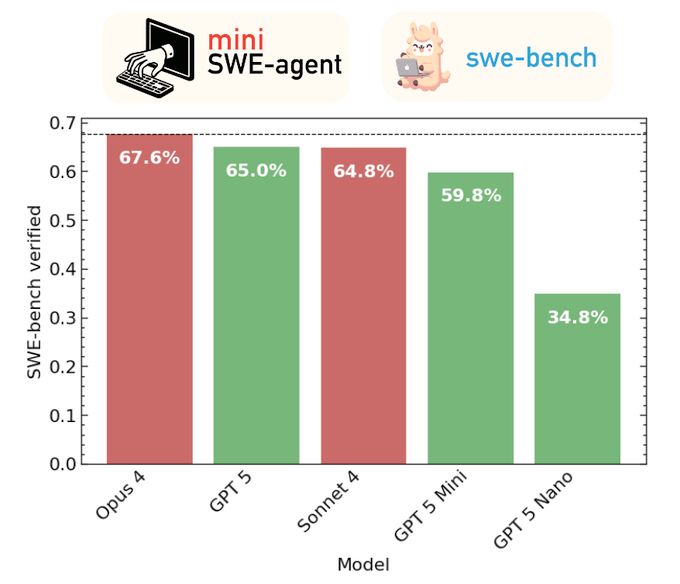
SWE-bench scores (same as text)
We evaluated the new GPT models with a minimal agent on SWE-bench verified. GPT-5 scores 65%, mini 60%, nano 35%. Still behind Opus 5 (68%), on par with Sonnet 4 (65%). But a lot cheaper, especially mini! Complete cost breakdown + details in 🧵
08.08.2025 15:20 —
👍 0
🔁 1
💬 1
📌 0

Do language models have algorithmic creativity?
To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!
algotune.io
02.07.2025 14:36 —
👍 3
🔁 1
💬 0
📌 0

I have a post where I talk about how to build good LM benchmarks. I've had to edit the part where I talk about how I think you should try to make your benchmark hard, multiple times now, since LM abilities are accelerating so rapidly.
11.05.2025 21:25 —
👍 8
🔁 1
💬 1
📌 0

Can language model systems autonomously complete entire tasks end-to-end?
In our next Expert Exchange webinar, Ofir Press explores autonomous LM systems for software engineering, featuring SWE-bench & SWE-agent—used by OpenAI, Meta, & more.
🔗 pytorch.org/autonomous-l...
#PyTorch #AI #OpenSource
05.05.2025 18:32 —
👍 2
🔁 1
💬 1
📌 0
I prompted Claude 3.7 to use Javascript to animate a ride in the Kingda Ka rollercoaster at Six Flags in New Jersey. I did not give it any images/videos from the ride, or any other additional info, and it has no web access.
04.03.2025 15:42 —
👍 4
🔁 0
💬 0
📌 0

A peek into a possible future of Python in the browser - Łukasz Langa
My Python code was too slow, so I made it faster with Python. For some definition of “Python”.
I spent last week in Valtournenche with @antocuni.bsky.social and Hood Chatham and managed to use SPy to accelerate my #Python code in the browser. It's too early for general adoption, but not too early to get excited!
lukasz.langa.pl/f37aa97a-9ea...
24.02.2025 19:10 —
👍 20
🔁 7
💬 2
📌 0

SWE-agent 1.0 is the open-source SOTA on SWE-bench Lite! Tons of new features: massively parallel runs; cloud-based deployment; extensive configurability with tool bundles; new command line interface & utilities.
github.com/swe-agent/sw...
13.02.2025 15:37 —
👍 1
🔁 0
💬 0
📌 0
Search Jobs | Microsoft Careers
Hi, the Microsoft Translator research team is looking for an intern for the summer. If you a PhD student in Machine Translation, Natural Language Processing, or related, check it out: aka.ms/mtintern
28.01.2025 17:55 —
👍 5
🔁 4
💬 0
📌 0

