



Flow4R: Unifying 4D Reconstruction and Tracking with Scene Flow
@shenhanqian.bsky.social, @ganlinzhang.xyz, @elliottwu.bsky.social, @dcremers.bsky.social
tl;dr: 4D DUSt3R
arxiv.org/abs/2602.14021
Flow4R: Unifying 4D Reconstruction and Tracking with Scene Flow
@shenhanqian.bsky.social, @ganlinzhang.xyz, @elliottwu.bsky.social, @dcremers.bsky.social
tl;dr: 4D DUSt3R
arxiv.org/abs/2602.14021




𝗦𝘂𝗿𝗳𝗦𝗽𝗹𝗮𝘁: 𝗖𝗼𝗻𝗾𝘂𝗲𝗿𝗶𝗻𝗴 𝗙𝗲𝗲𝗱𝗳𝗼𝗿𝘄𝗮𝗿𝗱 𝟮𝗗 𝗚𝗮𝘂𝘀𝘀𝗶𝗮𝗻 𝗦𝗽𝗹𝗮𝘁𝘁𝗶𝗻𝗴 𝘄𝗶𝘁𝗵 𝗦𝘂𝗿𝗳𝗮𝗰𝗲 𝗖𝗼𝗻𝘁𝗶𝗻𝘂𝗶𝘁𝘆 𝗣𝗿𝗶𝗼𝗿𝘀
Bing He, Jingnan Gao, Yunuo Chen ... Wenjun Zhang
arxiv.org/abs/2602.02000
Trending on www.scholar-inbox.com




𝗙𝗮𝘀𝘁 𝗔𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗩𝗶𝗱𝗲𝗼 𝗗𝗶𝗳𝗳𝘂𝘀𝗶𝗼𝗻 𝗮𝗻𝗱 𝗪𝗼𝗿𝗹𝗱 𝗠𝗼𝗱𝗲𝗹𝘀 𝘄𝗶𝘁𝗵 𝗧𝗲𝗺𝗽𝗼𝗿𝗮𝗹 𝗖𝗮𝗰𝗵𝗲 𝗖𝗼𝗺𝗽𝗿𝗲𝘀𝘀𝗶𝗼𝗻 𝗮𝗻𝗱 𝗦𝗽𝗮𝗿𝘀𝗲 𝗔𝘁𝘁𝗲𝗻𝘁𝗶𝗼𝗻
Dvir Samuel, Issar Tzachor, Matan Levy ... Rami Ben-Ari
arxiv.org/abs/2602.01801
Trending on www.scholar-inbox.com
𝗠𝗼𝘁𝗶𝗼𝗻𝗖𝗿𝗮𝗳𝘁𝗲𝗿: 𝗗𝗲𝗻𝘀𝗲 𝗚𝗲𝗼𝗺𝗲𝘁𝗿𝘆 𝗮𝗻𝗱 𝗠𝗼𝘁𝗶𝗼𝗻 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝘄𝗶𝘁𝗵 𝗮 𝟰𝗗 𝗩𝗔𝗘
Ruijie Zhu, Jiahao Lu, Wenbo Hu ... Chuanxia Zheng
arxiv.org/abs/2602.08961
Trending on www.scholar-inbox.com




𝗚𝗲𝗼𝗺𝗲𝘁𝗿𝘆-𝗔𝘄𝗮𝗿𝗲 𝗥𝗼𝘁𝗮𝗿𝘆 𝗣𝗼𝘀𝗶𝘁𝗶𝗼𝗻 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴 𝗳𝗼𝗿 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝘁 𝗩𝗶𝗱𝗲𝗼 𝗪𝗼𝗿𝗹𝗱 𝗠𝗼𝗱𝗲𝗹
Chendong Xiang, Jiajun Liu, Jintao Zhang ... Jun Zhu
arxiv.org/abs/2602.07854
Trending on www.scholar-inbox.com




