MCP Catalog and Toolkit
Learn about Docker's MCP catalog on Docker Hub
🚀 LM Studio now works out of the box with the Docker MCP Toolkit!
Skip the messy configs—connect MCP servers in one click to LM Studio.
🛠️ Build agents easily & securely with Docker.
🔗 docs.docker.com/ai/mcp-catal...
#DockerAI #MCP #DevTools #LMStudio
21.07.2025 22:03 — 👍 8 🔁 1 💬 0 📌 0
👀
13.03.2025 18:36 — 👍 4 🔁 0 💬 0 📌 0
💯! @mcuban.bsky.social you should try it out :-)
18.02.2025 00:32 — 👍 1 🔁 0 💬 0 📌 0
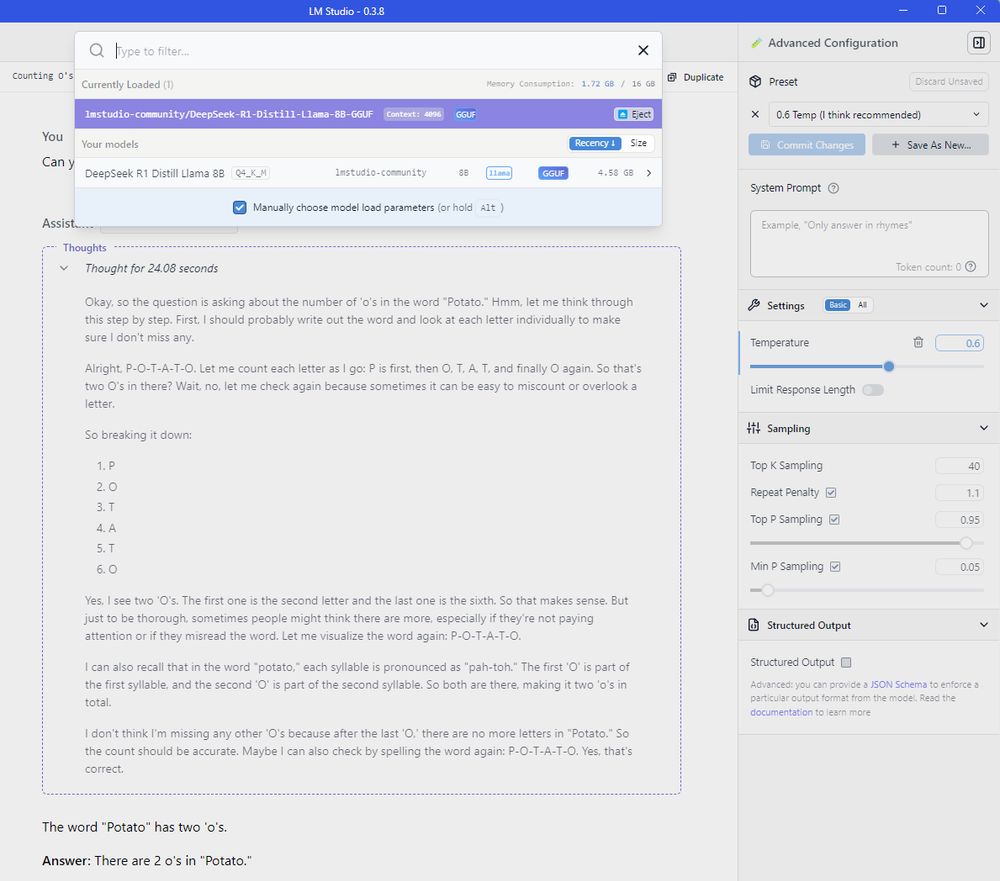
LM Studio with DeepSeek R1 Distill Llama 8B Q4_K_M correctly answering a question about how many O's there are in Potato
