
🚨 Introducing our @tmlrorg.bsky.social paper “Unlearning Sensitive Information in Multimodal LLMs: Benchmark and Attack-Defense Evaluation”
We present UnLOK-VQA, a benchmark to evaluate unlearning in vision-and-language models, where both images and text may encode sensitive or private information.
07.05.2025 18:54 —
👍 10
🔁 8
💬 1
📌 0
Flying to SG 🇸🇬 to attend #ICLR2025.
Check out our 3 papers:
☕️CREMA: Video-language + any modality reasoning
🛡️SAFREE: A training-free concept guard for any visual diffusion models
🧭SRDF: Human-level VL-navigation via self-refined data loop
feel free to DM me to grab a coffee&citywalk together 😉
22.04.2025 00:09 —
👍 1
🔁 0
💬 0
📌 0
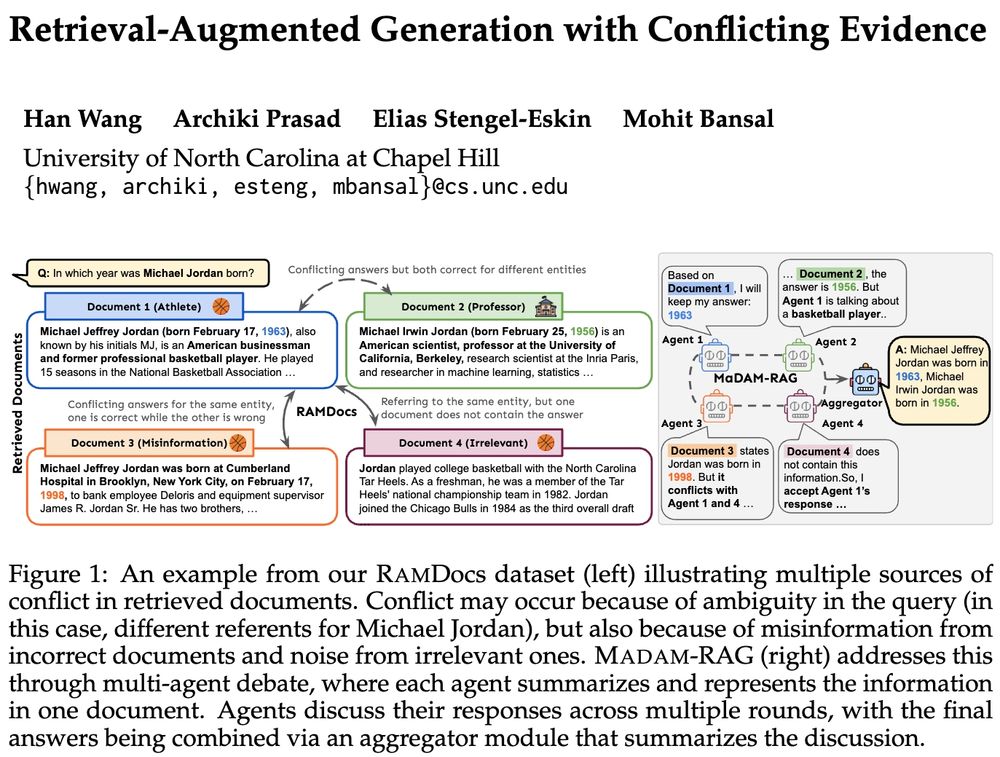
🚨Real-world retrieval is messy: queries are ambiguous or docs conflict & have incorrect/irrelevant info. How can we jointly address these problems?
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
18.04.2025 17:05 —
👍 14
🔁 7
💬 3
📌 0
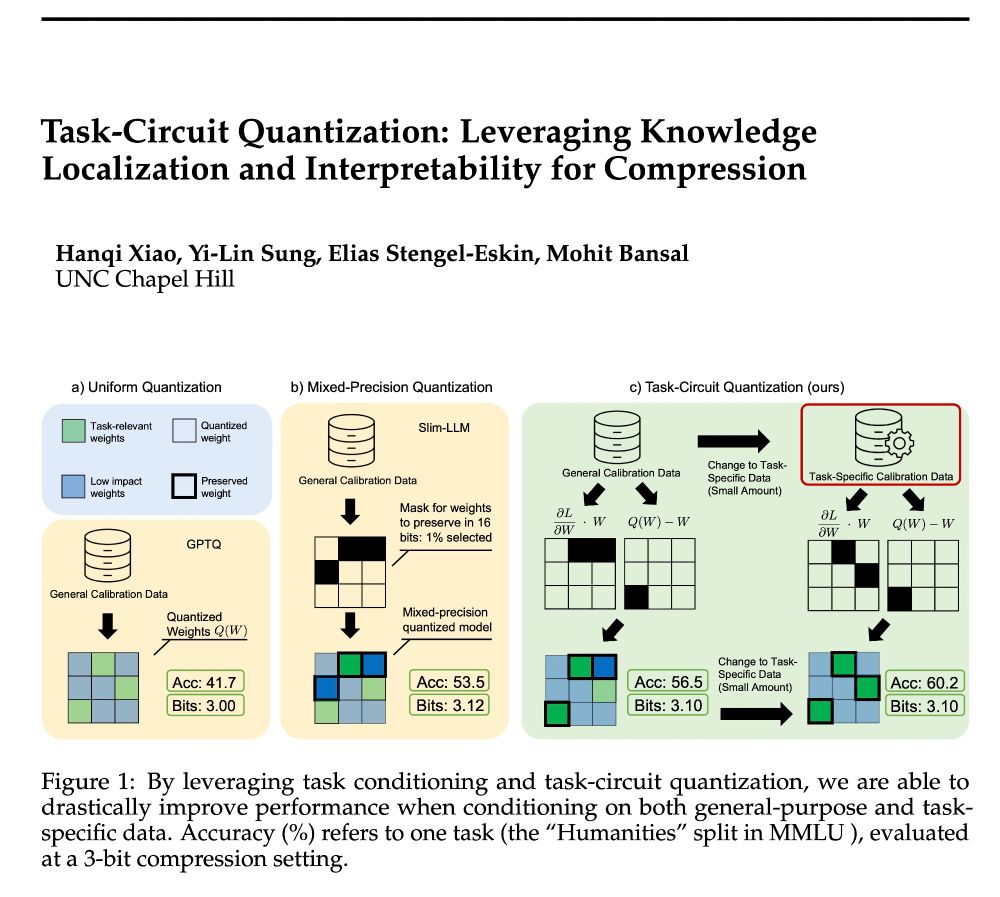
🚨Announcing TaCQ 🚨 a new mixed-precision quantization method that identifies critical weights to preserve. We integrate key ideas from circuit discovery, model editing, and input attribution to improve low-bit quant., w/ 96% 16-bit acc. at 3.1 avg bits (~6x compression)
📃 arxiv.org/abs/2504.07389
12.04.2025 14:19 —
👍 15
🔁 7
💬 1
📌 1
VEGGIE: Instructional Editing and Reasoning Video Concepts with Grounded Generation
VEGGIE: Instructional Editing and Reasoning Video Concepts with Grounded Generation
Thanks to all of my amazing co-authors from Adobe Research, UMichi, UNC
Difan Liu (co-lead), @marstin.bsky.social (co-led)
Yicong Hong, Yang Zhou, Hao Tan, Joyce Chai, @mohitbansal.bsky.social
Check out more details on our homepage/paper.
Website: veggie-gen.github.io
19.03.2025 18:56 —
👍 0
🔁 0
💬 0
📌 0


