
GitHub - aaronstevenwhite/glazing: Unified data models and interfaces for syntactic and semantic frame ontologies.
Unified data models and interfaces for syntactic and semantic frame ontologies. - aaronstevenwhite/glazing
I've found it kind of a pain to work with resources like VerbNet, FrameNet, PropBank (frame files), and WordNet using existing tools. Maybe you have too. Here's a little package that handles data management, loading, and cross-referencing via either a CLI or a python API.
27.09.2025 13:51 — 👍 27 🔁 7 💬 3 📌 1
Whoops my b, 11-12:30
25.07.2025 18:37 — 👍 1 🔁 0 💬 0 📌 0
🇦🇹I'll be at #ACL2025! Recently I've been thinking about:
✨linguistically + cognitively-motivated evals (as always!)
✨understanding multilingualism + representation learning (new!)
I'll also be presenting a poster for BehaviorBox on Wed @ Poster Session 4 (Hall 4/5, 10-11:30)!
25.07.2025 18:06 — 👍 18 🔁 4 💬 1 📌 0
I did an interview w/ Pittsburgh's NPR station to share some of my views on the topic of the McCormick/Trump AI & Energy summit at CMU tomorrow. Despite being hosted at the university, there will not be opportunities for our university experts to contribute viewpoints at the event.
14.07.2025 15:49 — 👍 16 🔁 8 💬 1 📌 1

Print screen of the first page of a paper pre-print titled "Rigor in AI: Doing Rigorous AI Work Requires a Broader, Responsible AI-Informed Conception of Rigor" by Olteanu et al. Paper abstract: "In AI research and practice, rigor remains largely understood in terms of methodological rigor -- such as whether mathematical, statistical, or computational methods are correctly applied. We argue that this narrow conception of rigor has contributed to the concerns raised by the responsible AI community, including overblown claims about AI capabilities. Our position is that a broader conception of what rigorous AI research and practice should entail is needed. We believe such a conception -- in addition to a more expansive understanding of (1) methodological rigor -- should include aspects related to (2) what background knowledge informs what to work on (epistemic rigor); (3) how disciplinary, community, or personal norms, standards, or beliefs influence the work (normative rigor); (4) how clearly articulated the theoretical constructs under use are (conceptual rigor); (5) what is reported and how (reporting rigor); and (6) how well-supported the inferences from existing evidence are (interpretative rigor). In doing so, we also aim to provide useful language and a framework for much-needed dialogue about the AI community's work by researchers, policymakers, journalists, and other stakeholders."
We have to talk about rigor in AI work and what it should entail. The reality is that impoverished notions of rigor do not only lead to some one-off undesirable outcomes but can have a deeply formative impact on the scientific integrity and quality of both AI research and practice 1/
18.06.2025 11:48 — 👍 60 🔁 18 💬 2 📌 3
Where does one language model outperform the other?
We examine this from first principles, performing unsupervised discovery of "abilities" that one model has and the other does not.
Results show interesting differences between model classes, sizes and pre-/post-training.
09.06.2025 18:33 — 👍 5 🔁 2 💬 0 📌 0