SWE-bench Multimodal evaluation code is out now!
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
17.01.2025 09:06 —
👍 8
🔁 1
💬 0
📌 0
YouTube video by Jay Alammar
SWE-Bench authors reflect on the state of LLM agents at Neurips 2024
SWE-Bench has been one of the most important tasks measuring the progress of agents tackling software engineering in 2024. I caught up with two of its creators, @ofirpress.bsky.social and Carlos E. Jimenez to share their ideas on the state of LLM-backed agents.
www.youtube.com/watch?v=bivZ...
13.01.2025 14:29 —
👍 3
🔁 2
💬 0
📌 0
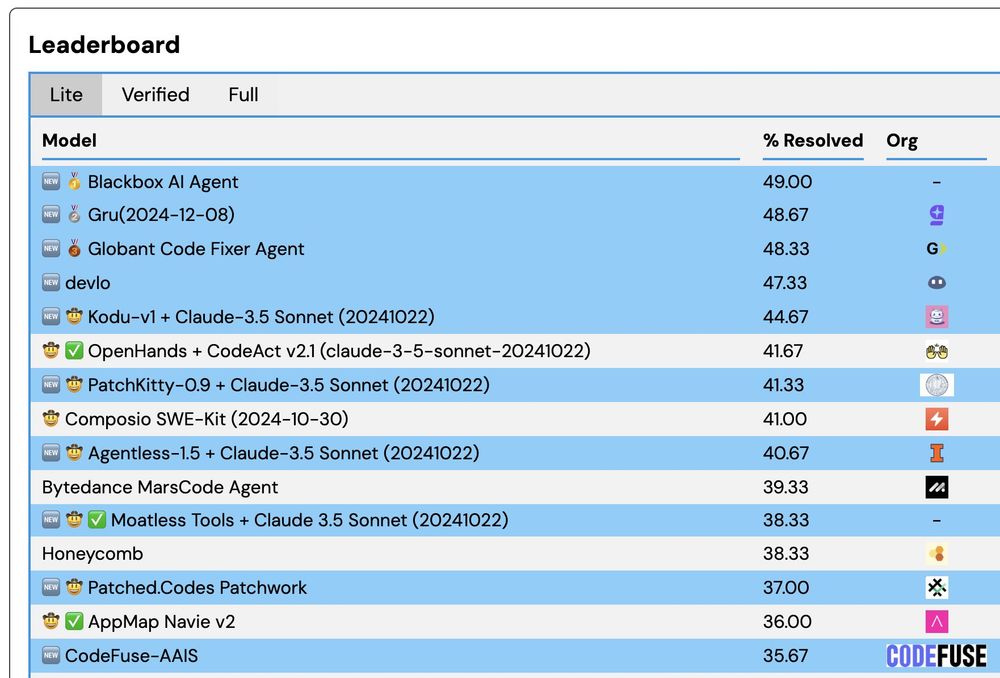
We just updated the SWE-bench leaderboard with *14* new submissions! Congrats to blackbox.ai & aide.dev on setting new SoTA scores on Lite & Verified!
Congrats to Google on your first submission!
Credit to John Yang, Carlos E. Jimeneze & Kilian Lieret who maintain SWE-bench/SWE-agent
08.01.2025 20:31 —
👍 6
🔁 0
💬 0
📌 0

When we started working on SWE-agent the top score on SWE-bench was 2%. I told the team that if we got 6%, we'd have a good paper, and I'd buy everyone gelato.
I thought 6% was very ambitious but doable.
We ended up getting 12% 🤯 so I cooked dinner for everyone.
02.01.2025 10:05 —
👍 4
🔁 0
💬 0
📌 0
"A canopy bed galloping across the savanna" #Veo2
23.12.2024 20:13 —
👍 19
🔁 4
💬 0
📌 0
Until recently, we didn't have models that were *trained* for tough multi-turn tasks like SWE-bench.
My hypothesis: now, with the new Gemini and O3, we're finally seeing how much accuracy can improve when models are trained for these tasks.
This is just the beginning!
20.12.2024 21:10 —
👍 11
🔁 0
💬 4
📌 0
I hope this trend continues into 2025.
Healthy competition & knowledge sharing through papers will drive even faster progress.
I can't wait for open source 40B models that get 40% on SWE-bench Lite and 6% on SciCode. Hardware won't be as much of a limiting factor as we thought.
18.12.2024 20:10 —
👍 3
🔁 0
💬 1
📌 0
When ChatGPT came out, and for a year afterwards, it seemed like OpenAI had a huge moat that was insurmountable.
Now Anthropic is matching their performance, Google and Meta are close, and it seems like the academic/open source community understands how to build these models ->
18.12.2024 20:10 —
👍 5
🔁 1
💬 1
📌 0

WebDev Arena
New leaderboard from the [Chatbot Arena](https://lmarena.ai/) team (formerly known as LMSYS), this time focused on evaluating how good different models are at "web development" - though it turns out t...
The team behind the Chatbot Arena LLM leaderboard just released a new variant: web.lmarena.ai
This one tests models on their React, TypeScript and Tailwind abilities. My notes (including a leaked copy of the system prompt) here: simonwillison.net/2024/Dec/16/...
16.12.2024 18:40 —
👍 37
🔁 4
💬 0
📌 0

