
We made a complete Guide on Reinforcement Learning (RL) for LLMs!
Learn about:
• RL's goal & why it's key to building intelligent AI agents
• Why o3, Claude 4 & R1 use RL
• GRPO, RLHF, DPO, reward functions
• Training your own local R1 model with Unsloth
🔗 docs.unsloth.ai/basics/reinf...
17.06.2025 15:09 — 👍 1 🔁 0 💬 0 📌 0

You can now run DeepSeek-R1-0528 locally with our Dynamic 1-bit GGUFs! 🐋
We shrank the full 715GB model to just 168GB (-80% size).
We achieve optimal accuracy by selectively quantizing layers.
DeepSeek-R1-0528-Qwen3-8B is also supported.
GGUFs: huggingface.co/unsloth/Deep...
30.05.2025 20:34 — 👍 3 🔁 1 💬 0 📌 0
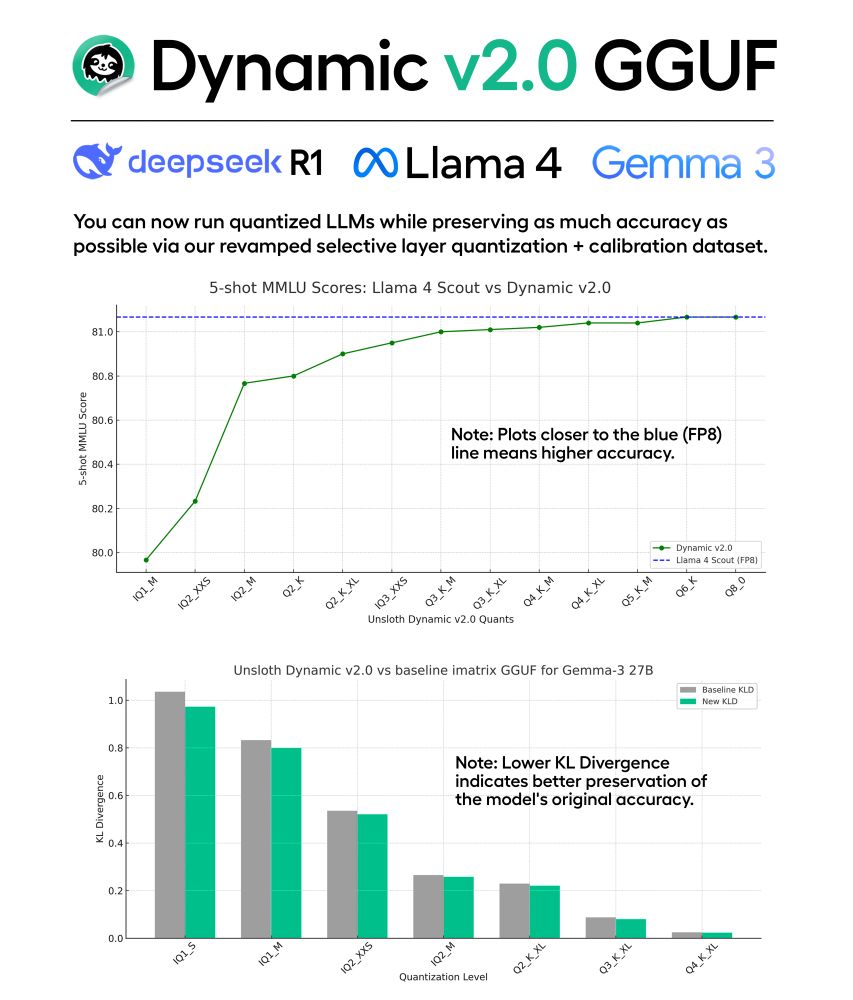
Introducing Unsloth Dynamic v2.0 GGUFs!
v2.0 sets new benchmarks on 5-shot MMLU + KL Divergence. So, you can now run quantized LLMs with minimal accuracy loss.
For benchmarks, we built an evaluation framework to match official MMLU scores of Llama 4 & Gemma 3
Blog: docs.unsloth.ai/basics/dynam...
24.04.2025 19:12 — 👍 4 🔁 1 💬 0 📌 1

You can now run Llama 4 on your local device! 🦙
We shrank Maverick (402B) from 400GB to 122GB (-70%).
Our Dynamic 1.78-bit iMatrix GGUFs ensures optimal accuracy & size by selectively quantizing layers.
Scout + Maverick GGUFs: huggingface.co/collections/...
Guide: docs.unsloth.ai/basics/tutor...
08.04.2025 20:39 — 👍 14 🔁 2 💬 0 📌 1
The 1.58-bit quant fits in 131GB VRAM (2× H100s) for fast throughput inference at ~140 tokens/s.
For best results, use 2.51-bit Dynamic quant & at least 160GB+ combined VRAM + RAM.
Basic 1-bit & 2-bit quantization causes the model to produce repetition and poor code. Our dynamic quants solve this.
25.03.2025 23:54 — 👍 0 🔁 0 💬 0 📌 0