𝟰𝗥𝗖: 𝟰𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝘃𝗶𝗮 𝗖𝗼𝗻𝗱𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗤𝘂𝗲𝗿𝘆𝗶𝗻𝗴 𝗔𝗻𝘆𝘁𝗶𝗺𝗲 𝗮𝗻𝗱 𝗔𝗻𝘆𝘄𝗵𝗲𝗿𝗲
Yihang Luo, Shangchen Zhou, Yushi Lan ... Chen Change Loy
arxiv.org/abs/2602.10094
Trending on www.scholar-inbox.com




𝗨𝗻𝗶𝗳𝗶𝗲𝗱 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿 𝗳𝗼𝗿 𝟯𝗗 𝗦𝗰𝗲𝗻𝗲 𝗨𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱𝗶𝗻𝗴
Sebastian Koch, Johanna Wald, Hide Matsuki ... Federico Tombari
arxiv.org/abs/2512.14364
Trending on www.scholar-inbox.com




On Geometric Understanding and Learned Data Priors in VGGT
Jelena Bratulić, Sudhanshu Mittal, Thomas Brox, Christian Rupprecht
tl;dr: in title
arxiv.org/abs/2512.11508




𝗘𝗻𝗱𝗹𝗲𝘀𝘀 𝗪𝗼𝗿𝗹𝗱: 𝗥𝗲𝗮𝗹-𝗧𝗶𝗺𝗲 𝟯𝗗-𝗔𝘄𝗮𝗿𝗲 𝗟𝗼𝗻𝗴 𝗩𝗶𝗱𝗲𝗼 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻
Ke Zhang, Yiqun Mei, Jiacong Xu, Vishal M. Patel
arxiv.org/abs/2512.12430
Trending on www.scholar-inbox.com




𝗣𝗟𝗔𝗡𝗔𝟯𝗥: 𝗭𝗲𝗿𝗼-𝘀𝗵𝗼𝘁 𝗠𝗲𝘁𝗿𝗶𝗰 𝗣𝗹𝗮𝗻𝗮𝗿 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝘃𝗶𝗮 𝗙𝗲𝗲𝗱-𝗙𝗼𝗿𝘄𝗮𝗿𝗱 𝗣𝗹𝗮𝗻𝗮𝗿 𝗦𝗽𝗹𝗮𝘁𝘁𝗶𝗻𝗴
Changkun Liu, Bin Tan, Zeran Ke ... Tristan Braud
arxiv.org/abs/2510.18714
Trending on www.scholar-inbox.com




MASt3R-Fusion: Integrating Feed-Forward Visual Model with IMU, GNSS for High-Functionality SLAM
Yuxuan Zhou, Xingxing Li, Shengyu Li, Zhuohao Yan, Chunxi Xia, Shaoquan Feng
tl;dr: MASt3R-SLAM+IMU+GNSS
arxiv.org/abs/2509.20757



𝟰𝗗 𝗗𝗿𝗶𝘃𝗶𝗻𝗴 𝗦𝗰𝗲𝗻𝗲 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 𝗪𝗶𝘁𝗵 𝗦𝘁𝗲𝗿𝗲𝗼 𝗙𝗼𝗿𝗰𝗶𝗻𝗴
Hao Lu, Zhuang Ma, Guangfeng Jiang ... Yingcong Chen
arxiv.org/abs/2509.20251
Trending on www.scholar-inbox.com
RaySt3R was accepted to NeurIPS! Check out the HuggingFace demo for image to 3D in cluttered scenes huggingface.co/spaces/bartd...
19.09.2025 17:28 — 👍 5 🔁 2 💬 0 📌 0



𝗠𝗮𝗽𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴: 𝗨𝗻𝗶𝘃𝗲𝗿𝘀𝗮𝗹 𝗙𝗲𝗲𝗱-𝗙𝗼𝗿𝘄𝗮𝗿𝗱 𝗠𝗲𝘁𝗿𝗶𝗰 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻
Nikhil Keetha, Norman Müller, Johannes Schönberger ... Peter Kontschieder
arxiv.org/abs/2509.13414
Trending on www.scholar-inbox.com




SpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, Xiaoxiao Long, Hao Zhu, Zhaoxiang Zhang, Xun Cao, Yao Yao
tl;dr: in title
arxiv.org/abs/2509.09676



3D and 4D World Modeling: A Survey
tl;dr: in title
arxiv.org/abs/2509.07996




Scaling Transformer-Based Novel View Synthesis Models with Token Disentanglement and Synthetic Data
Nithin Gopalakrishnan Nair, Srinivas Kaza, Xuan Luo, Vishal M. Patel, Stephen Lombardi, Jungyeon Park
arxiv.org/abs/2509.06950
Looking for fully configurable 3D street scene assets and real-time rendered videos? Our latest work generates physically-grounded 3D scenes ideal for robot learning & testing.
Check out our paper + interactive demo: light.princeton.edu/lsd-3d




FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
You Shen, Zhipeng Zhang, Yansong Qu, Liujuan Cao
tl;dr: token merging->VGGT without dense global attention
arxiv.org/abs/2509.02560
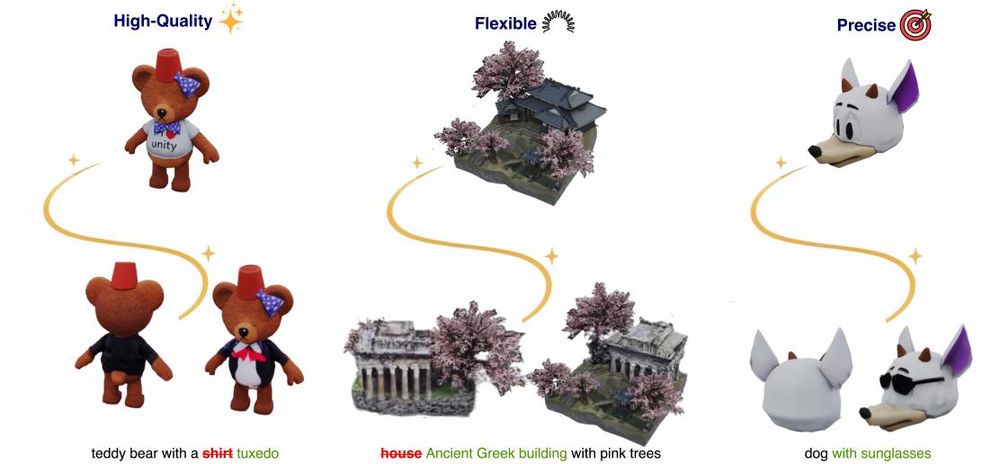

𝟯𝗗-𝗟𝗔𝗧𝗧𝗘: 𝗟𝗮𝘁𝗲𝗻𝘁 𝗦𝗽𝗮𝗰𝗲 𝟯𝗗 𝗘𝗱𝗶𝘁𝗶𝗻𝗴 𝗳𝗿𝗼𝗺 𝗧𝗲𝘅𝘁𝘂𝗮𝗹 𝗜𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻𝘀
Maria Parelli, Michael Oechsle, Michael Niemeyer ... Andreas Geiger
arxiv.org/abs/2509.00269
Trending on www.scholar-inbox.com




𝗖𝗼𝗺𝗽𝗹𝗲𝘁𝗲 𝗚𝗮𝘂𝘀𝘀𝗶𝗮𝗻 𝗦𝗽𝗹𝗮𝘁𝘀 𝗳𝗿𝗼𝗺 𝗮 𝗦𝗶𝗻𝗴𝗹𝗲 𝗜𝗺𝗮𝗴𝗲 𝘄𝗶𝘁𝗵 𝗗𝗲𝗻𝗼𝗶𝘀𝗶𝗻𝗴 𝗗𝗶𝗳𝗳𝘂𝘀𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹𝘀
Ziwei Liao, Mohamed Sayed, Steven L. Waslander ... Michael Firman
arxiv.org/abs/2508.21542
Trending on www.scholar-inbox.com




