

📢We’re taking your questions now on Reddit for tomorrow’s AMA!
Ask us anything about OLMo, our family of fully-open language models. Our researchers will be on hand to answer them Thursday, May 8 at 8am PST.
📢We’re taking your questions now on Reddit for tomorrow’s AMA!
Ask us anything about OLMo, our family of fully-open language models. Our researchers will be on hand to answer them Thursday, May 8 at 8am PST.
Right! "kick the bucket" is too infrequent, but there are more common idiomatic expressions like "in the long run" or "on the other hand." In general I would say non-idiomatic MWEs are more common, like uses of prepositions ("depend on") which require memorization.
21.03.2025 20:59 — 👍 4 🔁 0 💬 0 📌 0
Humans store thousands of multi-word expressions like "of course" in their mental lexicon, but current tokenizers don't support multi-word tokens.
Enter SuperBPE, a tokenizer that lifts this restriction and brings substantial gains in efficiency and performance! 🚀
Details 👇
Hell yeah superwords. (I wanna call em supertokens, but I didn't develop them.)
21.03.2025 18:17 — 👍 2 🔁 1 💬 0 📌 0Tokenizers govern the allocation of computation. It's a waste to spend a whole token of compute predicting the "way" in "By the way". SuperBPE redirects that compute to predict more difficult tokens, leading to wins on downstream tasks!
21.03.2025 18:31 — 👍 4 🔁 1 💬 0 📌 0nothing beats writing papers together with co-1st @jon.jon.ke — the mention didn't work the first time!
21.03.2025 18:26 — 👍 3 🔁 0 💬 0 📌 0a small change to building your BPE tokenizer gets your pretrained LM 8 MMLU points (for example) and 27% inference-time efficiency boost ...
21.03.2025 16:52 — 👍 11 🔁 1 💬 1 📌 0
Screenshot of tokenizer demo from our blog post.
Play around with our tokenizers here! superbpe.github.io 🚀
Paper: arxiv.org/abs/2503.13423
HF models & tokenizers: tinyurl.com/superbpe
This work would not have been possible w/o co-1st 🌟@jon.jon.ke🌟, @valentinhofmann.bsky.social @sewoong79.bsky.social @nlpnoah.bsky.social @yejinchoinka.bsky.social

Example usage of SuperBPE model & tokenizer in HuggingFace transformers.
SuperBPE🚀 is a seamless replacement for BPE in modern LM development pipelines, requiring no changes to the model architecture or training framework. You can use it in HuggingFace right now!
21.03.2025 16:48 — 👍 6 🔁 0 💬 2 📌 0
Histogram of per-token losses for BPE and SuperBPE models. The SuperBPE model makes fewer predictions with very high or very low loss.
Why does SuperBPE🚀 work? We find that loss is distributed more uniformly over tokens in SuperBPE models. They are less overfit to high-frequency, easy-to-predict tokens (e.g. “way” after “By the”), and at the same time master a much broader set of language phenomena.
21.03.2025 16:48 — 👍 6 🔁 0 💬 1 📌 0
Table showing the per-task performance of 8B BPE and SuperBPE models.
Then we pretrain 8B models from scratch with BPE and SuperBPE🚀, fixing everything about the training setup except the tokenizer. We see +4% on avg📈 across 30 downstream tasks, and win on 25/30 of individual tasks, while also being 27% more efficient at inference time.
21.03.2025 16:48 — 👍 5 🔁 0 💬 1 📌 0
Figure showing how encoding efficiency scales with vocabulary size. SuperBPE encodes text much more efficiently than BPE!
What can we gain from less restrictive tokenization? To find out, we developed SuperBPE🚀, which learns subword *and* superword tokens. SuperBPE dramatically improves encoding efficiency over BPE — at a fixed vocab size of 200k, SuperBPE reduces sequence length by 33% on average!
21.03.2025 16:48 — 👍 4 🔁 0 💬 1 📌 0E.g. “math teacher” = “Mathelehrer” in German. At the extreme, Chinese *doesn’t use whitespace at all*, so its tokens can span many words — yet this has seemingly not hindered LMs like @deepseek_ai from learning it!
21.03.2025 16:48 — 👍 6 🔁 0 💬 1 📌 0This started with a curiosity💡: why do all LLMs limit tokens to *parts* of whitespace-delimited words? After all, many word sequences (e.g. “by the way”) function as single units. Different languages can also express the same meaning in one or several words.
21.03.2025 16:48 — 👍 7 🔁 0 💬 1 📌 0
Segmentation of the sentence "By the way, I am a fan of the Milky Way" under BPE and SuperBPE.
We created SuperBPE🚀, a *superword* tokenizer that includes tokens spanning multiple words.
When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks (+8% MMLU), while also being 27% more efficient at inference time.🧵

