You’ll hear from real users, see a live walkthrough, and get a chance to ask questions.
If you’re focused on simplifying data delivery, reducing overhead, or making data work for both humans and AI, join us.
👇
10.04.2025 17:25 — 👍 0 🔁 0 💬 1 📌 0
Join us to see:
💡 How autonomous data products actually work
🕹️ What makes them self-orchestrating and self-governing
📉 How enterprise teams are already simplifying delivery, cutting cost, and scaling safely
🤖 What this means for agents, analytics, and beyond
10.04.2025 17:25 — 👍 0 🔁 0 💬 1 📌 0
On April 22, Nextdata founder and CEO, @zhamak.bsky.social, will unveil Nextdata OS, the first operating platform for autonomous data products.
This isn’t another tool. It’s a new operating model for delivering trusted data.
10.04.2025 17:24 — 👍 0 🔁 0 💬 1 📌 0
What if your #dataproducts could manage themselves? 🤔
No more patching pipelines. No more governance after the fact. No constant replatforming just to stay afloat.
We’re launching something built for that future.
🧵👇
10.04.2025 17:22 — 👍 0 🔁 0 💬 1 📌 0
[WEBINAR]: MeshRAG: Scalable Data Management for GenAI
Learn how to ensure the safety, quality and governance of data for your GenAI RAG applications with Nextdata's Jörg Schad!
Need more #MeshRAG? Join us on Jan 16th at 8:30 AM PT for "MeshRAG: Scalable Data Management for GenAI," a 1-hr webinar hosted by @nextdata.bsky.social very own Jörg Schad!
🎟️Get your tickets here: bit.ly/4h0OCyI
02.01.2025 20:06 — 👍 1 🔁 0 💬 0 📌 0

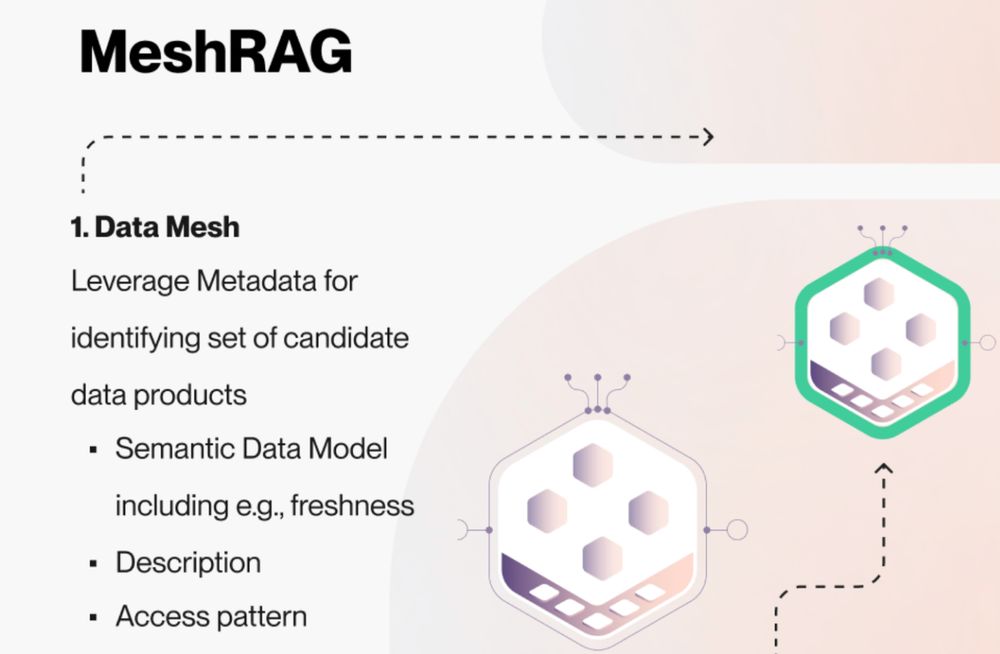
Introducing MeshRAG - unified data management for big data and GenAI
Data Mesh implementation simplifies the RAG use case.
Enterprises need solutions that bridge the gap between new #GenAI use cases and traditional ML, ensuring robust, compliant, and scalable AI deployments.
Check out our blog on scaling RAG pipelines with MeshRAG here: bit.ly/4h0OP4Y
02.01.2025 20:05 — 👍 1 🔁 0 💬 1 📌 0
⏱️ Latency & Data Freshness
Real-time apps like recommender systems need fresh data for relevant suggestions. In enterprises, syncing embeddings is tough—delays mean outdated recommendations, hurting user experience & trust in the system.