How to Run Deepseek-V3-0324 Locally
DeepSeek's V3-0324 model is the most powerful open-source model rivalling GPT 4.5 and Claude 3.7. Learn to run the model with Unsloth Dynamic quants.
You can now Run DeepSeek-V3-0324 locally using our 1.58 & 2.51-bit Dynamic GGUF!🐋
We shrank the 720GB model to 131GB (-80%) by selectively quantizing layers for the best performance. Fixes basic quants breaking & bad output issues: www.unsloth.ai/blog/deepsee...
GGUF huggingface.co/unsloth/Deep...
25.03.2025 23:54 — 👍 12 🔁 1 💬 1 📌 0
We teamed up with 🤗Hugging Face to release a free notebook for fine-tuning Gemma 3 with GRPO
Learn to:
• Enable reasoning in Gemma 3 (1B)
• Prepare/understand reward functions
• Make GRPO work for tiny LLMs
Notebook: colab.research.google.com/github/unslo...
Details: huggingface.co/reasoning-co...
19.03.2025 16:31 — 👍 15 🔁 6 💬 0 📌 0

We made a Guide to teach you how to Fine-tune LLMs correctly!
Learn about:
• Choosing the right parameters & training method
• RL, GRPO, DPO, CPT
• Data prep, Overfitting, Evaluation
• Training with Unsloth & deploy on vLLM, Ollama, Open WebUI
🔗https://docs.unsloth.ai/get-started/fine-tuning-guide
10.03.2025 16:30 — 👍 19 🔁 5 💬 0 📌 0

