This is a step toward scalable, robust LLM evaluation — free from stale benchmarks, incomplete evaluation measures, and human bottlenecks.
Paper: aair-lab.github.io/Publications...
Catch us at poster session 4 on Friday April 25th at #ICLR (poster 318).
(3/3)
22.04.2025 12:17 — 👍 0 🔁 0 💬 0 📌 0
Results show that truth-maintenance performance predicts performance in formal language tasks such as reasoning. Testing of both LLMs and LRMs reveals that SOTA models still struggle maintaining truth and are inaccurate semantic equivalence verifiers.
(2/3)
22.04.2025 12:16 — 👍 0 🔁 0 💬 1 📌 0
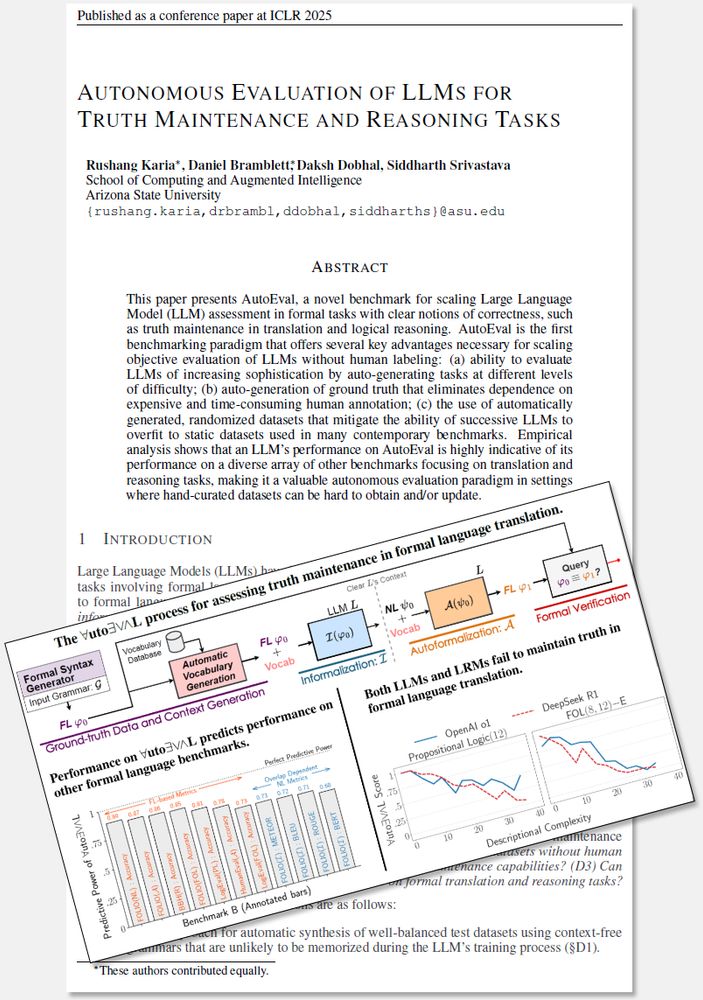
Can we automatically evaluate the semantic accuracy of LLM translations without human annotation?
Our #ICLR ’25 work introduces a novel approach for assessment of truth maintenance in formal language translation.
Joint w/ Rushang Karia, Daksh Dobhal, @sidsrivast.bsky.social.
(1/3)
22.04.2025 12:16 — 👍 0 🔁 0 💬 1 📌 1
We are looking to broaden the scope to encode more diverse user preferences and constraints for more real-world problems.
Paper: aair-lab.github.io/Publications...
Catch us at the poster session on Wednesday evening (poster 6505)!
10.12.2024 23:38 — 👍 2 🔁 0 💬 0 📌 0
Our theoretical analysis indicates that the resulting problems are solvable within a finite number of evaluations, leading to an algorithm for finding optimal user-aligned policy. Theoretically, its probabilistically complete; empirically, it converges faster and more reliably than previous methods.
10.12.2024 23:37 — 👍 2 🔁 0 💬 1 📌 0

Can we align an AI system with users’ expectations when it has limited, noisy information about the real world?
Our #NeurIPS ’24 work allows users fuse high-level objectives with preferences and constraints based on the agent’s current belief about its environment.
Joint w/ @sidsrivast.bsky.social
10.12.2024 23:37 — 👍 4 🔁 0 💬 1 📌 1