9/9 Finally, we found that we can use the discovered features to distinguish actual *generations* from these models, showing the connection between features from a predetermined corpus and the actual output behavior of the model!
09.06.2025 13:47 — 👍 1 🔁 0 💬 1 📌 0
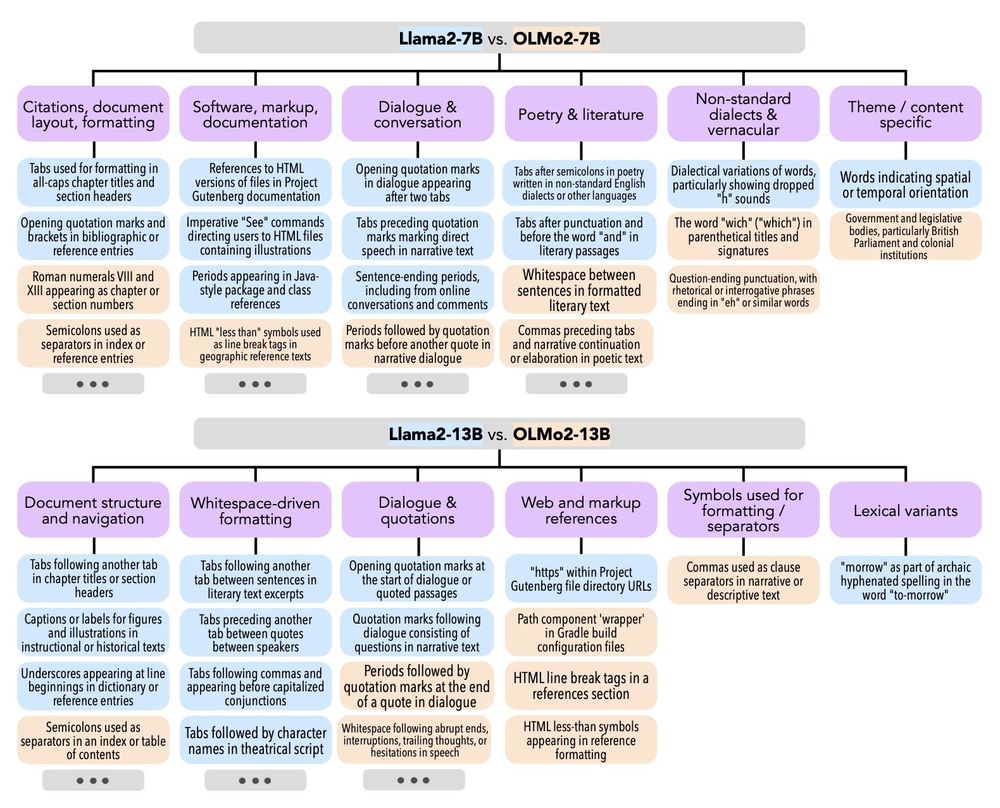
8/9 Furthermore, models that show a small diff in perplexity can have a large number of features where they differ!
Comparisons between Llama2 and OLMo2 models of the same size (which barely show a diff in perplexity) had the greatest number of discovered features.
09.06.2025 13:47 — 👍 3 🔁 0 💬 1 📌 0

7/9 We apply BehaviorBox to models that differ in size, model-family, and post-training. We can find features showing that larger models are better at handling long-tail stylistic features (e.g. archaic spelling) and that RLHF-ed models are better at conversational expressions:
09.06.2025 13:47 — 👍 1 🔁 0 💬 1 📌 0

6/9 We filter for features that show a median diff in probability between the two LMs > a cutoff value, then automatically label these features with a strong LLM by providing the representative examples.
09.06.2025 13:47 — 👍 0 🔁 0 💬 1 📌 0
5/9 We then use the SAE to learn a higher-dim representation of these embeddings. Like previous work, we treat each learned dim as a feature, with the group of words leading to the highest activation of the feature as representative examples.
09.06.2025 13:47 — 👍 1 🔁 0 💬 1 📌 0

