Want to discover and visualise the differences between two different machine learning models?
We will be presenting Neehar's work on "Representational Difference Explanations" at #NeurIPS2025 in San Diego from 4:30pm to 7:30pm PT today. Poster #1115.
Full paper:
arxiv.org/abs/2505.23917
03.12.2025 16:06 —
👍 7
🔁 2
💬 0
📌 0
the way this is going the only trustworthy information will be from in-person interviews.
for annotation projects i find it much easier to trust small numbers of expert or local students annotators, compared to broad-audience online recruiting
18.11.2025 20:27 —
👍 8
🔁 1
💬 0
📌 0
ChatGPT’s signature writing style is everywhere now, and I hate it. It reminds me of when we tried mixing all the beverages at the soda fountain in middle school. We didn’t actually create the perfect drink, we just made a cloying monstrosity that lost everything good about its constituent parts.
19.11.2025 17:17 —
👍 2048
🔁 360
💬 67
📌 35
Thank you to my mentors @oisinmacaodha.bsky.social and Pietro Perona. Check out our project page! nkondapa.github.io/rdx-page/
19.11.2025 16:49 —
👍 0
🔁 0
💬 0
📌 0

To summarize our experimental results, we propose a new metric that quantifies how well a method isolates model differences. We found RDX consistently outperforms baseline approaches on this metric and several other established metrics.
19.11.2025 16:49 —
👍 1
🔁 0
💬 1
📌 0

Beyond controlled experiments, RDX uncovers previously unknown differences. For example, we found DINOv2 has extra structure for distinguishing monkey species, helping explain its improved fine-grained performance.
19.11.2025 16:49 —
👍 1
🔁 0
💬 1
📌 0

In a case study on models with small performance differences, baselines (like SAE and NMF) mostly captured shared concepts. RDX, in contrast, localized groups of images that were incorrectly clustered in the weaker model, revealing subtle but important differences.
19.11.2025 16:49 —
👍 1
🔁 0
💬 1
📌 0
To do this, we use a graph-based method to find clusters of images unique to one model. In controlled experiments, RDX reliably recovered the exact changes we introduced, while other methods identify shared structure.
19.11.2025 16:49 —
👍 1
🔁 0
💬 1
📌 0

In the game, you’ll see that prior methods often highlight the wrong parts of each model’s representations by explaining shared structure. RDX, by contrast, consistently focuses on the differences between models, making it much easier to interpret what changed during training. 🔍
19.11.2025 16:49 —
👍 1
🔁 0
💬 1
📌 0
When comparing models, we were surprised by how often existing tools fail even on simple change-detection tasks. Even small, intentional differences got washed out by shared structure. So we’ve built a little game to show these failure cases.👇
🔗https://nkondapa.github.io/rdx-page/game/
19.11.2025 16:49 —
👍 1
🔁 0
💬 1
📌 0

Excited to share our paper Representational Difference Explanations (RDX) was accepted to #NeurIPS2025! 🎉RDX is a new method for model diffing designed to isolate 🔍 representational differences. 1/7
19.11.2025 16:49 —
👍 9
🔁 4
💬 1
📌 2

Representational Difference Explanations (RDX)
Isolating and creating explanations of representational differences between two vision models.
This work was done in collaboration with @oisinmacaodha and @PietroPerona. It builds on our earlier related work RSVC (ICLR 2025). Check out our project page here nkondapa.github.io/rdx-page/ and our preprint here arxiv.org/abs/2505.23917.
08.07.2025 15:42 —
👍 0
🔁 0
💬 0
📌 0
TLDR: ٍٍRDX is a new method for isolating representational differences and leads to insights about subtle, yet, important differences between models. We test it on vision models, but the method is general and can be applied to any representational space.
08.07.2025 15:42 —
👍 0
🔁 0
💬 1
📌 0
Due to these issues we took a graph-based approach for RDX that does not use combinations of concept vectors. That means the explanation grid and the concept are equivalent -- what you see is what you get. This makes it much simpler to interpret RDX outputs.
08.07.2025 15:42 —
👍 0
🔁 0
💬 1
📌 0

Even on a simple MNIST model, it is essentially impossible to anticipate that a weighted sum over these explanations results in this normal-looking five. Linear combinations of explanation grids are tricky to understand!
08.07.2025 15:42 —
👍 0
🔁 0
💬 1
📌 0
Notably, we noticed two challenges with applying DL methods to model comparison. Explanations from DL methods are a grid of images (for vision). These grids (1) can overly simplify the underlying concept and/or (2) must be interpreted as part of a linear combination of concepts.
08.07.2025 15:42 —
👍 0
🔁 0
💬 1
📌 0

We compare RDX to several popular dictionary-learning (DL) methods (like SAEs and NMF) and find that the DL methods struggle. In the spotted wing (SW) comparison experiment, we find that NMF shows model similarities rather than differences.
08.07.2025 15:42 —
👍 0
🔁 0
💬 1
📌 0

After demonstrating that RDX works when there are known differences, we compare models with unknown differences. For example, when comparing DINO and DINOv2, we find that DINOv2 has learned a color based categorization of gibbons that is not present in DINO.
08.07.2025 15:42 —
👍 0
🔁 0
💬 1
📌 0