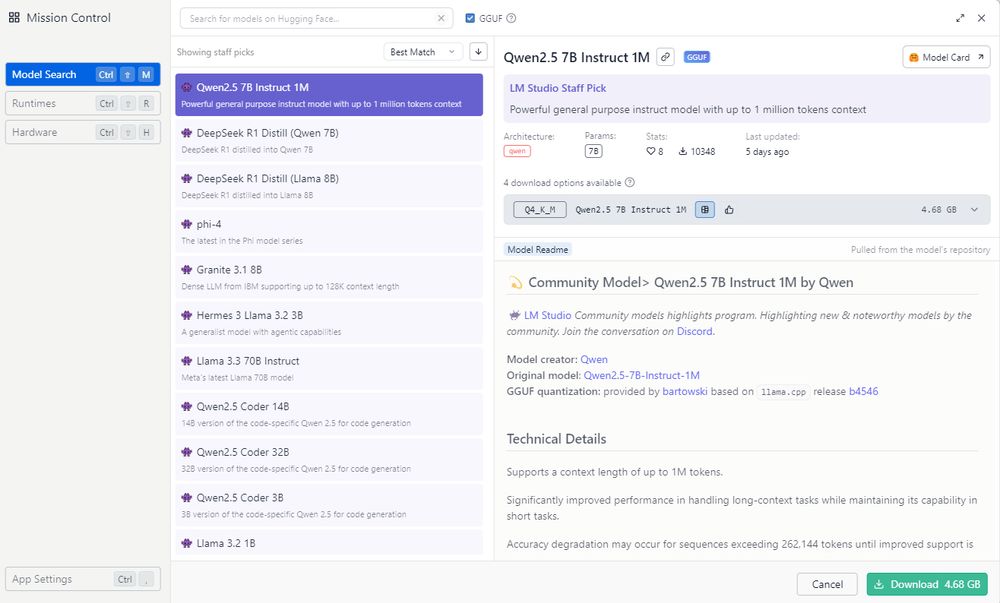
LM Studio Mission Control, showing a searchable list of Models for download.
I was expecting this to take me a couple of hours to set up (with me getting annoyed about undocumented requirements on Github), but no, a few mins including the mini-model download.
LM Studio is very beginner friendly.
🥔⚖️⭕⭕
30.01.2025 10:56 — 👍 8 🔁 1 💬 2 📌 0
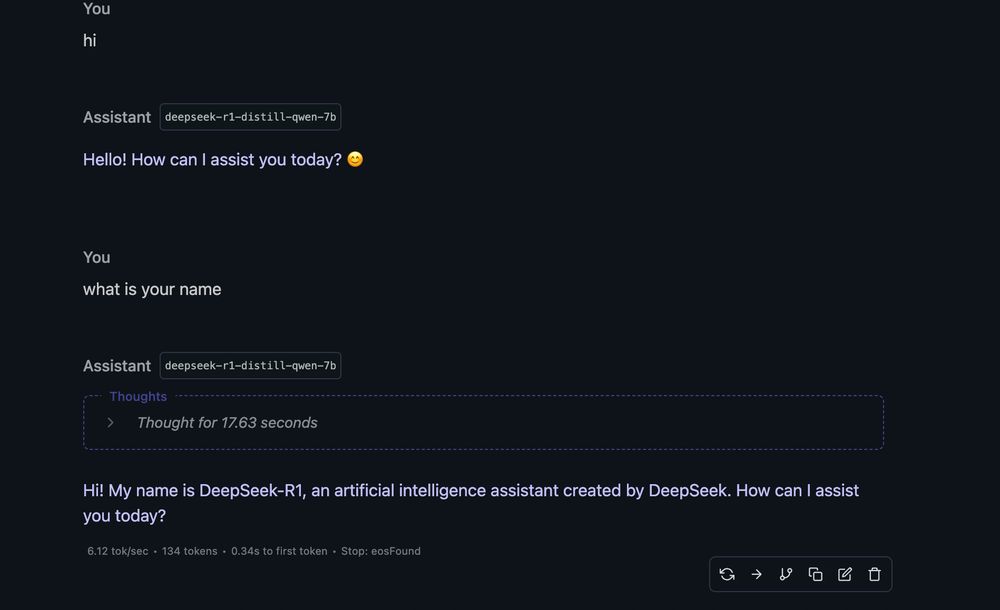
E tai, o Modelo de IA Deepseek rodando no meu MacBook Air M3 16Gb a 6 tokens por segundo LOCALMENTE.
É muito simples, basta baixar o LM Studio , procurar pelo modelo, baixar (5GB) e rodar.
Vc tem uma IA de ponta 100% offline rodando no seu computador
Surreal.
