Work done by Dan Braun, Lucius Bushnaq, Stefan Heimersheim, Jake Mendel, and me (Lee Sharkey)!
Check out our
- paper: publications.apolloresearch.ai/apd
- blog post: www.alignmentforum.org/posts/EPefYW...

@leesharkey.bsky.social
Scruting matrices @ Apollo Research
Work done by Dan Braun, Lucius Bushnaq, Stefan Heimersheim, Jake Mendel, and me (Lee Sharkey)!
Check out our
- paper: publications.apolloresearch.ai/apd
- blog post: www.alignmentforum.org/posts/EPefYW...
Overall, our approach helps address issues that seemed challenging using SAEs.
- It decomposes network parameters directly
- It suggests a conceptual foundation for the concept of a 'feature'
- It suggests an approach to better understanding feature geometry
and more.
The method is currently sensitive to hyperparameters, so still needs some work before it can be scaled.
But we have a few ideas for how to achieve this and plan to address that issue next!
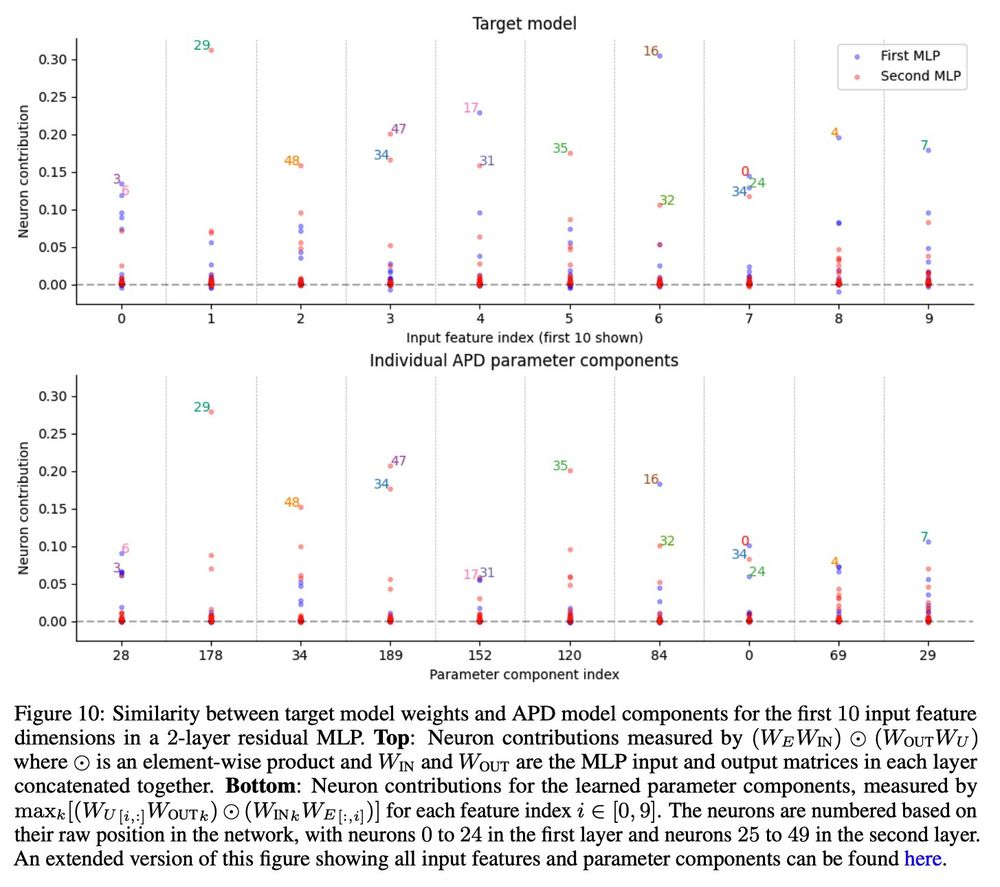
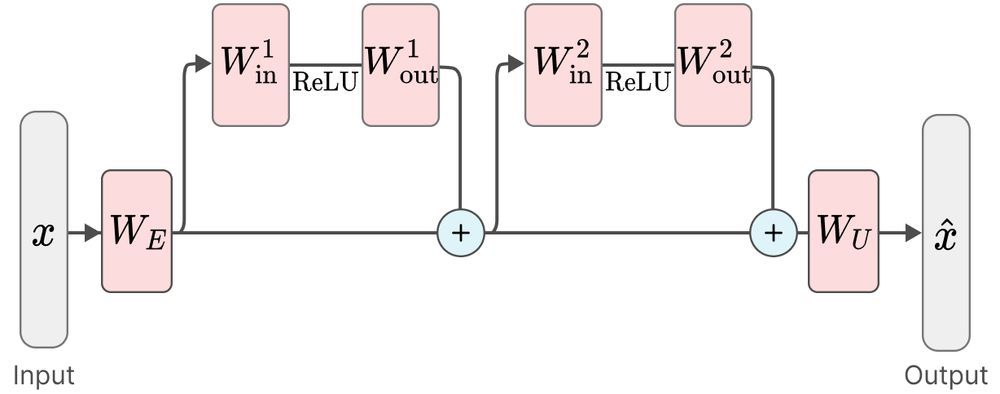
And the method lets us identify computations that are spread across multiple layers.
This has been conceptually challenging for the SAE paradigm to overcome. (Crosscoder features aren't the computations themselves, but are more akin to the results of the computations).
