
Creative Preference Optimization
Novel preference optimization method and a multi-task creativity dataset promoting LLM output creativity
🙏 Huge thanks to my collaborators Antonio Laverghetta, Simone Luchini, Reet Patel, @abosselut.bsky.social Lonneke van der Plas and @roger-beaty.bsky.social
for making this possible! We also publicly release the code, models, and data!
www.mete.is/creative-pre...
22.09.2025 13:43 — 👍 1 🔁 0 💬 0 📌 0

📊 Results
We fine-tuned small LLMs like Llama-3.1-8B-Instruct on MuCE using CrPO and achieved significant improvements on LLM output creativity across all dimensions while maintaining high output quality
CrPO models beat SFT, vanilla DPO, and large models such as GPT-4o 🔥
22.09.2025 13:43 — 👍 1 🔁 0 💬 1 📌 0
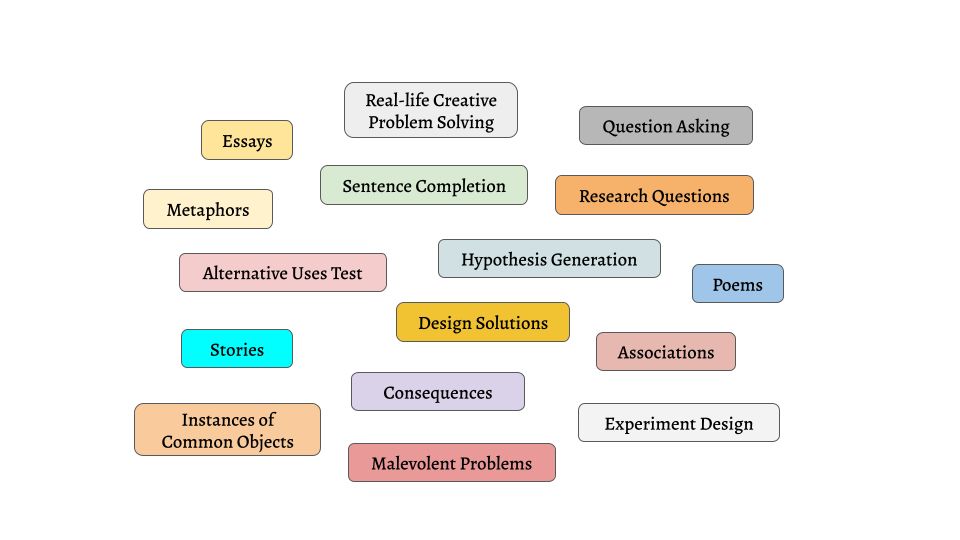
📃Multi-task Creativity Evaluation (MuCE)
To apply CrPO, we also collect a large-scale preference dataset consisting of more than 200K human responses and ratings for more than 30 creativity assessments, and use a subset of it to train and evaluate our models.
22.09.2025 13:43 — 👍 1 🔁 0 💬 1 📌 0

🧠 How do we compute creativity scores?
Instead of treating creativity as a single concept, we break it down into its major dimensions and employ metrics for each that provide measurable signals aligning with key cognitive theories and enable practical optimization within LLMs.
22.09.2025 13:43 — 👍 1 🔁 0 💬 1 📌 0

🔧 How does it work?
CrPO = Direct Preference Optimization (DPO) × a weighted mix of creativity scores (novelty, surprise, diversity, quality).
This modular objective enables us to optimize LLMs for different dimensions of creativity tailored to a given domain.
22.09.2025 13:43 — 👍 1 🔁 0 💬 1 📌 0