27.01.2025 15:19 — 👍 50 🔁 5 💬 3 📌 2
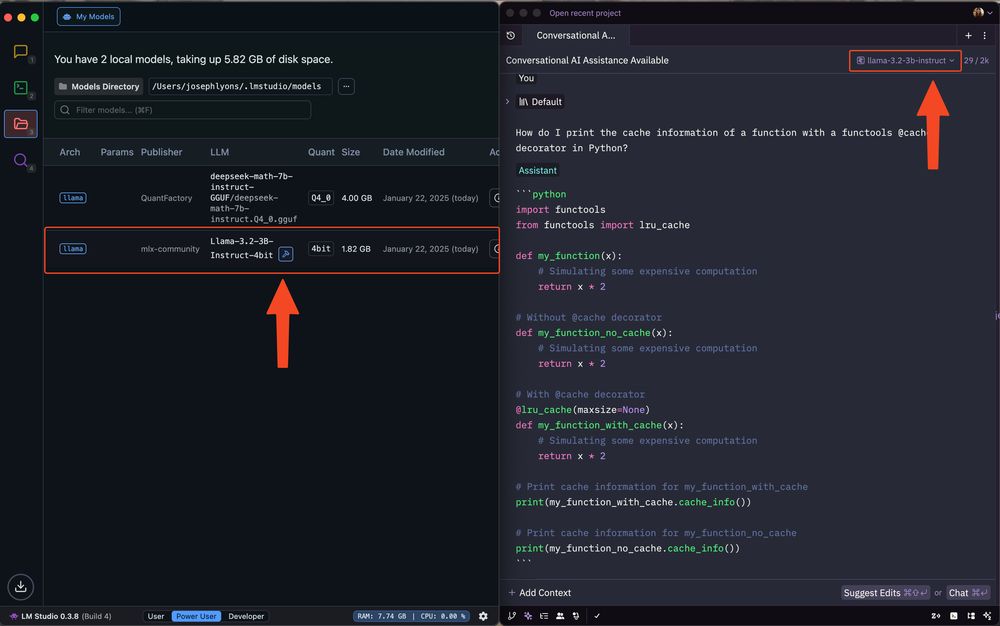
🚀 Zed v0.170 is out!
Zed's assistant can now be configured to run models from @lmstudio.
1. Install LM Studio
2. Download models in the app
3. Run the server via `lms server start`
4. Configure LM Studio in Zed's assistant configuration panel
5. Pick your model in Zed's assistant
22.01.2025 21:32 — 👍 41 🔁 7 💬 1 📌 0
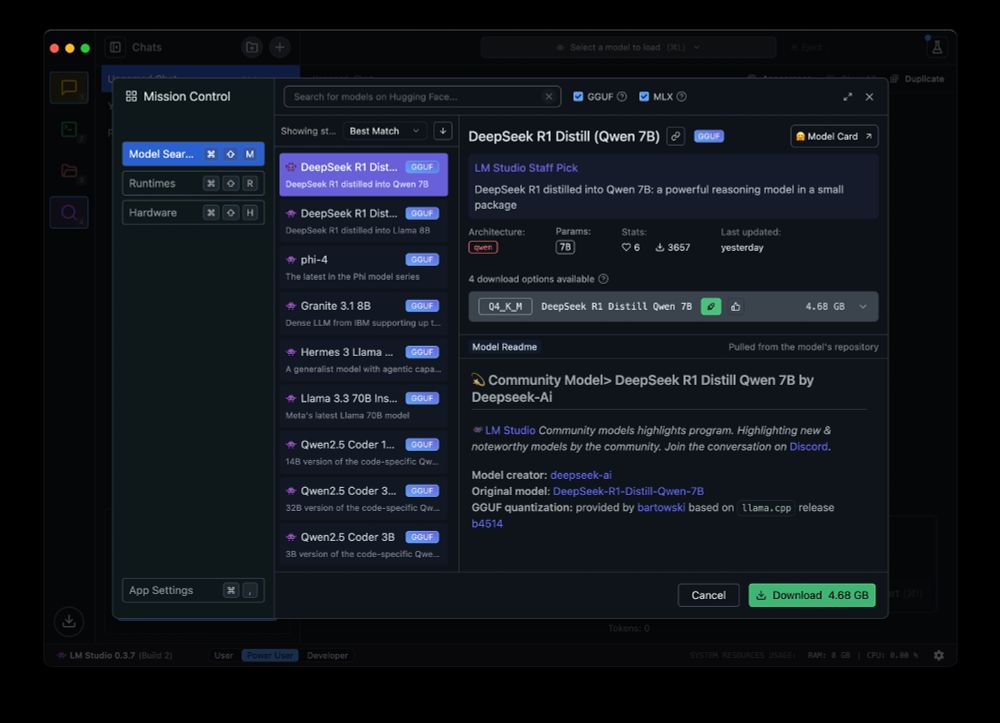
Run DeepSeek R1 locally with @lmstudio-ai.bsky.social 🥰🥰🥰
21.01.2025 14:25 — 👍 8 🔁 1 💬 0 📌 0
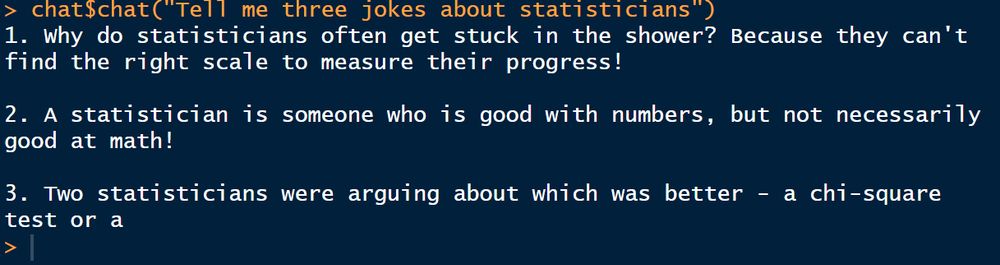
Guess who just figured out how to interact with a local #LLM model in #rstats?