𝗠𝗲𝘀𝗵𝗦𝗽𝗹𝗮𝘁: 𝗚𝗲𝗻𝗲𝗿𝗮𝗹𝗶𝘇𝗮𝗯𝗹𝗲 𝗦𝗽𝗮𝗿𝘀𝗲-𝗩𝗶𝗲𝘄 𝗦𝘂𝗿𝗳𝗮𝗰𝗲 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝘃𝗶𝗮 𝗚𝗮𝘂𝘀𝘀𝗶𝗮𝗻 𝗦𝗽𝗹𝗮𝘁𝘁𝗶𝗻𝗴
Hanzhi Chang, Ruijie Zhu, Wenjie Chang ... Tianzhu Zhang
arxiv.org/abs/2508.17811
Trending on www.scholar-inbox.com

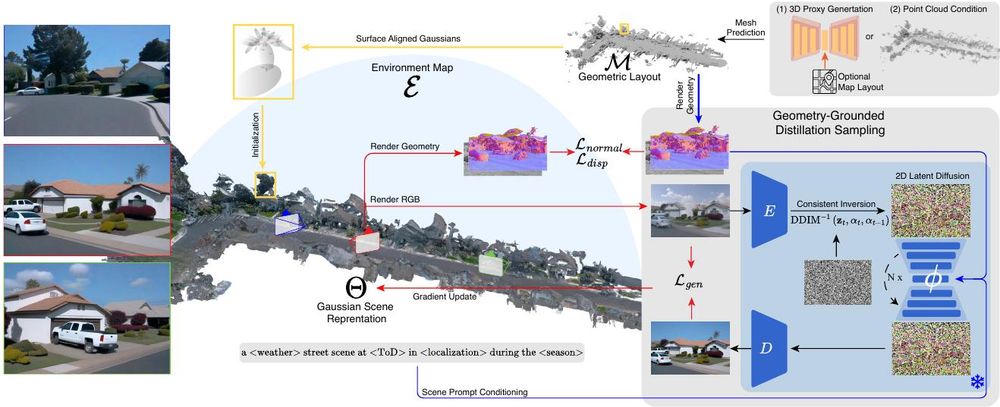


𝗟𝗦𝗗-𝟯𝗗: 𝗟𝗮𝗿𝗴𝗲-𝗦𝗰𝗮𝗹𝗲 𝟯𝗗 𝗗𝗿𝗶𝘃𝗶𝗻𝗴 𝗦𝗰𝗲𝗻𝗲 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 𝘄𝗶𝘁𝗵 𝗚𝗲𝗼𝗺𝗲𝘁𝗿𝘆 𝗚𝗿𝗼𝘂𝗻𝗱𝗶𝗻𝗴
Julian Ost, Andrea Ramazzina, Amogh Joshi ... Felix Heide
arxiv.org/abs/2508.19204
Trending on www.scholar-inbox.com




𝟰𝗗𝗡𝗲𝗫: 𝗙𝗲𝗲𝗱-𝗙𝗼𝗿𝘄𝗮𝗿𝗱 𝟰𝗗 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗠𝗼𝗱𝗲𝗹𝗶𝗻𝗴 𝗠𝗮𝗱𝗲 𝗘𝗮𝘀𝘆
Zhaoxi Chen, Tianqi Liu, Long Zhuo ... Ziwei Liu
arxiv.org/abs/2508.13154
Trending on www.scholar-inbox.com


𝗩𝗶𝗣𝗘: 𝗩𝗶𝗱𝗲𝗼 𝗣𝗼𝘀𝗲 𝗘𝗻𝗴𝗶𝗻𝗲 𝗳𝗼𝗿 𝟯𝗗 𝗚𝗲𝗼𝗺𝗲𝘁𝗿𝗶𝗰 𝗣𝗲𝗿𝗰𝗲𝗽𝘁𝗶𝗼𝗻
Jiahui Huang, Qunjie Zhou, Hesam Rabeti ... Sanja Fidler
arxiv.org/abs/2508.10934
Trending on www.scholar-inbox.com