We observe that the merge list of LLAMA, LLAMA 3, GEMMA, and MISTRAL contain clusters of redundant merge rules. For instance, in the LLAMA 3 merge list, we see the sequence of merges _ the, _t he, and _th e, as well as _ and, _a nd, and _an d. Because the merge path for every token is unique, it is impossible for more than one of these merges to ever be used, and we empirically verify this by applying the tokenizer to a large amount of text. We find that this is an artifact of the conversion from sentencepiece to Huggingface tokenizers format. To construct the merge list, the conversion algorithm naively combines every pair of tokens in the vocabulary, and then sorts them by token ID, which represents order of creation. While this is functionally correct, because the redundant merges are not products of the BPE algorithm (i.e., they do not actually represent the most-likely next-merge), we need to remove them to apply our algorithm. To do this, we do some simple pre-processing: for every cluster of redundant merges, we record the path of merges that achieves each merge; the earliest path is the one that would be taken, so we keep that merge and remove the rest. As an aside, this means that a tokenizer’s merge list can be completely reconstructed from its vocabulary list ordered by token creation. Given only the resulting token at each time step, we can derive the corresponding merge.
This is also addressed in the appendix of @alisawuffles.bsky.social and colleagues' paper on BPE mixture inference. I think it might have been discovered by @soldaini.net if I'm not mistaken.
arxiv.org/abs/2407.16607

poster for paper
excited to be at #NeurIPS2024! I'll be presenting our data mixture inference attack 🗓️ Thu 4:30pm w/ @jon.jon.ke — stop by to learn what trained tokenizers reveal about LLM development (‼️) and chat about all things tokenizers.
🔗 arxiv.org/abs/2407.16607
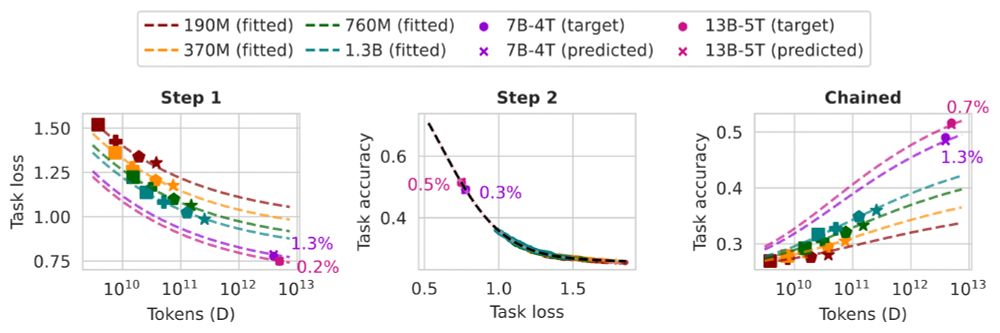
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.

🚨I too am on the job market‼️🤯
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me

We just updated the OLMo repo at github.com/allenai/OLMo!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
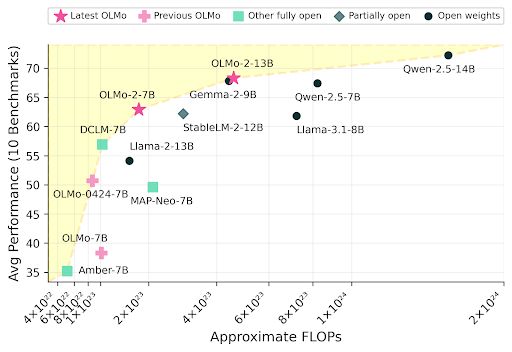
The OLMo 2 models sit at the Pareto frontier of training FLOPs vs model average performance.
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
26.11.2024 20:51 — 👍 151 🔁 36 💬 5 📌 12
OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
🙋🏻♀️ ty!
25.11.2024 17:09 — 👍 1 🔁 0 💬 0 📌 0
No one can explain stochastic gradient descent better than this panda.
24.11.2024 15:04 — 👍 216 🔁 32 💬 10 📌 6
Reading the TÜLU 3 paper from @ai2.bsky.social. It's refreshing to see a research lab treating AI as a real science with full reports, data, code, logs, evals.
Paper: allenai.org/papers/tulu-...
Demo: playground.allenai.org
Code: github.com/allenai/open...
Eval: github.com/allenai/olmes
Notes
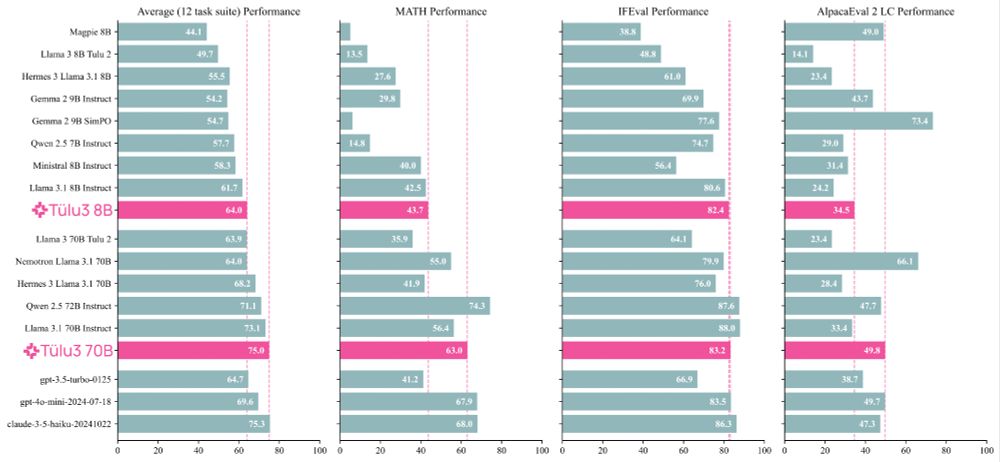
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇


I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
