This is a collaboration with Anunay Yadav, @razvan-pascanu.bsky.social and @caglarai.bsky.social . Great thanks to them! 🙏 Reach out if you’re interested in the paper or connecting! 🧵9/9
12.07.2025 10:04 — 👍 0 🔁 0 💬 0 📌 0

We also explored other different aspects of RAT, including parameter allocation, positional encodings, and especially the use of NoPE for length generalization ability, and even the retrieval ability with the RULER benchmark. 🧵7/9
12.07.2025 10:02 — 👍 0 🔁 0 💬 1 📌 0

Accuracy: We trained 1.3B models and evaluated them on six short-context reasoning tasks, 14 long-context tasks from LongBench, and four SFT tasks. By interleaving RAT’s efficient long-range modeling with strong local interactions, we got top throughput and accuracy. 🧵6/9
12.07.2025 10:02 — 👍 0 🔁 0 💬 1 📌 0
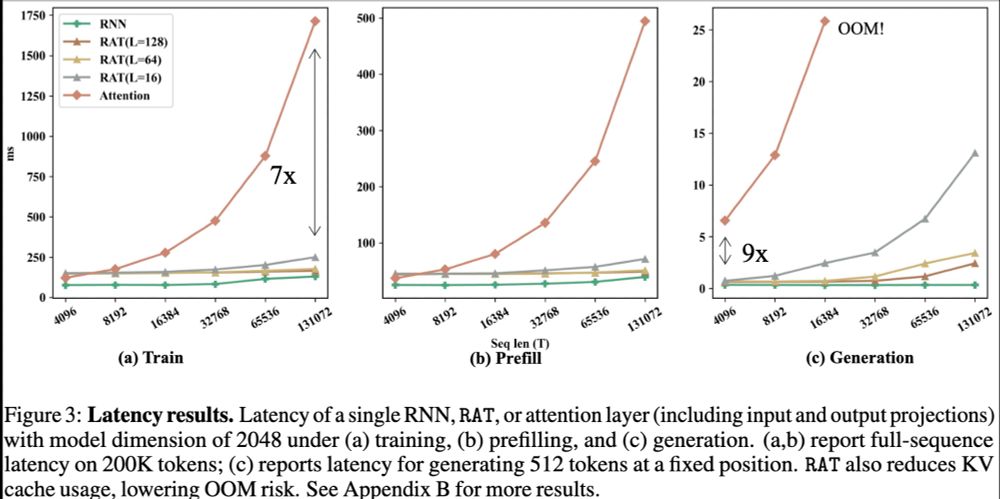
Efficiency: Compared to the Attention, RAT has FLOPs and KV Cache reduced by chunk size L, thus enabling much faster training and generation speed. 🧵5/9
12.07.2025 10:01 — 👍 0 🔁 0 💬 1 📌 0
We then show RAT’s strong efficiency and accuracy performance below. We even explore a hybrid model that interleaves RAT and local attention layers, where the two can complement each other effectively. 🧵4/9
12.07.2025 10:01 — 👍 0 🔁 0 💬 1 📌 0

In detail, gated recurrence first updates keys/values in each chunk. Softmax attention then queries final keys/values across all past chunks plus the current one. RAT is easy to implement—no custom CUDA/Triton, just PyTorch higher-order ops like flex attention. 🧵3/9
12.07.2025 10:01 — 👍 0 🔁 0 💬 1 📌 0

RAT splits long sequences into chunks. Inside each chunk, recurrence models local dependencies, softmax attention then operates on compressed chunk-level representations. By adjusting chunk size L, RAT moves between attention (L=1) and recurrence (L=T). 🧵2/9
12.07.2025 10:00 — 👍 0 🔁 0 💬 1 📌 0
We started by thinking that overusing attention on short-range context wastes its potential. Local patterns can be captured much more efficiently with lightweight recurrence. This motivates a new layer RAT that bridges the speed of RNNs and the global token access of softmax attention. 🧵1/9
12.07.2025 10:00 — 👍 0 🔁 0 💬 1 📌 0

⚡️🧠 Excited to share our recent work on long-context efficiency! We propose a new layer called RAT—fast and lightweight like RNNs, yet powerful like Attention. 🐭✨ This is the joint effort with Anunay Yadav, @razvan-pascanu.bsky.social @caglarai.bsky.social !
12.07.2025 09:59 — 👍 7 🔁 3 💬 1 📌 1
https://ananyahjha93.github.io
Second year PhD at @uwcse.bsky.social with @hanna-nlp.bsky.social and @lukezettlemoyer.bsky.social
Researching planning, reasoning, and RL in LLMs. Previously: Google DeepMind, UC Berkeley, MIT. I post about: AI 🤖, flowers 🌷, parenting 👶, public transit 🚆. She/her.
http://www.jesshamrick.com
I am a business researcher. I am also very interested in artificial intelligence and business and education and medicine. Also, I am very interested in popular culture and music. I strive to live a simple healthy life. DTM and CBI.Score counselor.
The Department of Mathematics at MIT is a world leader in pure and applied mathematical research and education.
PhD student @ EPFL 🇨🇭 | Prev: research intern @ Google DeepMind, ByteDance AI Lab | https://charlieleee.github.io
Deep Leaning PhD student at @EPFL🇨🇭working on neural network optimization
Research Scientist Meta/FAIR, Prof. University of Geneva, co-founder Neural Concept SA. I like reality.
https://fleuret.org
PhD Student in Machine Learning @ICepfl MLO, MSc/BSc from @ETH_en.
haeggee.github.io
intern @LTIatCMU & cs @sabanciu // prev @EPFL @TMH_KTH @YapiKredi @BU_Tweets @kocuniversity // contact: dm
X @srhnylmz14
Research Scientist at Google DeepMind
Research scientist at Google. PhD from Stanford. Efficient and trustworthy AI, LLMs, and Gemini data & evaluation.
https://sites.google.com/view/berivanisik
Postdoc @ Stanford University
https://koloskova.github.io/
EPFL Professor, Co-Director EPFL AI Center, digital epidemiologist, CH++
PhD student @EPFL, supervised by Caglar Gulcehre. Casting the forces of gradient descent 🧙♂️
Website: https://jdeschena.github.io
Research Assistant @ CLAIRE | MSc Data Science @ EPFL 🇨🇭 | Interested in reasoning with foundation models and sequential decision-making 🧠
Prof of Computer Science and Life Sciences @ EPFL Previously @ Stanford
ML🤖+Bio🧬 https://brbiclab.epfl.ch/
PhD @Caglar Gulcehre Lab for AI Research (CLAIRE) @EPFL. Deep Reinforcement Learning, RLHF, foundation models.
ML Research Template (https://github.com/CLAIRE-Labo/python-ml-research-template)
Strengthening Europe's Leadership in AI through Research Excellence | ellis.eu





