We further find that VEGGIE shows emergent zero-shot multimodal instruction following and in-context video editing ability, which may facilitate a broader range of future applications.
19.03.2025 18:56 —
👍 0
🔁 0
💬 1
📌 0

We project grounded queries into 2D spaces with PCA & t-SNE. We found Reasoning and Grounding cluster together, while Color, Env, and Change are closely grouped. Addition aligns with Reasoning and Grounding, suggesting addition involves semantic processes, while Removal is a more independent task.
19.03.2025 18:56 —
👍 0
🔁 0
💬 1
📌 0

we evaluate 7 different models on VEG-Bench across 8 distinct editing skills. Overall, VEGGIE demonstrates the best performance among instructional video editing models.
19.03.2025 18:56 —
👍 0
🔁 0
💬 1
📌 0

To further support our training, we also introduce a novel automatic instructional video data generation pipeline that lifts high-quality instructional image editing data into the video domain using image-to-video and video evaluation tools.
19.03.2025 18:56 —
👍 0
🔁 0
💬 1
📌 0

VEGGIE first leverages an MLLM to interpret complex instructions, generating frame-wise conditions, and then a video diffusion model is applied to reflect these conditions at the pixel space. Such continuous, learnable task query embeddings enable end-to-end training & capture task representations.
19.03.2025 18:56 —
👍 0
🔁 0
💬 1
📌 0
Existing video editing methods fall short of the goal of a simple, versatile video editor, requiring multiple models, complex pipelines, or extra caption/layout/human guidance. We introduce VEGGIE which formulates diverse editing tasks as end-to-end grounded generation in pixel space.
19.03.2025 18:56 —
👍 0
🔁 0
💬 1
📌 0

Introducing VEGGIE 🥦—a unified, end-to-end, and versatile instructional video generative model.
VEGGIE supports 8 skills, from object addition/removal/changing, and stylization to concept grounding/reasoning. It exceeds SoTA and shows 0-shot multimodal instructional & in-context video editing.
19.03.2025 18:56 —
👍 5
🔁 4
💬 1
📌 1