02.01.2025 20:02 — 👍 0 🔁 0 💬 1 📌 0
📈 Scalability & Performance
Managing vast #data & real-time use cases means efficiently updating millions of #embeddings for accurate recommendations. Without robust data management, pipelines bottleneck—leading to slow performance & frustrated users.
02.01.2025 20:02 — 👍 1 🔁 0 💬 1 📌 0
Maintaining low latency and high responsiveness is crucial for stakeholders on data science and ML teams.
When implementing a RAG app, platform teams must consider the following:
02.01.2025 20:02 — 👍 0 🔁 0 💬 1 📌 0
🚀Scaling RAG Applications for High Performance in Enterprises🚀
As enterprises grow, so do their data sources and user bases. Scaling #RAG pipelines to handle petabytes of data across multiple entities is not easy.
🧵👇below:
02.01.2025 20:01 — 👍 2 🔁 1 💬 1 📌 0
(5/6) What’s Ahead for 2025?
Trends to watch and how simplifying data infrastructure can unlock new opportunities for teams🌟
30.12.2024 17:18 — 👍 1 🔁 0 💬 1 📌 0
(4/6) Budget Pressures & DIY Platforms
Economic shifts drove DIY platforms—but at what cost?
We explore the pitfalls & how companies are re-prioritizing investments💡
30.12.2024 17:18 — 👍 0 🔁 0 💬 1 📌 0
(3/6) Modern Data Stack Realities
The modular promise vs. fragmented reality.
⏳ How can the "hourglass model" restore balance and efficiency in 2025?
30.12.2024 17:18 — 👍 0 🔁 0 💬 1 📌 0
2/6) Generative AI’s Impact
Why did GenAI surge in 2024?
🔹 Challenges in data platforms
🔹 The need for scalable AI workflows
What’s next to fully realize its potential? 🤔
30.12.2024 17:16 — 👍 0 🔁 0 💬 1 📌 0
(1/6) 🚀 Reflecting on 2024 in Data Management
Join Zhamak Dehghani, founder/CEO of @nextdata.bsky.social, as we explore 2024’s key data moments and trends shaping 2025.
From #generativeAI to shifts in tech stacks, here’s what we learned this year 🧵👇
30.12.2024 17:16 — 👍 5 🔁 0 💬 1 📌 0

Introducing Mesh RAG - unified data management for big data and GenAI
Scaling RAG applications in large enterprises requires more than just the right tech stack—it demands strategic data management, robust infrastructure, and seamless collaboration across teams.
Learn more about it here: bit.ly/3BZapb8
27.12.2024 21:38 — 👍 1 🔁 0 💬 0 📌 0
🔒 Governance & Compliance
Handling sensitive data (ex. PII) requires strict governance. In the example of a streaming service, ensuring all user data used in RAG pipelines complies with regulations adds another layer of complexity. Any misstep can lead to legal issues and a loss of trust.
27.12.2024 21:36 — 👍 1 🔁 0 💬 1 📌 0
📊 Inconsistent Data Quality:
The output of a model is only as good as the data it consumes. This has been the case in traditional ML & still holds true for LLMs. If data is duplicated across multiple domains with inconsistencies between them, the LLMs output can be skewed, reducing their efficacy.
27.12.2024 21:35 — 👍 0 🔁 0 💬 1 📌 0
⚙️ Complex Infrastructure: Enterprises often juggle legacy systems alongside a modern data stack. Imagine integrating old on-prem databases with Snowflake for your RAG pipeline. It’s already difficult when scope is limited and becomes a nightmare to scale.
27.12.2024 21:34 — 👍 0 🔁 0 💬 1 📌 0
🔍 Data Silos & Fragmentation: Enterprise data teams often face scattered data across domains like marketing, customer experience, & product, each using different formats. This fragmentation complicates creating unified embeddings, leading to inconsistent and unreliable outputs.
27.12.2024 21:31 — 👍 0 🔁 0 💬 1 📌 0
This leaves enterprises with complex data stacks and multiple pipelines in a bind when attempting to deploy it in a single domain, let alone scale it across an organization. Many popular approaches to RAG neglect the following for enterprise use cases:
27.12.2024 21:28 — 👍 0 🔁 0 💬 1 📌 0
Why Is Building RAG Applications Challenging at Enterprise Scale? 🧵👇
Everyone knows RAG applications are the easiest way to train LLMs with custom data, but most examples only showcase a single pipeline approach.
27.12.2024 21:28 — 👍 3 🔁 0 💬 1 📌 0



