
You can now process Hebrew archival documents with Qwen 3 VL =) --- Will be using this to finetune further on handwritten Hebrew. Metrics are on the test set that is fairly close in style and structure to the training data. I tested on out-of-training edge cases and it worked (Link to model below)
30.10.2025 13:16 — 👍 5 🔁 0 💬 1 📌 0
Does anyone have a dataset of 1,000 + pages of handwritten text on Transkribus that they want to use for finetuning a VLM? If so, please let me know. This would be for any language and any script.
27.10.2025 17:56 — 👍 3 🔁 5 💬 0 📌 0
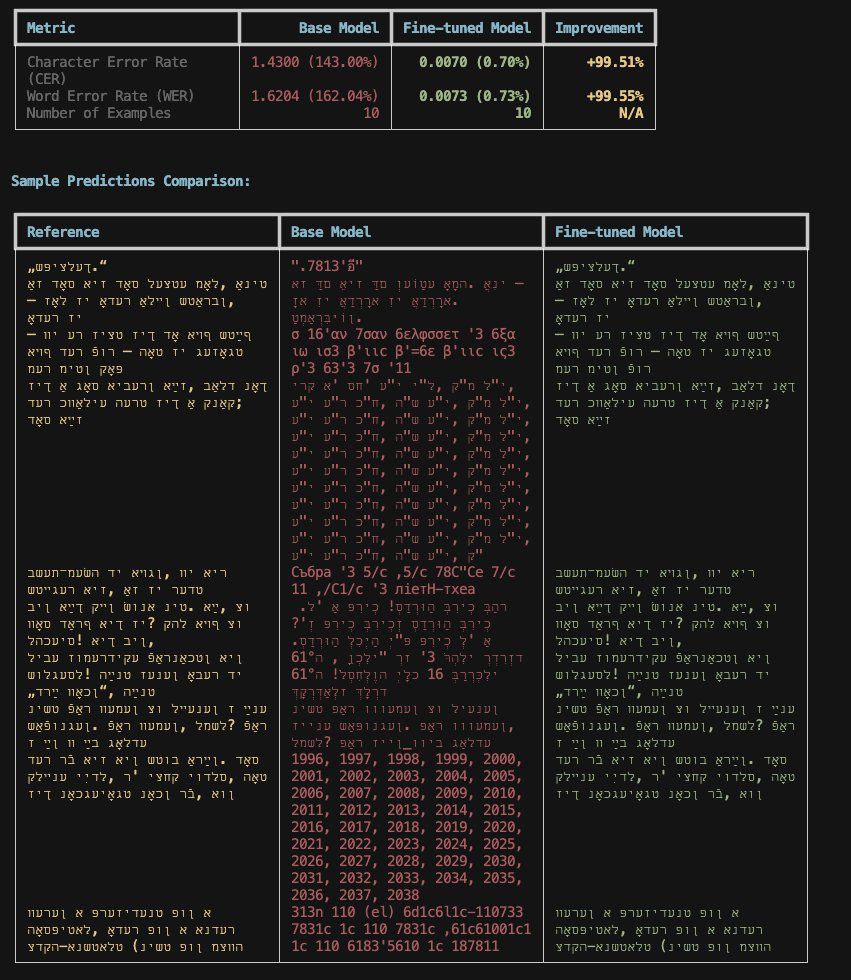
More coming soon but finetuned Qwen 3 VL-8B on 150k lines of synthetic Yiddish typed and handwritten data. Results are pretty amazing. Even on the harder heldout set it gets a CER of 1% and a WER of 2%. Preparing page-level dataset and finetunes now, thanks to the John Locke Jr.
24.10.2025 20:14 — 👍 9 🔁 1 💬 0 📌 0

2B model: huggingface.co/small-models...
24.10.2025 14:59 — 👍 2 🔁 0 💬 0 📌 0

4B model: huggingface.co/small-models...
24.10.2025 14:59 — 👍 3 🔁 0 💬 1 📌 0

8B model: huggingface.co/small-models...
24.10.2025 14:59 — 👍 1 🔁 0 💬 1 📌 0
Over the last 24 hours, I have finetuned three Qwen3-VL models (2B, 4B, and 8B) on the CATmuS dataset on @hf.co . The first version of the models are now available on the Small Models for GLAM organization with @danielvanstrien.bsky.social (Links below) Working on improving them further.
24.10.2025 14:59 — 👍 10 🔁 2 💬 1 📌 0