🎉 Congrats to the awesome students, postdocs, & collaborators for this exciting batch of #ICLR2025 and #NAACL2025 accepted papers (FYI some are on the academic/industry job market and a great catch 🙂), on diverse, important topics such as:
-- adaptive data generation environments/policies
...
🧵
27.01.2025 21:38 —
👍 18
🔁 9
💬 1
📌 0

🚨 We have postdoc openings at UNC 🙂
Exciting+diverse NLP/CV/ML topics**, freedom to create research agenda, competitive funding, very strong students, mentorship for grant writing, collabs w/ many faculty+universities+companies, superb quality of life/weather.
Please apply + help spread the word 🙏
23.12.2024 19:32 —
👍 37
🔁 15
💬 1
📌 3
I was so lucky to work with Jaemin in my 1st year and learned a lot from him. I can confidently say he's not only a top mind in multimodal AI but also an incredible mentor&collaborator. He is insightful, hands-on, and genuinely knows how to guide and inspire junior students👇👏
09.12.2024 09:59 —
👍 2
🔁 2
💬 1
📌 0

🚨 I am on the faculty job market this year 🚨
I will be presenting at #NeurIPS2024 and am happy to chat in-person or digitally!
I work on developing AI agents that can collaborate and communicate robustly with us and each other.
More at: esteng.github.io and in thread below
🧵👇
05.12.2024 19:00 —
👍 47
🔁 14
💬 2
📌 6
Looking forward to giving this Distinguished Lecture at StonyBrook next week & meeting the several awesome NLP + CV folks there - thanks Niranjan + all for the kind invitation 🙂
PS. Excited to give a new talk on "Planning Agents for Collaborative Reasoning and Multimodal Generation" ➡️➡️
🧵👇
03.12.2024 16:07 —
👍 23
🔁 8
💬 1
📌 0
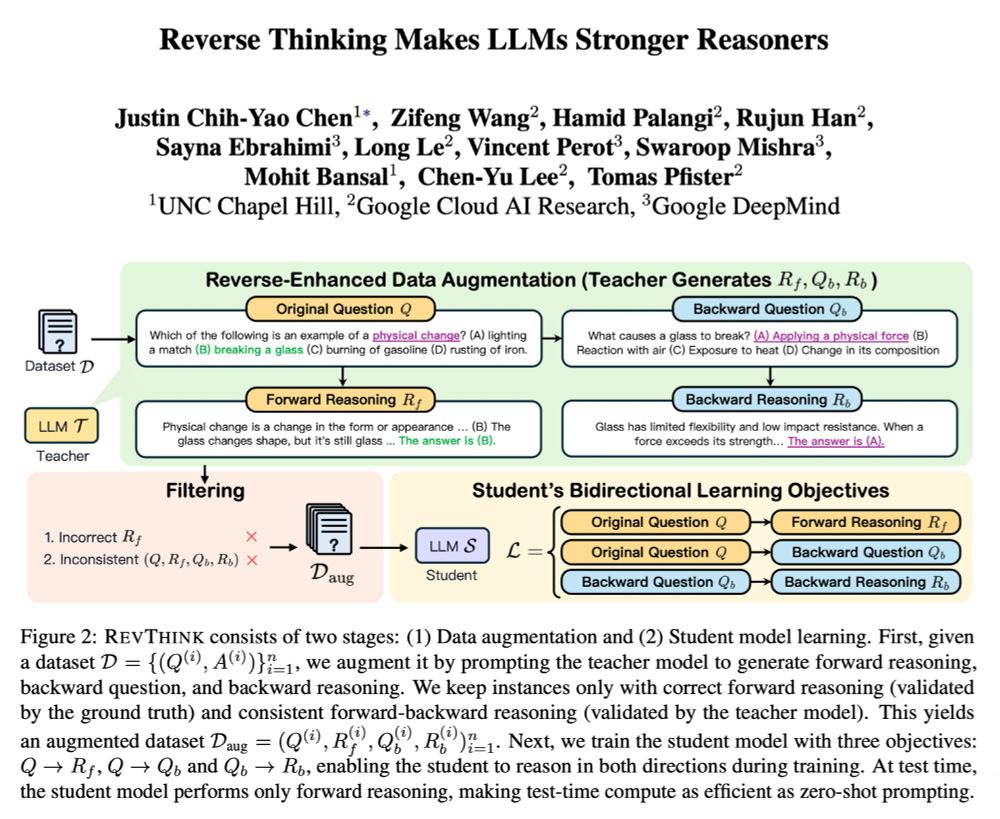
🚨 Reverse Thinking Makes LLMs Stronger Reasoners
We can often reason from a problem to a solution and also in reverse to enhance our overall reasoning. RevThink shows that LLMs can also benefit from reverse thinking 👉 13.53% gains + sample efficiency + strong generalization (on 4 OOD datasets)!
02.12.2024 19:29 —
👍 19
🔁 11
💬 1
📌 2