4/9 To find features that describe a performance difference between two LMs, we train a SAE on *performance-aware embeddings*: contextual word embeddings from a separate pre-trained LM, concatenated with probabilities of these words under the LMs being evaluated.
09.06.2025 13:47 — 👍 1 🔁 0 💬 1 📌 0
3/9 Our method BehaviorBox both 🔍finds and ✍️describes these fine-grained features at the word level. We use (*gasp*) SAEs as our method to find said features.
What makes our method distinct is the data we use as input to the SAE, which allows us to find *comparative features*.
09.06.2025 13:47 — 👍 2 🔁 0 💬 1 📌 0
2/9 While corpus-level perplexity is a standard metric, it often hides fine-grained differences. Given a particular corpus, how can we find features of text that describe where model A > model B, and vice versa?
09.06.2025 13:47 — 👍 0 🔁 0 💬 1 📌 0
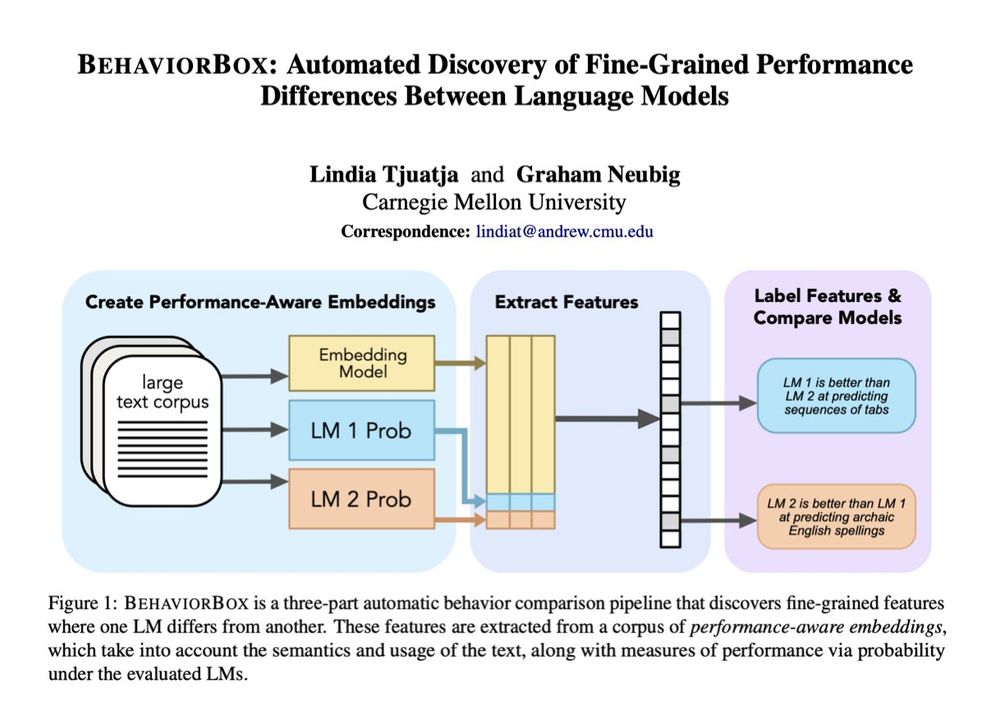
When it comes to text prediction, where does one LM outperform another? If you've ever worked on LM evals, you know this question is a lot more complex than it seems. In our new #acl2025 paper, we developed a method to find fine-grained differences between LMs:
🧵1/9
09.06.2025 13:47 — 👍 71 🔁 21 💬 2 📌 2
Hanging around NAACL and presenting this Thurs, 4:15 @ ling theories oral session (ballroom 🅱️). Come say hi, will also be eating many a sopapilla
30.04.2025 14:18 — 👍 4 🔁 1 💬 0 📌 0
wow that sounds and looks delicious
25.01.2025 20:21 — 👍 2 🔁 0 💬 1 📌 0
I wasn’t super excited by o1, but as reasoning models go open-weights I’m starting to see how they make this interesting again. The 2022-24 “just scale up” period was both very effective and very boring.
23.01.2025 15:03 — 👍 15 🔁 2 💬 2 📌 0
Accept to NAACL main! See yall in NM ☀️
22.01.2025 23:26 — 👍 16 🔁 1 💬 0 📌 0

sleeping orange cat

orange cat getting pets

alert orange cat
cat
31.12.2024 00:49 — 👍 6 🔁 0 💬 0 📌 0
I am once again asking for {cafe, food, work spots, things to see and do} for a place I will be visiting: the baaaay 🌁
(My first time visiting NorCal *ever* so the regular tourist spots are welcome!)
29.12.2024 17:36 — 👍 1 🔁 0 💬 0 📌 0
Paperlike! I’ve been using mine for years and I like it
24.12.2024 14:35 — 👍 4 🔁 0 💬 1 📌 0

The movie poster for "Love Actually" but changed to "Labov Actually" with his face pasted over everyone else's and fun changes throughout like "very romantic, very comedy" changed to "very rhotic, very stratified."
I don't remember who created this, where I got it from, or how long I've had it, but I have it on my slides as students walk in the first time we talk about Labov's NYC study. And it makes me chuckle every time I see it for some reason.
"Very rhotic. Very stratified." 😆
18.12.2024 22:16 — 👍 132 🔁 28 💬 3 📌 2