Logs showing ocr progress
DeepSeek-OCR just got vLLM support 🚀
Currently processing @natlibscot.bsky.social's 27,915-page handbook collection with one command.
Processing at ~350 images/sec on A100
Using @hf.co Jobs + uv - zero setup batch OCR!
Will share final time + cost when done!
22.10.2025 19:20 — 👍 17 🔁 2 💬 1 📌 0

GitHub - wjbmattingly/dots-ocr-editor
Contribute to wjbmattingly/dots-ocr-editor development by creating an account on GitHub.
Want an easy way to edit the output from Dots.OCR? Introducing Dots.OCR editor, an easy way to edit outputs from the model.
Features:
1) Edit bounding boxes
2) Edit OCR
3) Edit reading order
4) Group sections (good for newspapers)
Vibe coded with Claude 4.5
github.com/wjbmattingly...
21.10.2025 16:21 — 👍 6 🔁 2 💬 0 📌 0
Small models work great for GLAM but there aren't enough examples!
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
16.10.2025 13:22 — 👍 11 🔁 6 💬 0 📌 0

🚨Job ALERT🚨! My old postdoc is available!
I cannot emphasize enough how much a life-altering position this was for me. It gave me the experience that I needed for my current role. As a postdoc, I was able to define my projects and acquire a lot of new skills as well as refine some I already had.
24.09.2025 13:50 — 👍 6 🔁 7 💬 0 📌 0
DHQ: Digital Humanities Quarterly: News
Excited to be co-editing a special issue of @dhquarterly.bsky.social on Artificial Intelligence for Digital Humanities: Research problems and critical approaches
dhq.digitalhumanities.org/news/news.html
We're inviting abstracts now - please feel free to reach out with any questions!
09.09.2025 20:28 — 👍 21 🔁 10 💬 0 📌 1
Ahh no worries!! Thanks! I hope you had a nice vacation
25.08.2025 14:55 — 👍 0 🔁 0 💬 0 📌 0

Something I've realized over the last couple weeks with finetuning various VLMs is that we just need more data. Unfortunately, that takes a lot of time. That's why I'm returning to my synthetic HTR workflow. This will be packaged now and expanded to work with other low-resource languages. Stay tuned
14.08.2025 16:08 — 👍 10 🔁 0 💬 0 📌 0
No problem! It's hard to fit a good answer in 300 characters =) Feel free to DM me any time.
13.08.2025 20:02 — 👍 0 🔁 0 💬 0 📌 0
Also, if you are doing a full finetune vs LoRa adapters is another thing to consider. Also, depends on the model arch.
13.08.2025 20:00 — 👍 1 🔁 0 💬 0 📌 0
I hate saying this, but it's true: it depends. For line-level medieval Latin (out of scope, but small problem size), 1-3k examples seems to be fine. For page level out of scope problems, it really becomes more challenging and very model dependent, 1-10k in my experience.
13.08.2025 19:59 — 👍 1 🔁 0 💬 1 📌 0

I've been getting asked training scripts when a new VLM drops. Instead of scripts, I'm going to start updating this new Python package. It's not fancy. It's for full finetunes. This was how I first trained Qwen 2 VL last year.
13.08.2025 19:38 — 👍 14 🔁 2 💬 1 📌 0

Let's go! Training LFM2-VL 1.6B on Catmus dataset on @hf.co now. Will start posting some benchmarks on this model soon.
13.08.2025 16:58 — 👍 4 🔁 1 💬 0 📌 0

Training on full catmus now and the results after first checkpoint are very promising. Character and massive word-level improvement.
13.08.2025 15:53 — 👍 3 🔁 1 💬 1 📌 0
Thanks!! =)
13.08.2025 15:52 — 👍 1 🔁 0 💬 0 📌 0
Congrats on the new job!!
13.08.2025 15:13 — 👍 0 🔁 0 💬 0 📌 0

LiquidAI cooked with LFM2-VL. At the risk of sounding like an X AI influencer, don't sleep on this model. I'm finetuning right now on Catmus. A small test over night on only 3k examples is showing remarkable improvement. Training now on 150k samples. I see this as potentially replacing TrOCR.
13.08.2025 15:01 — 👍 10 🔁 2 💬 1 📌 0