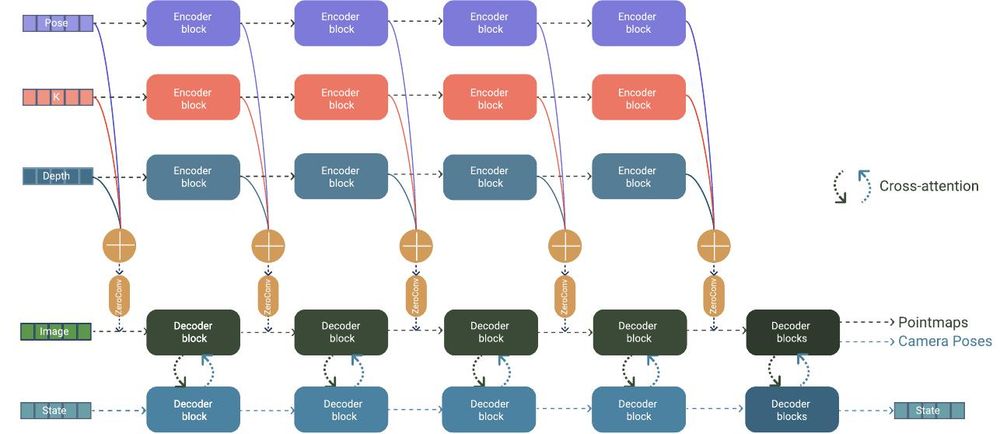


𝗚-𝗖𝗨𝗧𝟯𝗥: 𝗚𝘂𝗶𝗱𝗲𝗱 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝘄𝗶𝘁𝗵 𝗖𝗮𝗺𝗲𝗿𝗮 𝗮𝗻𝗱 𝗗𝗲𝗽𝘁𝗵 𝗣𝗿𝗶𝗼𝗿 𝗜𝗻𝘁𝗲𝗴𝗿𝗮𝘁𝗶𝗼𝗻
Ramil Khafizov, Artem Komarichev, Ruslan Rakhimov ... Evgeny Burnaev
arxiv.org/abs/2508.11379
Trending on www.scholar-inbox.com




Mem4D: Decoupling Static and Dynamic Memory for Dynamic Scene Reconstruction
Xudong Cai, Shuo Wang, Peng Wang, Yongcai Wang, Zhaoxin Fan, Wanting Li, Tianbao Zhang, Jianrong Tao, Yeying Jin, Deying Li
tl;dr: 4D cost volumes->dynamic; feature bank->static
arxiv.org/abs/2508.07908




