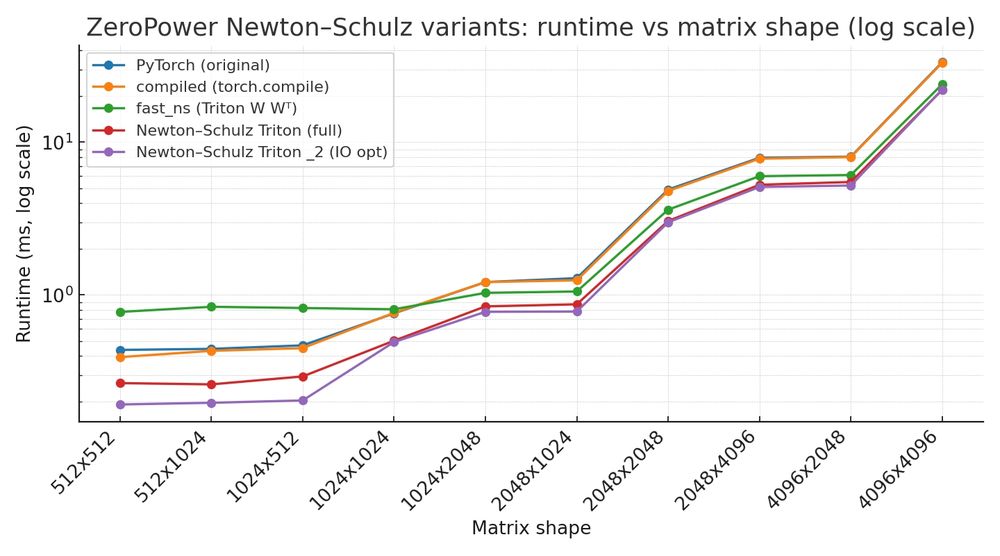
So in short:
AOL preconditioning (fused + re-tuned) -> 1 iter saved
Better convergence, singular values closer to 1
Kernel tweak removes extra memory load
This gives ~1.6x speedup, ~3x vs plain torch. 🚀
21.09.2025 20:06 — 👍 0 🔁 0 💬 0 📌 0
Bonus: I spotted redundant memory loads in the 3rd NS line.
Wrote a small kernel to optimize bandwidth ->more free speed.
21.09.2025 20:06 — 👍 0 🔁 0 💬 1 📌 0
Problem 1: AOL adds extra cost.
Fix: fuse AOL's operation with an existing NS step -> essentially free.
Problem 2: NS isn’t tuned for "almost orthogonal" inputs.
Fix: re-tune parameters with a genetic algorithm that is aware of the preconditioning.
21.09.2025 20:06 — 👍 0 🔁 0 💬 1 📌 0
The inspiration comes from
Bernd Prach's Almost Orthogonal Layer (AOL).
It gives a cheap way to make a matrix "almost orthogonal."
Not great for full orthogonalization, but much better than rescaling -> perfect as a preconditioner for NS.
21.09.2025 20:06 — 👍 0 🔁 0 💬 1 📌 0
The key idea: reduce the number of NS iterations.
How? By pre-conditioning the input matrix.
This makes the algorithm converge faster without losing precision.
21.09.2025 20:06 — 👍 0 🔁 0 💬 1 📌 0

I used a mathematical trick to pre-condition the matrix, allowing to shave one iteration of the algorithm. This is not only faster, but also unlocks better convergence, with singular values closer to 1.
21.09.2025 20:06 — 👍 0 🔁 0 💬 1 📌 0

Good news: I managed to get an extra 1.6x speedup of the Newton Schulz algorithm (which is at the core of Dion/Muon). It reaches nearly a 3x speedup over the plain torch implementation !
21.09.2025 20:06 — 👍 0 🔁 0 💬 1 📌 0
What is the S_n^++ ?
10.08.2025 10:17 — 👍 0 🔁 0 💬 1 📌 0
It's crazy to think that I spent years using bjork&Bowie algorithm with 25 iters, and within a year, we got NS alg, an optimized set of parameters to run it in 5 iter, and triton kernels.
10.08.2025 10:15 — 👍 1 🔁 0 💬 0 📌 0
Large matrices are already compute bounded so the gain is small for those, so I will work to add fp8 support (once current code is consolidated).
I'll do a PR into the Dion repo when ready !
10.08.2025 10:15 — 👍 0 🔁 0 💬 1 📌 0
Sharing my journey to learn triton: still wip but io optimization yields some decent runtime improvement (around 25% on 512x512) on Newton Schulz (as used in Dion/Muon).
10.08.2025 10:15 — 👍 2 🔁 0 💬 1 📌 0