💡Can we optimize LLMs to be more creative?
Introducing Creative Preference Optimization (CrPO) and MuCE (Multi-task Creativity Evaluation Dataset).
Result: More novel, diverse, surprising text—without losing quality!
📝 Appearing at #EMNLP2025
22.09.2025 13:43 — 👍 6 🔁 4 💬 1 📌 0
I am attending @naaclmeeting.bsky.social this week to present our paper. Come check out our poster at 14:00, Apr 30 in Hall 3 . @defnecirci.bsky.social and Hale Sirin will also be there to answer your questions!
30.04.2025 00:34 — 👍 3 🔁 2 💬 0 📌 0
Lots of great news out of the EPFL NLP lab these last few weeks. We'll be at @iclr-conf.bsky.social and @naaclmeeting.bsky.social in April / May to present some of our work in training dynamics, model representations, reasoning, and AI democratization. Come chat with us during the conference!
25.02.2025 09:18 — 👍 25 🔁 12 💬 1 📌 0
Check out our paper [https://arxiv.org/abs/2410.12656] for more details. Huge shoutouts to my amazing collaborators
@defnecirci.bsky.social, @jonnesaleva.bsky.social, Hale Sirin, Abdullatif Koksal, Bhuwan Dhingra, @abosselut.bsky.social, Duygu Ataman, Lonneke van der Plas.
20.02.2025 17:28 — 👍 2 🔁 1 💬 0 📌 1
Our further analysis shows that tokenization is not likely to be the issue, adding context does not help, models are sensitive to the order of morphemes in the prompt and removing language-specific shortcuts from data lowers their performance even further.
20.02.2025 17:28 — 👍 1 🔁 0 💬 1 📌 0

Our analysis shows that model performance is negatively correlated with the morphological complexity of the words (i.e. number of morphemes) while human performance is not systematically affected (results shown for GPT-4 below)
20.02.2025 17:28 — 👍 0 🔁 0 💬 1 📌 0


We find that all models struggle to compose new words and fail to consistently recognize the validity of all compositions, especially when applied to novel (i.e. out-of-distribution) word roots. Humans on the other hand ace both tasks and easily generalize to novel words.
20.02.2025 17:28 — 👍 0 🔁 0 💬 1 📌 0
...and evaluate several multilingual LLMs (GPT-4, Gemini-1.5, Aya-23, Qwen2.5) on these tasks in two typologically-related (i.e. agglutination), but unrelated languages: Turkish and Finnish. We also evaluate native human speakers of these languages.
20.02.2025 17:28 — 👍 0 🔁 0 💬 1 📌 0

We design two novel compositional probing tasks to measure morphological productivity (i.e. ability to produce novel well-formed combinations of morphemes) and systematicity (i.e. ability to systematically understand novel combinations)...
20.02.2025 17:28 — 👍 0 🔁 0 💬 1 📌 0
#NLProc PhD student @EPFL
#interpretability
Astronaut, back on Earth after 3 spaceflights. For events & media, please write to info@chrishadfield.ca. Order books at http://chrishadfield.ca/books
Weeknights 11/10c on Comedy Central and Paramount+
A nonprofit organization enabling mass innovation through open source. #linux #kubernetes #riscv #hyperledger #anuket #openssf #openjs #o3de and more!
In-depth, independent reporting to better understand the world, now on Bluesky. News tips? Share them here: http://nyti.ms/2FVHq9v
Fan Account cross posting from the other place!
The Real Kyle: @kylekulinskishow.bsky.social
The Kyle Kulinski Show: https://youtube.com/seculartalk
Krystal Kyle & Friends: https://krystalkyleandfriends.substack.com
Hosted by Cenk Uygur & Ana Kasparian. Live weekdays at 6pm eastern at YouTube.com/@theyoungturks/live
Research Director, Founding Faculty, Canada CIFAR AI Chair @VectorInst.
Full Prof @UofT - Statistics and Computer Sci. (x-appt) danroy.org
I study assumption-free prediction and decision making under uncertainty, with inference emerging from optimality.
Publisher Skeptic Magazine | Host The Michael Shermer Show | Skeptic columnist: http://michaelshermer.substack.com | NEW BOOK Conspiracy: http://amzn.to/3Eza8Lf
LM/NLP/ML researcher ¯\_(ツ)_/¯
yoavartzi.com / associate professor @ Cornell CS + Cornell Tech campus @ NYC / nlp.cornell.edu / associate faculty director @ arXiv.org / researcher @ ASAPP / starting @colmweb.org / building RecNet.io
Book: https://thecon.ai
Web: https://faculty.washington.edu/ebender










![Secular Talk 🎙 [fan]](https://cdn.bsky.app/img/avatar/plain/did:plc:q62rzsxe5sd5dcgzcdq6dnqx/bafkreibxpicof57gyxl2hqdj6m3tfdnowfxc26v4jre3rwojtncd5qubpu@jpeg)