iLRM: An Iterative Large 3D Reconstruction Model
Gyeongjin Kang, Seungtae Nam, Xiangyu Sun, @samehkhamis.bsky.social, Abdelrahman Mohamed, Eunbyung Park
arxiv.org/abs/2507.23277
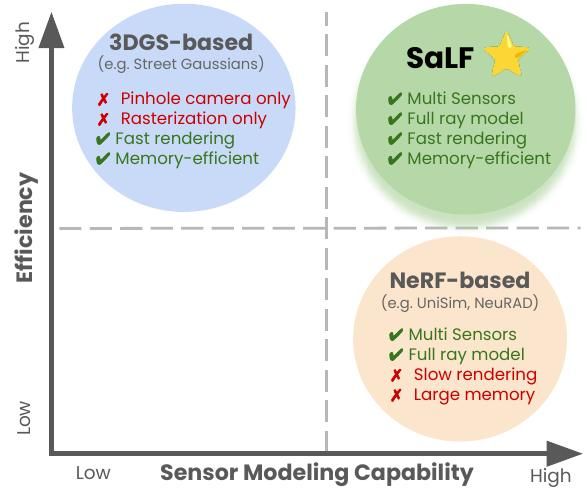
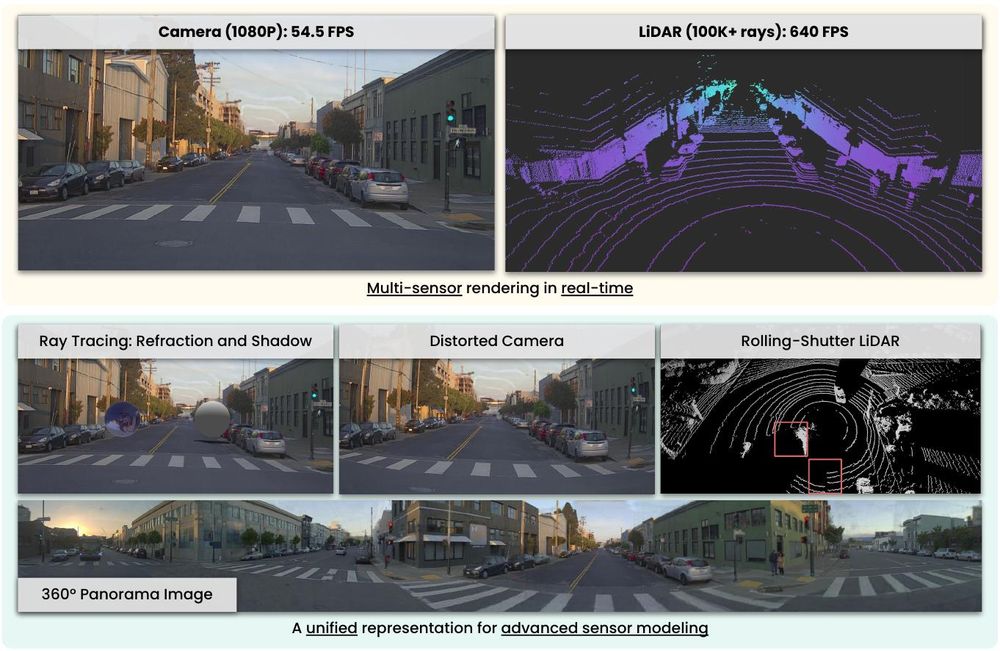
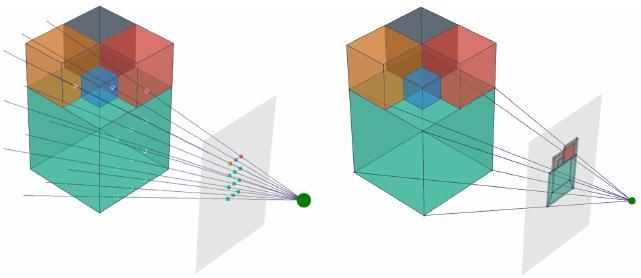

𝗦𝗮𝗟𝗙: 𝗦𝗽𝗮𝗿𝘀𝗲 𝗟𝗼𝗰𝗮𝗹 𝗙𝗶𝗲𝗹𝗱𝘀 𝗳𝗼𝗿 𝗠𝘂𝗹𝘁𝗶-𝗦𝗲𝗻𝘀𝗼𝗿 𝗥𝗲𝗻𝗱𝗲𝗿𝗶𝗻𝗴 𝗶𝗻 𝗥𝗲𝗮𝗹-𝗧𝗶𝗺𝗲
Yun Chen, Matthew Haines, Jingkang Wang ... Raquel Urtasun
arxiv.org/abs/2507.18713
Trending on www.scholar-inbox.com




Dens3R: A Foundation Model for 3D Geometry Prediction
Xianze Fang, Jingnan Gao, Zhe Wang, Zhuo Chen, Xingyu Ren, Jiangjing Lyu, Qiaomu Ren, Zhonglei Yang, Xiaokang Yang, Yichao Yan, Chengfei Lyu
arxiv.org/abs/2507.16290