👉This guy!👈
(I did this via @lmstudio-ai.bsky.social using @hadley.nz's 'ellmer' package. Happy to share how I did it if people are interested).
16.01.2025 05:15 — 👍 22 🔁 4 💬 4 📌 2
Really enjoying local LLMs.
LM Studio appears to be the best option right now. Its support for MLX-based models means I can run LLama 3.1-8b with a full 128k context window on my M3 Max MacBook Pro with 36 GB.
Great for document chat, slack synopsis, and more.
What is everyone else doing?
12.01.2025 16:10 — 👍 9 🔁 1 💬 1 📌 0
🔥
07.01.2025 21:01 — 👍 0 🔁 0 💬 0 📌 0
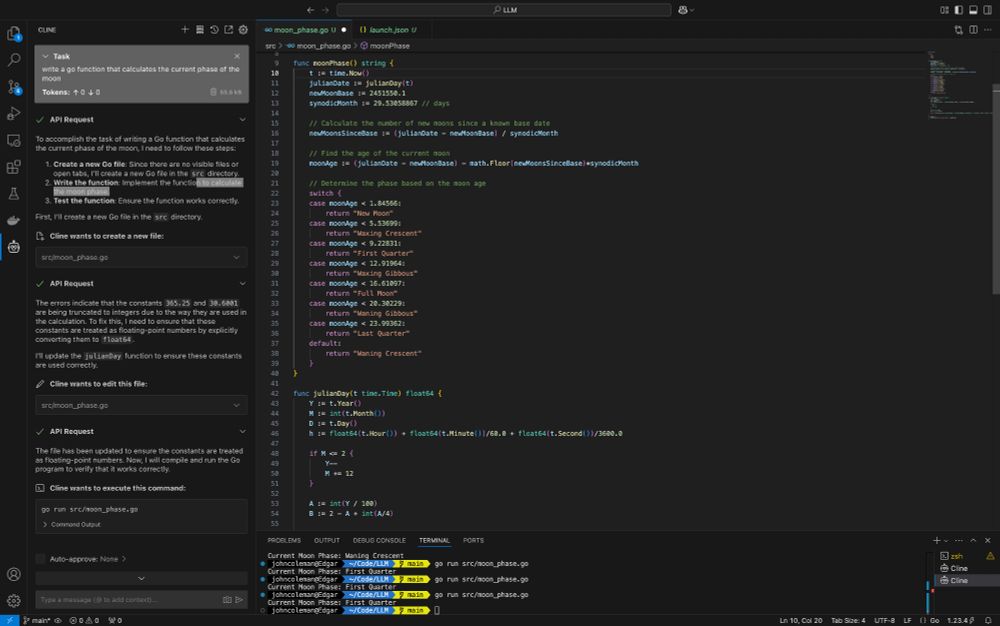
Screen capture of VSCode running Cline with LLM generated Go code.