Tutorial: Train your own Reasoning LLM for free!
Make Llama 3.1 (8B) have chain-of-thought with DeepSeek's GRPO algorithm. Unsloth enables 90% less VRAM use.
Learn about:
• Reward Functions + dataset prep
• Training on free Colab GPUs
• Running + Evaluating
Guide: docs.unsloth.ai/basics/reaso...
25.02.2025 18:32 — 👍 10 🔁 3 💬 0 📌 0
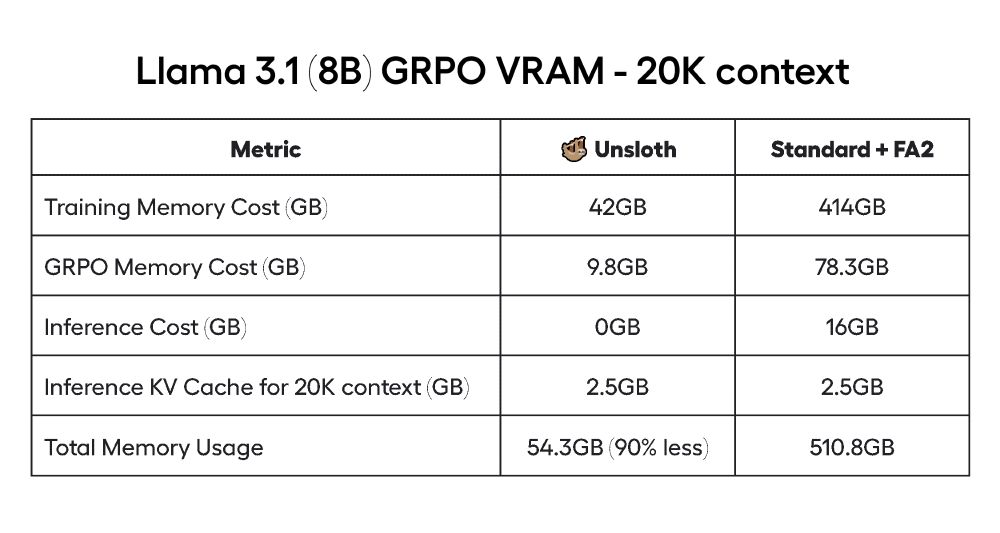
For our benchmarks, a standard GRPO QLoRA setup (TRL + FA2) for Llama 3.1 (8B) at 20K context required 510.8GB VRAM. Unsloth’s GRPO algorithms reduces this to just 54.3GB.
The 5GB VRAM requirement for Qwen2.5 (1.5B) is down from 7GB in our previous GRPO release two weeks ago!
20.02.2025 18:41 — 👍 1 🔁 0 💬 0 📌 0
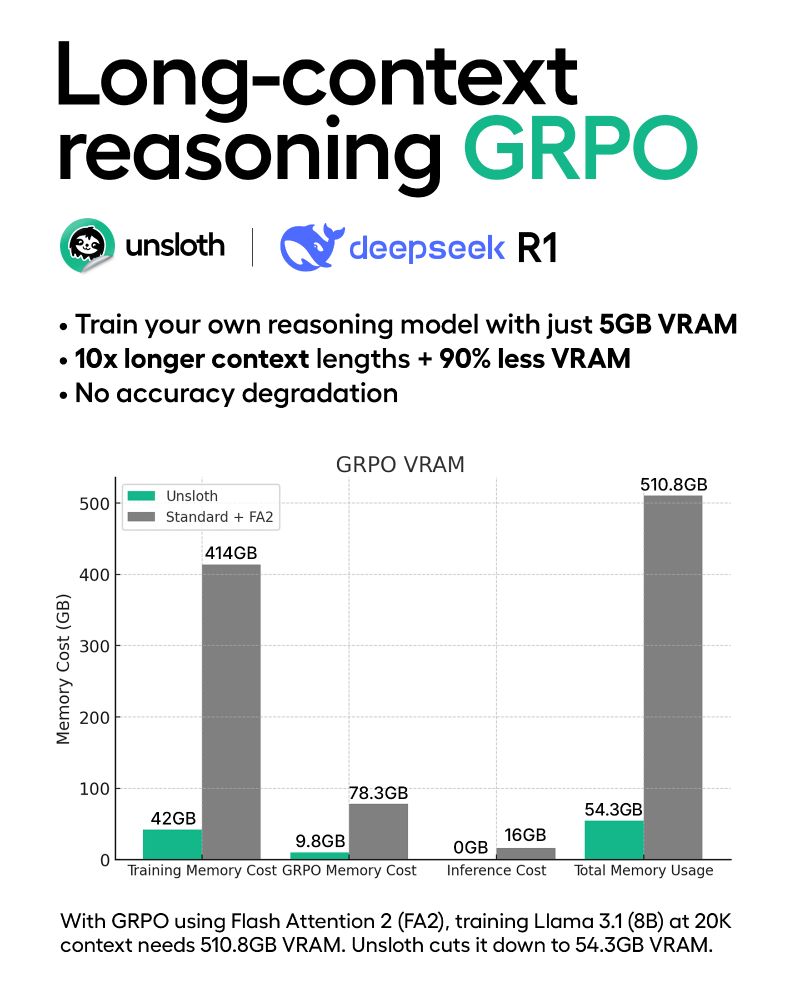
Today, we’re launching new algorithms that enable 10x longer context lengths & 90% less VRAM for training Reasoning Models (GRPO).
Using Unsloth, you can now train your own reasoning model with just 5GB VRAM for Qwen2.5-1.5B with no accuracy loss.
Blog: unsloth.ai/blog/grpo
20.02.2025 18:41 — 👍 11 🔁 3 💬 1 📌 0

You can now reproduce DeepSeek-R1's reasoning on your own local device!
Experience the "Aha" moment with just 7GB VRAM.
Unsloth reduces GRPO training memory use by 80%.
15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models.
Blog: unsloth.ai/blog/r1-reas...
06.02.2025 18:09 — 👍 35 🔁 9 💬 0 📌 1