A meme showing on the first line "how it started" with a screen capture showing a nice triton's tutorial, followed by "how it's going" with complex code about fp4 quantization for microscaling in some linear algebra algorithm.
My journey with Triton
07.08.2025 10:00 — 👍 0 🔁 0 💬 0 📌 0
Open Question: Does FP4 make fine-tuning easier or harder? On one side, fp4 weight might demand high precision gradients, on the other, it might be super compliant with QLoRA, what do you think ?
03.08.2025 11:01 — 👍 0 🔁 0 💬 0 📌 0
Robustness Check: Training in FP4 stress-tests hyperparameters and initialization quality.
If your model converges, you have robust, well-conditioned weights and gradients.
The model will likely be more resistant to input noise.
03.08.2025 11:01 — 👍 0 🔁 0 💬 1 📌 0
Not "Pure" FP4: FP4 rarely stands alone. It's usually accompanied by per-row or per-column scaling factors (FP8/FP16). Gradients are often accumulated at higher precision (FP16/FP32), making ultra-low precision practical.
03.08.2025 11:01 — 👍 0 🔁 0 💬 1 📌 0
Efficiency Boost: Halving precision (FP8 → FP4) allows doubling parameters with roughly similar FLOPs. But benefits can be even bigger because:
- Larger vector sizes enhance activations utilization.
- Lower precision floating-point math itself adds beneficial non-linearities.
03.08.2025 11:01 — 👍 0 🔁 0 💬 1 📌 0
It's likely better to have a larger model in FP4 than a smaller one in FP8 (if you can train it):
- Improved non-linearity utilization with larger feature vects
- Enhanced hardware utilization on blackwell archs.
- Stress-test your training, yields models robust to input noise
more below
03.08.2025 11:01 — 👍 0 🔁 0 💬 1 📌 0
This makes me wonder what happens in standard training: when your training loss increases, does it mean that optimization failed? Or that, thanks to weight decay, the network’s (unknown) Lipschitz constant got lower and the network is just getting more robust? 🤷
25.07.2025 19:44 — 👍 0 🔁 0 💬 1 📌 0

This has deeper implications: two networks with different initialization, batch order, or data augmentation end up learning the same function (same answers, same errors, both in train and val), even though the weights are completely different!
25.07.2025 19:44 — 👍 0 🔁 0 💬 1 📌 0

The change in the Lipschitz constant makes the network more accurate (when increased) or more robust (when decreased). Unlike traditional classification, robust classification with a Lipschitz net has a unique minimizer once the Lipschitz constant is set.
25.07.2025 19:44 — 👍 0 🔁 0 💬 1 📌 0

The Lipschitz constant of a network impacts its robustness, but what happens when you change it during training? Here, we train 16 networks with a fixed Lipschitz constant at first, then increase or decrease it by a factor of two mid-training.
25.07.2025 19:44 — 👍 0 🔁 0 💬 1 📌 0

Beyond robustness: Lipschitz networks = stability.
Different inits, different seeds, different weights—same function.
A thread 🧵
25.07.2025 19:44 — 👍 1 🔁 0 💬 1 📌 0

Some bad, but creative, training losses 👌
10.06.2025 21:55 — 👍 1 🔁 0 💬 0 📌 0
Professor of Computer Vision, @BristolUni. Senior Research Scientist @GoogleDeepMind - passionate about the temporal stream in our lives.
http://dimadamen.github.io
🎮 Indie Game Developer & 3D Artist
🔥 Developing a post-apocalyptic shooter in Unity3D
👉 Follow the progress & download the demo: torygames.itch.io
Assistant Professor at the Department of Computer Science, University of Liverpool.
https://lutzoe.github.io/
Strengthening Europe's Leadership in AI through Research Excellence | ellis.eu
Nordic AI Research, Education, and Innovation Partnership
CADIA • NORA • WASP • P1 • FCAI
http://nordicpartnership.ai
San Diego Dec 2-7, 25 and Mexico City Nov 30-Dec 5, 25. Comments to this account are not monitored. Please send feedback to townhall@neurips.cc.
Professor a NYU; Chief AI Scientist at Meta.
Researcher in AI, Machine Learning, Robotics, etc.
ACM Turing Award Laureate.
http://yann.lecun.com
Professor @ Sydney Uni
Director of Australian Centre for Robotics (ACFR) and ARIAM Hub
Interested in control, robotics, robust ML
PhD student, SSL for vision @ MetaAI & INRIA
tim.darcet.fr
Associate professor of @umdcs @umiacs @ml_umd at UMD. Researcher in #AI/#ML, AI #Alignment, #RLHF, #Trustworthy ML, #EthicalAI, AI #Democratization, AI for ALL.
Grad Student at Harvard SEAS
Interested in ML Interpretability, Computational Neuroscience, Signal Processing
ML Professor at École Polytechnique. Python open source developer. Co-creator/maintainer of POT, SKADA. https://remi.flamary.com/
PhD Student doing XAI for NLP at @ANITI_Toulouse, IRIT, and IRT Saint Exupery.
🛠️ Xplique library development team member.
Founder & CEO at RELAI (relai.ai), CS Prof at UMD, ML/AI, MIT Alum
Professor at ISTA (Institute of Science and Technology Austria), heading the Machine Learning and Computer Vision group. We work on Trustworthy ML (robustness, fairness, privacy) and transfer learning (continual, meta, lifelong). 🔗 https://cvml.ist.ac.at
Math @ AdMU • prev ML Expedock • 2x IOI & 2x ICPC World Finalist • Non-Euclidean Geom • Multimodal ML • Information Retrieval • Structured Generation
leloykun.github.io
🤗 ML at Hugging Face
🌲 Academic Staff at Stanford University (AIMI Center)
🦴 Radiology AI is my stuff
Researcher (OpenAI. Ex: DeepMind, Brain, RWTH Aachen), Gamer, Hacker, Belgian.
Anon feedback: https://admonymous.co/giffmana
📍 Zürich, Suisse 🔗 http://lucasb.eyer.be
AI for Robotics at @HuggingFace 🤗
Focusing on @LeRobotHF






