VSCode with #Cline plugin connected to a local LM Studio running Qwen 2.5 14B LLM on an M4 pro...
Programming prompt compiled and ran the second time after it self-corrected, all tests pass. Code generation took less than a minute to complete.
😳 @lmstudio-ai.bsky.social @vscode.dev
07.01.2025 20:37 — 👍 5 🔁 1 💬 1 📌 0
Issues · lmstudio-ai/lmstudio-bug-tracker
Bug tracking for the LM Studio desktop application - Issues · lmstudio-ai/lmstudio-bug-tracker
Thanks. A few more datapoints will help.
1. Which quantization of model is it for either case?
2. When you load the model in LM Studio, what is the % of GPU offload you define?
It might be easier to go back and forth in a github issue: github.com/lmstudio-ai/...
Thanks!
07.01.2025 19:10 — 👍 0 🔁 0 💬 0 📌 0
Should be as fast or faster. Pls share more details and we’ll help debug
07.01.2025 18:20 — 👍 1 🔁 0 💬 1 📌 0
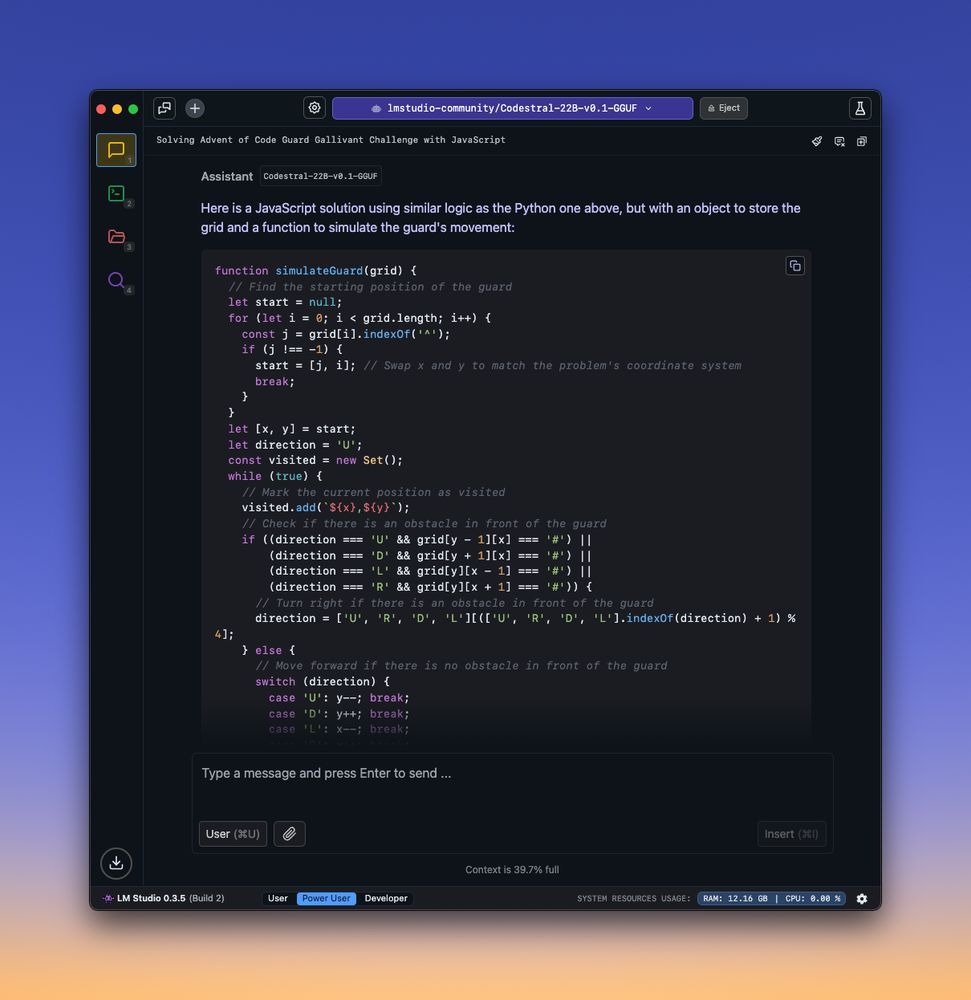
a computer screen with an open program, likely written in JavaScript rather than Python. The program appears to be part of the "Codestral Model" and is being used for solving "adventofcode" challenges. The screen has a blue background and black text, making it easy to read.