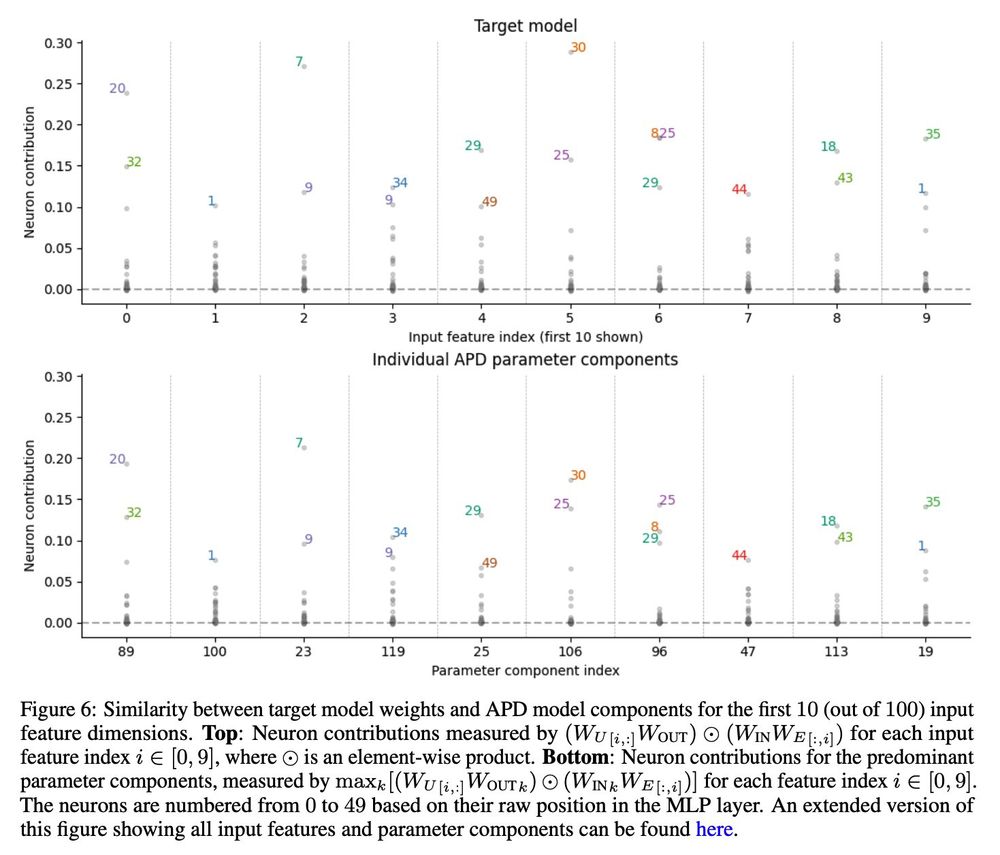
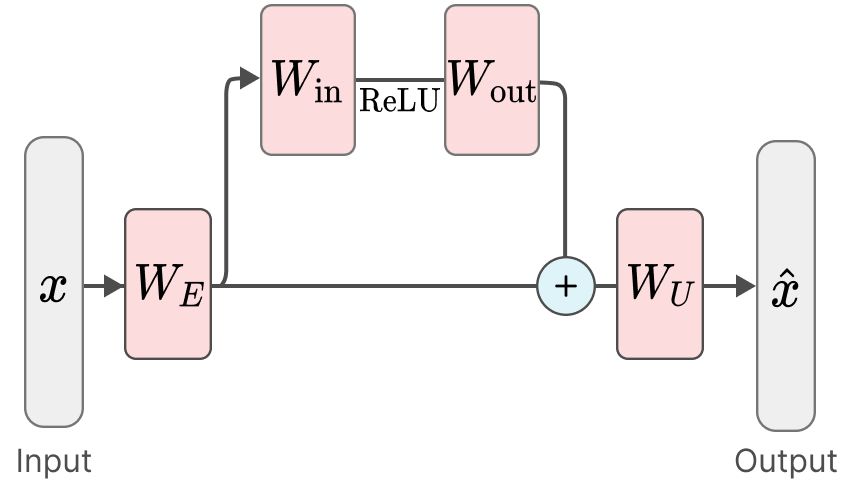
Our method lets us identify fundamental computations (or 'circuits') in a toy model of 'Compressed computation', which is a phenomenon similar to 'Computation in superposition'.
Each parameter component learns to implement a different basic computation.
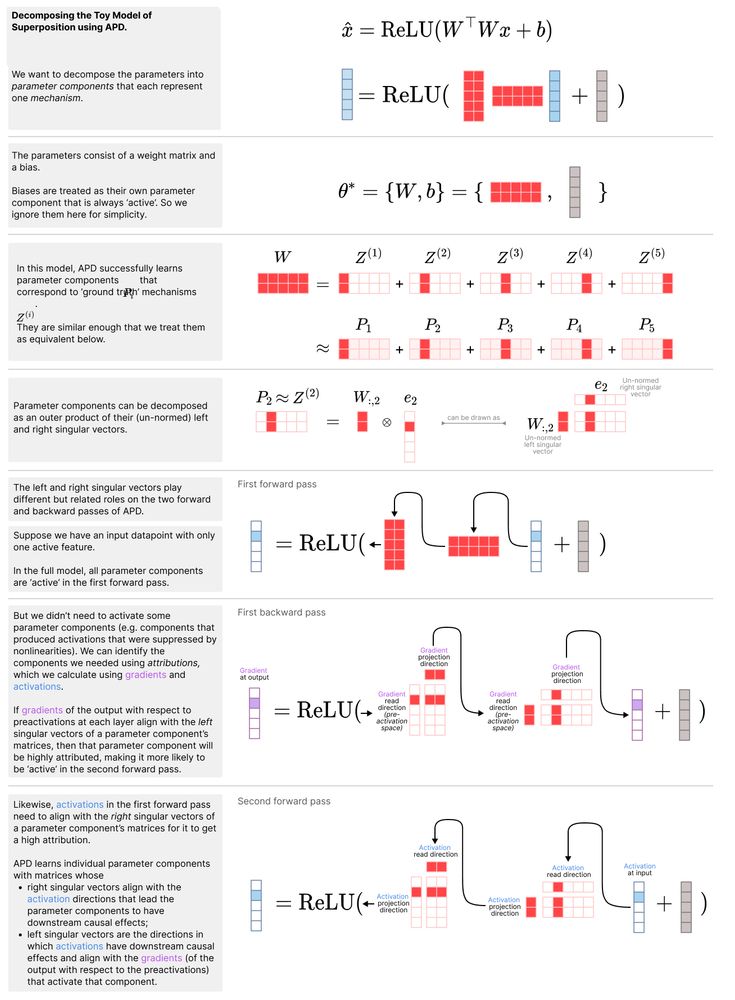
The key idea: Neural networks only need certain parts of their parameters on each forward pass. The rest can be thrown away (on that forward pass).
