: A Tale of Two Sides" with Selim, Jiaoda, and Ryan, where we show that the way transformers break ties in attention scores has profound implications on their expressivity! And it got accepted to ACL! :)
The paper: arxiv.org/abs/2503.14615
17.05.2025 14:28 — 👍 2 🔁 1 💬 1 📌 0

Current KL estimation practices in RLHF can generate high variance and even negative values! We propose a provably better estimator that only takes a few lines of code to implement.🧵👇
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb
06.05.2025 14:59 — 👍 7 🔁 3 💬 1 📌 0
I will be at #NeurIPS2024 in Vancouver. I am excited to meet people working on AI Safety and Security. Drop a DM if you want to meet.
I will be presenting two (spotlight!) works. Come say hi to our posters.
09.12.2024 17:02 — 👍 4 🔁 1 💬 1 📌 0
No joke, FLaNN is one of the most interesting servers around. Check out the website for talk information!
flann.super.site
26.11.2024 16:04 — 👍 8 🔁 1 💬 0 📌 1

Happy to share our work "Counterfactual Generation from Language Models" with @AnejSvete, @vesteinns, and Ryan Cotterell! We tackle generating true counterfactual strings from LMs after interventions and introduce a simple algorithm for it. (1/7) arxiv.org/pdf/2411.07180
12.11.2024 16:00 — 👍 14 🔁 3 💬 2 📌 0