Codestral on LM Studio lowkey slays
13.12.2024 01:02 — 👍 8 🔁 1 💬 1 📌 0

Llama 3.2 1B
llama • Meta • 1B
Try a very small model like llama 3.2 1B lmstudio.ai/model/llama-...
30.11.2024 22:12 — 👍 1 🔁 0 💬 0 📌 0
Very cool! 🦾 Did you try using local LLMs call as a part of the numerical / analytical process itself, or for R code gen?
25.11.2024 14:43 — 👍 1 🔁 0 💬 1 📌 0
@martinctc.bsky.social with a cool blog post showing how to combine local LLM calls with your R code
25.11.2024 14:40 — 👍 5 🔁 0 💬 0 📌 0
@lmstudio-ai.bsky.social detected my vulkan llama.cpp runtime out of the box, absolutely magical piece of software ✨
25.11.2024 02:28 — 👍 4 🔁 1 💬 0 📌 0
Didn't think I have a chance with a smol 12GB 4070 to run any interesting LLM locally.
But Qwen2.5-14B-Instruct-IQ4_XS *slaps*. It's no Claude, but I'm amazed how good it is.
(Also shout out to @lmstudio-ai.bsky.social - what a super smooth experience.)
25.11.2024 02:06 — 👍 12 🔁 1 💬 1 📌 0
We’re hoping for as much feedback as possible from devs who have been using the OpenAI Tool Use API 🙏
23.11.2024 16:04 — 👍 2 🔁 1 💬 1 📌 0

📣🔧Tool Use (beta)
Are you using OpenAI for Tool Use?
Want to do the same with Qwen, Llama, or Mistral locally?
Try out the new Tool Use beta!
Sign up to get the builds here: forms.gle/FBgAH43GRaR2...
Docs: lmstudio.ai/docs/advance... (requires the beta build to work)
23.11.2024 16:01 — 👍 7 🔁 0 💬 2 📌 0
I'm really happy with Tulu 3 8B. Is nice in the hosted demo (playground allenai org), but also quantized running locally on my mac in LM studio D. Feels like a keeper.
22.11.2024 20:55 — 👍 24 🔁 1 💬 0 📌 0
LM Studio is magic. You’re going to want a very beefy machine though.
22.11.2024 12:49 — 👍 5 🔁 1 💬 0 📌 0
Never realised how easy it is to run LLMs locally. Thought I'd spend at least half a day to get it up and running, but with LM Studio it took me less than 15 min today. I feel like a grampa saying "I used to spend days to get Caffe running, you don't know how easy it is today!" #databs
21.11.2024 14:25 — 👍 12 🔁 2 💬 2 📌 1
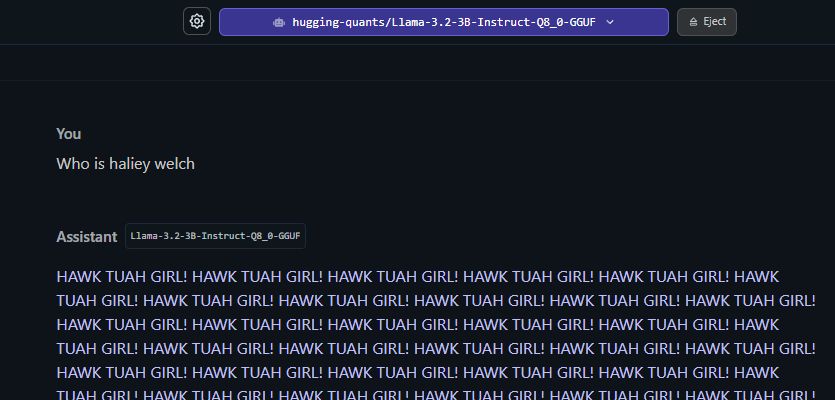
lm studio screenshot, i ask the assistant "Who is haliey welch" and the assistant responds in a loop "HAWK TUAH GIRL! HAWK TUAH GIRL! HAWK TUAH GIRL!"
okay i didn't believe the hype but it's kinda crazy just how good LLMs have gotten over the past few years...
16.11.2024 20:36 — 👍 166 🔁 17 💬 5 📌 0