📽️ Check out Visual Odometry Transformer! VoT is an end-to-end model for getting accurate metric camera poses from monocular videos.
vladimiryugay.github.io/vot/
07.10.2025 09:02 —
👍 10
🔁 4
💬 1
📌 0
#TTT3R: 3D Reconstruction as Test-Time Training
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
01.10.2025 06:35 —
👍 37
🔁 4
💬 0
📌 4

distortion_averaging/simple_calibration_unique_cameras.ipynb at main · DaniilSinitsyn/distortion_averaging
PRaDA: Projective Radial Distortion Averaging. Contribute to DaniilSinitsyn/distortion_averaging development by creating an account on GitHub.
The key is working in projective space, estimating only fundamental matrices and distortion parameters. These can then be used to initialize full SfM, leading to an overall more robust pipeline.
Check out the jupyter notebook for a typical example with python bindings github.com/DaniilSinits...
09.07.2025 13:59 —
👍 2
🔁 0
💬 0
📌 0
🦖 We present “Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion”. #ICCV2025
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
09.07.2025 13:17 —
👍 24
🔁 10
💬 1
📌 1
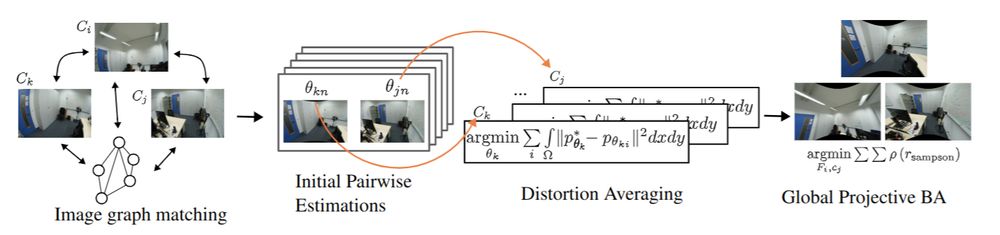
The code for our #CVPR2025 paper, PRaDA: Projective Radial Distortion Averaging, is now out!
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
09.07.2025 13:54 —
👍 12
🔁 5
💬 1
📌 0
Can we match vision and language representations without any supervision or paired data?
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
03.06.2025 09:27 —
👍 27
🔁 12
💬 1
📌 0
Can you train a model for pose estimation directly on casual videos without supervision?
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
13.05.2025 08:11 —
👍 25
🔁 10
💬 1
📌 1
Very glad to announce that our "Finsler Multi-Dimensional Scaling" paper, accepted at #CVPR2025, is now on Arxiv! arxiv.org/abs/2503.18010
24.03.2025 23:06 —
👍 8
🔁 3
💬 1
📌 0

We are thrilled to have 12 papers accepted to #CVPR2025. Thanks to all our students and collaborators for this great achievement!
For more details check out cvg.cit.tum.de
13.03.2025 13:11 —
👍 36
🔁 12
💬 1
📌 2
🥳 Thrilled to announce that our work, "4Deform: Neural Surface Deformation for Robust Shape Interpolation," has been accepted to #CVPR2025 🙌
💻 Check our project page: 4deform.github.io
👏 Great thanks to my amazing co-authors. @ricmarin.bsky.social @dongliangcao.bsky.social @dcremers.bsky.social
03.03.2025 18:18 —
👍 9
🔁 3
💬 0
📌 0
in practice the angle between the observation ray and principal axis will always be limited by the camera fov, so not sure how much difference the fix would do tbh
but yeah, eg if translation noise is the main source of error I could see midpoint being optimal!
21.02.2025 23:33 —
👍 1
🔁 0
💬 1
📌 0

consider me nerd-sniped 😅 one benefit I can see for the reprojection error is that it gives a better tradeoff when cameras are at different distances.
Here's a 3-view example:
blue=GT point
red=optimal projection error
green=optimal point-to-ray distance
all views have the same observation noise
21.02.2025 18:24 —
👍 1
🔁 0
💬 1
📌 0
🥳Thrilled to share our work, "Implicit Neural Surface Deformation with Explicit Velocity Fields", accepted at #ICLR2025 👏
code is available at: github.com/Sangluisme/I...
😊Huge thanks to my amazing co-authors. @dongliangcao.bsky.social @dcremers.bsky.social
👏Special thanks to @ricmarin.bsky.social
23.01.2025 17:22 —
👍 20
🔁 6
💬 0
📌 0
Indeed - everyone had a blast - thank you all for the great talks, discussions and Ski/snowboarding!
16.01.2025 17:56 —
👍 46
🔁 4
💬 1
📌 3

DiffCD: A Symmetric Differentiable Chamfer Distance for Neural Implicit Surface Fitting, presented at #ECCV2024
Paper: arxiv.org/abs/2407.17058
Code/project: github.com/linusnie/dif...
08.01.2025 12:30 —
👍 0
🔁 0
💬 0
📌 0


Reposting some of my prior works here on this site :) "Semidefinite Relaxations for Robust Multiview Triangulation" at #CVPR2023!
paper: arxiv.org/abs/2301.11431
code: github.com/Linusnie/rob...
08.01.2025 12:29 —
👍 2
🔁 0
💬 0
📌 0
