New super lightweight VLM just dropped from Liquid AI in two flavors: 450M and 1.6B. Both models can work out-of-the-box with medieval Latin at the line level. I'm fine-tuning on Catmus/medieval right now on an h200.
12.08.2025 19:18 — 👍 9 🔁 3 💬 1 📌 0
Awesome!!
12.08.2025 11:26 — 👍 1 🔁 0 💬 0 📌 0
With #IMMARKUS, you can already use popular AI services for image transcription. Now, you can also use them for translation! Transcribe a historic source, select the annotation—and translate it with a click.
12.08.2025 09:48 — 👍 7 🔁 2 💬 1 📌 0

GLM-4.5V with line-level transcription of medieval Latin in Caroline Miniscule. Inference was run through @hf.co Inferencevia Novita.
12.08.2025 01:50 — 👍 4 🔁 1 💬 0 📌 0
Qwen 3-4B Thinking finetune nearly ready to share. It can convert unstructured natural language, non-linkedart JSON, and HTML into LinkedArt JSON.
11.08.2025 20:07 — 👍 5 🔁 0 💬 0 📌 0
I need to get back to my Voynich work soon! I will finally have time in a couple months I think.
09.08.2025 03:36 — 👍 1 🔁 0 💬 0 📌 0
Head of Post-Training @LiquidAI
📝 Blog: https://mlabonne.github.io/blog
💻 GitHub: https://github.com/mlabonne
🤗 HF: https://huggingface.co/mlabonne
history and bureaucracy in the sinosphere
Dr. of CL | @cl_uzh | AIncient Studies Lab @UZH | @ImpressoProject | Bullinger Digital | Referee @SwissIceHockey |🟢|🍽️| 🐘 @phillipstroebel@techhub.social | #digitalhumanities | #digitalhistory | #digitalclassics
Digital librarian for the Perseus Digital Library for oh so many years. Dogs rock, cats rock, rocks rock (raising a budding geologist after all), being a Mom rocks, and so many other things rock (but in no particular order!)
A collector of things worth knowing and things not worth knowing. Freelance software developer. Web/UI/Maps/Visualization/Image Annotation/Open Source. https://rainersimon.io
Digital Humanities @ University of Stuttgart, Themen: Computational Literary Studies, Public Humanities, Erzählforschung, Digital Gender Studies.
Medievalist, Latinist, paleographer, Episcopalian, with novel in progress. DC-based, with beagle. Web: ruffnotes.org
Cover image is from the Reichenau Gospels, Walters Art Museum MS W7 fol. 7r.
Scribbler and data journalist. https://joshnicholas.com
Digital Humanities | NLP | Computational Theology
Now: Institute for Digital Humanities, University of Göttingen.
Before: Digital Academy, Göttingen Academy of Sciences and Humanities.
Before Before: The list is long...
Bayesian librarian & attribution historian
Boolean engineering since 1995
P&RP my own : about citation, information literacy & tabletop role-playing games
«Citez-vous les uns les autres»
Hon Senior Research Fellow at the University of Glasgow. Writes and researches on medieval history and manuscripts, archives, digital humanities, and the history of freemasonry. Heavily involved with the 'People of 1381' project: www.1381.online.
Assistant Professor & PI of ERC CoG-project #glossit
at @universityofgraz.bsky.social Department for Digital Humanities
Member of @ya-oeaw.bsky.social
Glossing, Digital Humanities, Celtic Studies, Language Contact, Historical Linguistics
Roman historian, digital humanist & contributor at Hyperallergic
Book 📕 Strike: Labor, Unions & Resistance in the Roman Empire (Feb. 2025) : https://yalebooks.yale.edu/book/9780300273144/strike/
Pasts Imperfect:
https://pasts-imperfect.ghost.io/
Acting Director of Library Services, University of Leeds | RLUK Digital Shift | IIIF Outreach | Open Research | Research Culture | Digital Creativity | Knowledge Equity | Coffee and Cake | Personal views | ORCID 0000-0002-6969-7382
People/Places; Spatial/Cultural Informatics; Arch/Heritage Sci; Data & Design. PhD - WIP. Views own. Digital Trustee: @DunollieOban. Advisory Board: @goodorgcic.bsky.social Director/Trustee: @archscot.bsky.social (she/her)
I like to make simple solutions to complex problems.
https://epoz.org/
Senior Researcher at FIZ Karlsruhe
NFDI4Culture
∴ Digital Art History ∴ Knowledge Engineering ∴ Yoga ∴
Prof of linguistics. 🇦🇺/🇺🇸; Australian languages, historical linguistics, Voynich Manuscript
 30.10.2025 13:16 — 👍 1 🔁 0 💬 0 📌 0
30.10.2025 13:16 — 👍 1 🔁 0 💬 0 📌 0






