How to identify which parts are needed?
Using attribution methods.
Hence the name Attribution-based Parameter Decomposition!
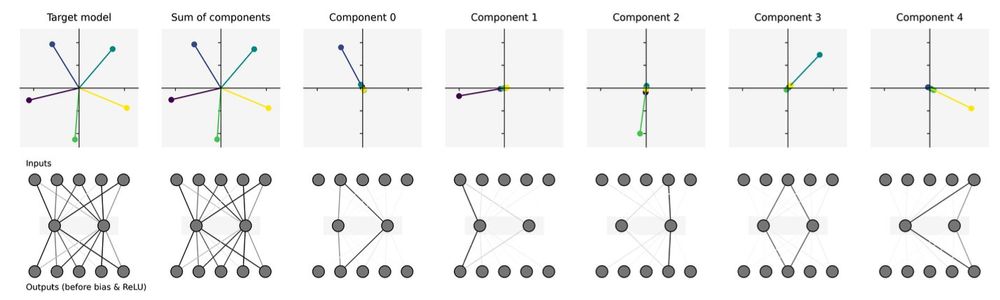
For example, with anthropic's Toy Model of Superposition, we can decompose the parameters directly into mechanisms that are used by individual features.
27.01.2025 19:29 — 👍 0 🔁 0 💬 1 📌 0Here, 'simple' means they span as few ranks and as few layers as possible.
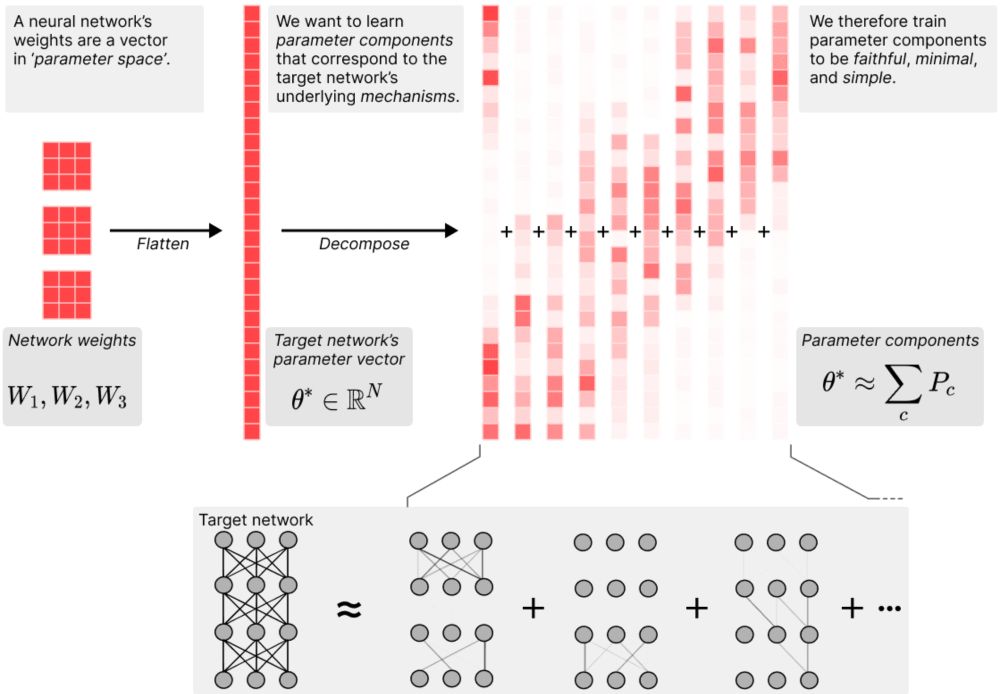
We think parameter components that satisfy these properties can reasonably be called the network's mechanisms.