The abstract of a paper titled "Basic Research, Lethal Effects: Military AI Research Funding as Enlistment".
In the context of unprecedented U.S. Department of Defense (DoD) budgets, this paper examines the recent history of DoD funding for academic research in algorithmically based warfighting. We draw from a corpus of DoD grant solicitations from 2007 to 2023, focusing on those addressed to researchers in the field of artificial intelligence (AI). Considering the implications of DoD funding for academic research, the paper proceeds through three analytic sections. In the first, we offer a critical examination of the distinction between basic and applied research, showing how funding calls framed as basic research nonetheless enlist researchers in a war fighting agenda. In the second, we offer a diachronic analysis of the corpus, showing how a 'one small problem' caveat, in which affirmation of progress in military technologies is qualified by acknowledgement of outstanding problems, becomes justification for additional investments in research. We close with an analysis of DoD aspirations based on a subset of Defense Advanced Research Projects Agency (DARPA) grant solicitations for the use of AI in battlefield applications. Taken together, we argue that grant solicitations work as a vehicle for the mutual enlistment of DoD funding agencies and the academic AI research community in setting research agendas. The trope of basic research in this context offers shelter from significant moral questions that military applications of one's research would raise, by obscuring the connections that implicate researchers in U.S. militarism.
When I started on ARL project that funds my PhD, the thing we were supposed to build was a "MaterialsGPT".
What is a MaterialsGPT? Where does that idea come from? I got to spend a lot of time thinking about that second question with @davidthewid.bsky.social and Lucy Suchman (!) working on this:
17.12.2024 14:33 — 👍 19 🔁 7 💬 1 📌 0

My orange cat checking out a large cardboard box

My orange cat looking back at me from within a large cardboard box

My orange cat appreciating the height of a large cardboard box she is in
got a new suitcase but the main beneficiary of this purchase was my cat
17.12.2024 02:45 — 👍 7 🔁 0 💬 0 📌 0
Philip glass dootdootdootdootdoot
04.12.2024 21:12 — 👍 1 🔁 0 💬 1 📌 0
once i thought i could work to Mahler…..delusional
04.12.2024 20:58 — 👍 2 🔁 0 💬 2 📌 0
Tejano doing cognitive neuro(linguistics|science) at the University of Maryland
PhD student in computational linguistics & NLP at CIS, LMU Munich, junior member at MCML, previously at SJTU.
ercong21.github.io
PhD-ing at McGill Linguistics + Mila, working under Prof. Siva Reddy. Mostly computational linguistics, with some NLP; habitually disappointed Arsenal fan
PhD student @LTIatCMU | prev @Amazon Alexa AI, @Microsoft Research, Asia | fun 👩🏻💻 🐈 🏃🏻♀️ 🪴 🎶
Compling PhD student @UT_Linguistics | prev. CS, Math, Comp. Cognitive Sci @cornell
researching AI [evaluation, governance, accountability]
Seeking superhuman explanations.
Senior researcher at Microsoft Research, PhD from UC Berkeley, https://csinva.io/
Associate Professor and Computational Linguist @ University of Augsburg, Germany
Assistant Professor at @cs.ubc.ca and @vectorinstitute.ai working on Natural Language Processing. Book: https://lostinautomatictranslation.com/
Applied Scientist @ Amazon
(Posts are my own opinion)
#NLP #AI #ML
I am specially interested in making our NLP advances accessible to the Indigenous languages of the Americas
Research in NLP (mostly LM interpretability & explainability).
Assistant prof at UMD CS + CLIP.
Previously @ai2.bsky.social @uwnlp.bsky.social
Views my own.
sarahwie.github.io
Prof, Chair for AI & Computational Linguistics,
Head of MaiNLP lab @mainlp.bsky.social, LMU Munich
Co-director CIS @cislmu.bsky.social
Visiting Prof ITU Copenhagen @itu.dk
ELLIS Fellow @ellis.eu
Vice-President ACL
PI MCML @munichcenterml.bsky.social
language & mind-ish things (mostly fun sometimes sin), interested in what science is and does, pretend stoic but for-real epicurean (but for-real-real hedonist), we're in this together, la do la si, &c &c
tryna be drunk (comme Baudelaire)
PhD student in NLP at GMU w/ Antonios Anastasopoulos. Focus: L2 acquisition, low-resource NLP, psycholinguistics. Passionate about empowering heritage speakers. Berkeley '19
Associate Professor, Department of Psychology, Harvard University. Computation, cognition, development.
Multimodal Communication and Learning in Social Interactions (CoCoDev team). Associate Professor of Computer/Cognitive Science at Aix-Marseille University.
afourtassi.github.io
Linguist, cognitive scientist at University of Stuttgart. I study language and how we understand it one word at a time.
Computational psycholinguistics PhD student @NYU lingusitics | first gen!
PhD at EPFL 🧠💻
Ex @MetaAI, @SonyAI, @Microsoft
Egyptian 🇪🇬





