Finetune Phi-4 with Unsloth
Fine-tune Microsoft's new Phi-4 model with Unsloth!
We've also found & fixed 4 bugs in the model.
You can finetune Phi-4 for free on Colab now!
Unsloth finetunes LLMs 2x faster, with 70% less VRAM, 12x longer context - with no accuracy loss
Documentation: docs.unsloth.ai
We also fixed 4 bugs in Phi-4: unsloth.ai/blog/phi4
Phi-4 Colab: colab.research.google.com/github/unslo...
10.01.2025 19:55 — 👍 15 🔁 3 💬 0 📌 0
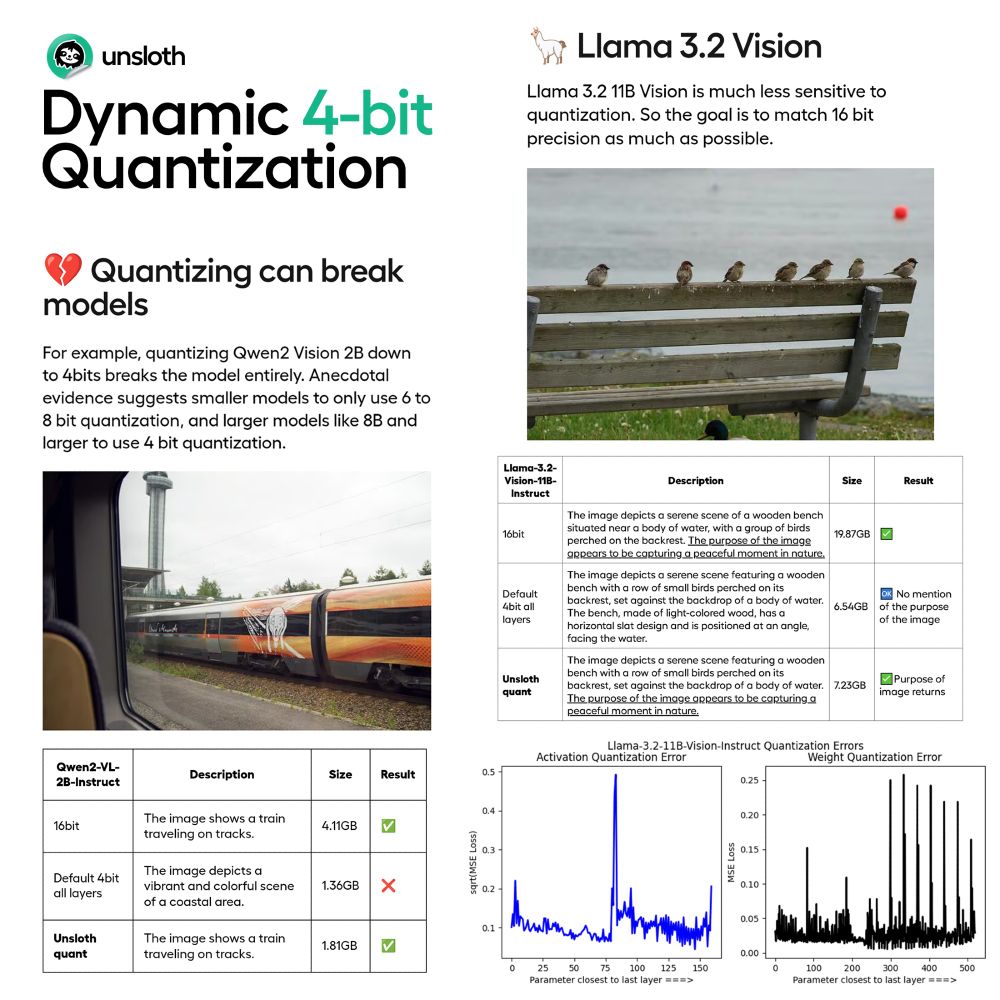
Introducing Unsloth Dynamic 4-bit Quantization!
Naive quantization often harms accuracy but we avoid quantizing certain parameters. This achieves higher accuracy using only <10% more VRAM than BnB 4bit
Read our Blog: unsloth.ai/blog/dynamic...
Quants on Hugging Face: huggingface.co/collections/...
04.12.2024 19:51 — 👍 15 🔁 6 💬 1 📌 2

Llama 3.2 Vision Fine-tuning with Unsloth
Fine-tune Meta's Llama 3.2 Vision, Llava, Qwen 2.5 Vision models open-source 2x faster via Unsloth! Beginner friendly.
You can finetune Llama-3.2-Vision-11B for free on Colab now!
Unsloth finetunes VLMs 2x faster, with 50% less VRAM, 6x longer context - with no accuracy loss.
Other VLMs like Qwen2-VL, Llava & Pixtral are supported.
Blog: unsloth.ai/blog/vision
Fine-tuning Colabs: docs.unsloth.ai/get-started/...
21.11.2024 19:14 — 👍 18 🔁 3 💬 0 📌 0
A business analyst at heart who enjoys delving into AI, ML, data engineering, data science, data analytics, and modeling. My views are my own.
Always pondering startups, ML, Rust, Python, and 3D printing.
Independent ML researcher consulting on LMs + data.
Previously: Salesforce Research, MetaMind, CommonCrawl, Harvard. 🇦🇺 in SF. He/him.
Personal blog: https://state.smerity.com
Tech Lead and LLMs at @huggingface 👨🏻💻 🤗 AWS ML Hero 🦸🏻 | Cloud & ML enthusiast | 📍Nuremberg | 🇩🇪 https://philschmid.de
https://Answer.AI & https://fast.ai founding CEO; previous: hon professor @ UQ; leader of masks4all; founding CEO Enlitic; founding president Kaggle; various other stuff…
official Bluesky account (check username👆)
Bugs, feature requests, feedback: support@bsky.app