We're presenting SWE-agent tomorrow (Wed) at the 11AM poster session, East Exhibit Hall A-C #1000.
We're going to talk about a lot of upcoming SWE-agent features. Join @jyangballin @_carlosejimenez @KLieret and me. I also have a bunch of SWE-agent stickers to hand out :)
10.12.2024 18:16 —
👍 8
🔁 3
💬 0
📌 0
YouTube video by Matthew Berman
SWE-Agent Team Interview - Agents, Programming, and Benchmarks!
We chatted with Matthew Berman about the origins of SWE-bench / SWE-agent and how we're thinking about the current agent landscape. www.youtube.com/watch?v=fcr8...
07.12.2024 19:50 —
👍 3
🔁 0
💬 0
📌 0

EnIGMA sets new state-of-the-art results on @stanfordnlp.bsky.social's CyBench, which tasks LMs to find security vulnerabilities.
Such Capture The Flag tasks make for challenging benchmarks—demanding high-level reasoning, persistence and adaptability. Even expert humans find them hard!
05.12.2024 17:45 —
👍 6
🔁 4
💬 1
📌 0

I'm on the academic job market!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
04.12.2024 16:52 —
👍 22
🔁 4
💬 1
📌 0
x.com
Source: x.com/dangengdg/st...
04.12.2024 03:58 —
👍 1
🔁 0
💬 0
📌 0
Super cool work from Daniel Geng: "What happens when you train a video generation model to be conditioned on motion?
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities."
motion-prompting.github.io
04.12.2024 03:58 —
👍 7
🔁 0
💬 1
📌 0
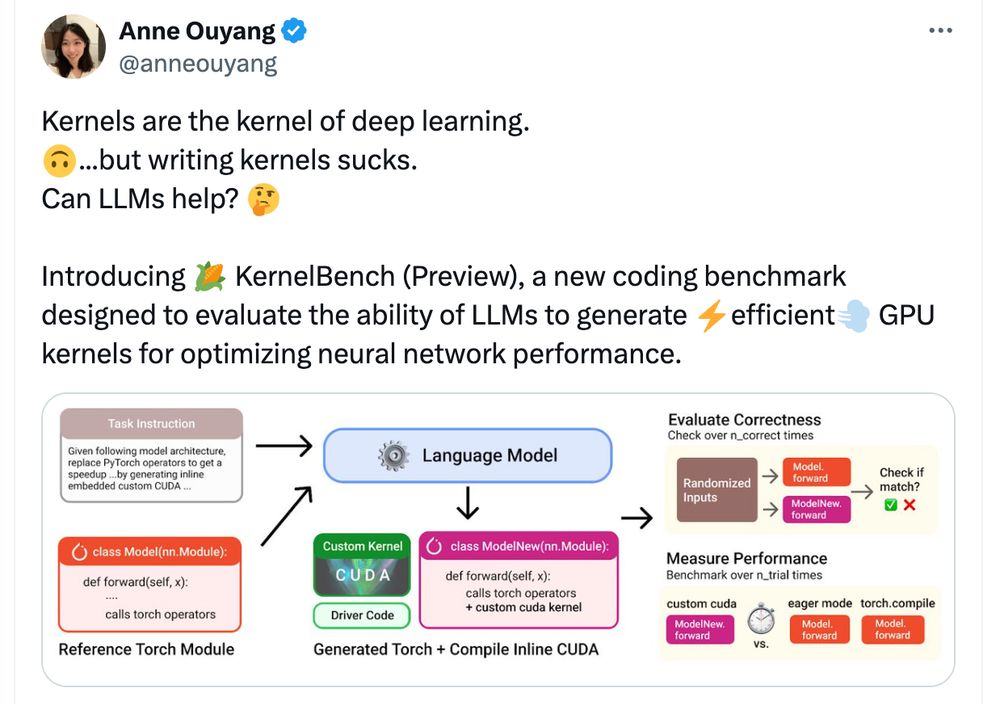
Cool benchmark I found through Twitter. (I am not involved in this work) scalingintelligence.stanford.edu/blogs/kernel...
03.12.2024 23:17 —
👍 2
🔁 0
💬 0
📌 0

Lots of new SWEbench.com results have just been posted. Congrats everyone on the amazing results!
03.12.2024 22:08 —
👍 4
🔁 0
💬 0
📌 0

The Amazon thing that summarizes all of the reviews into both a sentence and a bullet point list is so awesome and I wish I could figure out a way to make a benchmark out of it :)
01.12.2024 05:18 —
👍 3
🔁 0
💬 0
📌 0

Quantized SWE-bench coming soon?
28.11.2024 20:04 —
👍 18
🔁 0
💬 0
📌 0
Thanks so much Jay!!
27.11.2024 01:15 —
👍 0
🔁 0
💬 0
📌 0