We apply RDX on trained models with known differences and show that it isolates the core differences. For example, we compare model representations with and w/out a “spotted wing” (SW) concept and find that RDX shows that only one model groups birds according to this feature.
08.07.2025 15:42 —
👍 0
🔁 0
💬 1
📌 0
Representational Difference Explanations (RDX)
Isolating and creating explanations of representational differences between two vision models.
Model comparison allows us to subtract away shared knowledge, revealing interesting concepts that explain model differences. Our method, RDX, isolates differences by answering the question: what does Model A consider similar that Model B does not?
nkondapa.github.io/rdx-page/
08.07.2025 15:42 —
👍 0
🔁 0
💬 1
📌 0
You’ve generated 10k concepts with your favorite XAI method -- now what? Many concepts you’ve found are fairly obvious and uninteresting. What if you could 𝑠𝑢𝑏𝑡𝑟𝑎𝑐𝑡 obvious concepts away and focus on the more complex ones? We tackle this in our latest preprint!
08.07.2025 15:42 —
👍 1
🔁 2
💬 1
📌 0
The poster will actually be presented at Saturday 10am (Singapore time). Please ignore the previous time.
24.04.2025 15:34 —
👍 0
🔁 0
💬 0
📌 0
If you’re attending ICLR, stop by our poster April 25, 3PM (Singapore time).
I’ll also be presenting a workshop poster, pushing further in this direction at the Bi-Align Workshop bialign-workshop.github.io#/ .
11.04.2025 16:11 —
👍 2
🔁 0
💬 1
📌 0

We found these unique and important concepts to be fairly complex, requiring deep analysis. We use ChatGPT-4o to analyze the concept collages and find that it gives detailed and clear explanations about the differences between models. More examples here -- nkondapa.github.io/rsvc-page/
11.04.2025 16:11 —
👍 2
🔁 0
💬 1
📌 0

We then look at “in-the-wild” models. We compare ResNets and ViTs trained on ImageNet. We measure concept importance and concept similarity. Do models learn unique and important concepts? Yes, sometimes they do!
11.04.2025 16:11 —
👍 2
🔁 0
💬 1
📌 0

We first show this approach can recover known differences. We train Model 1 to use a pink square to make classification decisions and Model 2 to ignore it. Our method, RSVC, isolates this difference.
11.04.2025 16:11 —
👍 2
🔁 0
💬 1
📌 0
We tackle this question by (i) extracting concepts for each model, (ii) using one model to predict the other’s concepts, (iii) and measuring the quality of the prediction.
11.04.2025 16:11 —
👍 3
🔁 0
💬 1
📌 0
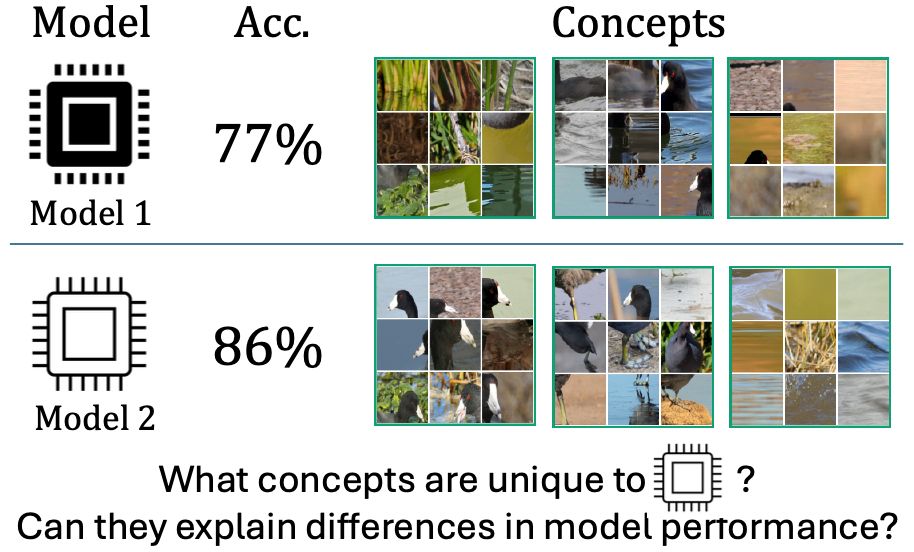
Have you ever wondered what makes two models different?
We all know the ViT-Large performs better than the Resnet-50, but what visual concepts drive this difference? Our new ICLR 2025 paper addresses this question! nkondapa.github.io/rsvc-page/
11.04.2025 16:11 —
👍 26
🔁 9
💬 1
📌 1
Great work! I am curious what the reconstruction error is? Does the model behavior change significantly when using the reconstructed activations?
01.03.2025 23:15 —
👍 0
🔁 0
💬 0
📌 0
Our new piece in Nature Machine Intelligence: LLMs are replacing human participants, but can they simulate diverse respondents? Surveys use representative sampling for a reason, and our work shows how LLM training prevents accurate simulation of different human identities.
17.02.2025 16:36 —
👍 150
🔁 35
💬 9
📌 2