This lets us identify mechanisms in toy models where there is known ground truth!
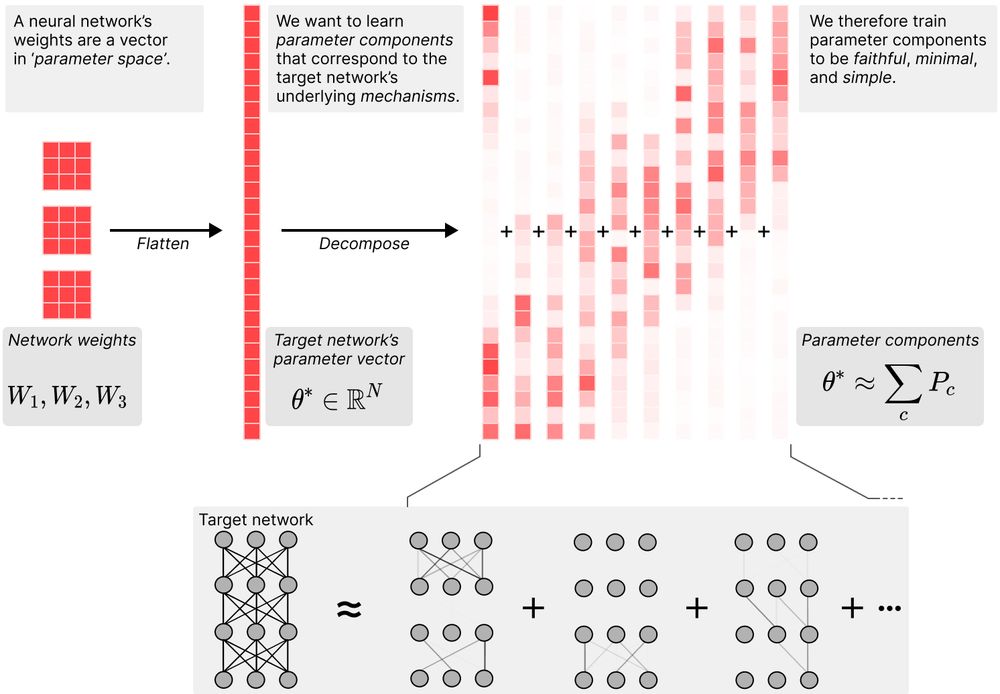
Parameter components are trained for three things:
- They sum to the original network's parameters
- As few as possible are needed to replicate the network's behavior on any given datapoint in the training data
- They are individually 'simpler' than the whole network.
A neural network's weights can be thought of as a big vector in 'parameter space'.
During training, gradient descent etches a network's 'mechanisms' into its parameter vector.
We look for those mechanisms by decomposing that parameter vector into 'parameter components'.
New interpretability paper from Apollo Research!
🟢Attribution-based Parameter Decomposition 🟢
It's a new way to decompose neural network parameters directly into mechanistic components.
It overcomes many of the issues with SAEs! 🧵
To my surprise, we find the opposite of what I thought when we started this project:
The approach to reasoning LLMs use looks unlike retrieval, and more like a generalisable strategy synthesising procedural knowledge from many documents doing a similar form of reasoning.
I'd like to be added, thanks!
19.11.2024 11:06 — 👍 1 🔁 0 💬 0 📌 0

















