Setting up DNS resolution between containers with --name is 💯. Also, the IP per container scheme makes networking a piece of cake.
09.07.2025 21:57 — 👍 0 🔁 0 💬 0 📌 0
Native containers in macOS 26 are lightweight & functional. No more Docker or Podman VMs required.
09.07.2025 21:55 — 👍 1 🔁 0 💬 1 📌 0
Had to remind myself today that bfloat16 on Apple Silicon in PyTorch with AMP provides a minimal performance increase for model training or inferencing. It is very beneficial on NVIDIA GPUs because of Tensor Cores, which PyTorch uses for bfloat16 matmuls.
16.04.2025 22:26 — 👍 1 🔁 0 💬 0 📌 0
 16.04.2025 20:20 — 👍 0 🔁 0 💬 0 📌 0
16.04.2025 20:20 — 👍 0 🔁 0 💬 0 📌 0
With gpt2-xl you can drop the positional encodings entirely and get decent output. The smaller the model the more dependent it is on the positional encodings to generate non-garbage output.
14.04.2025 02:05 — 👍 0 🔁 0 💬 0 📌 0
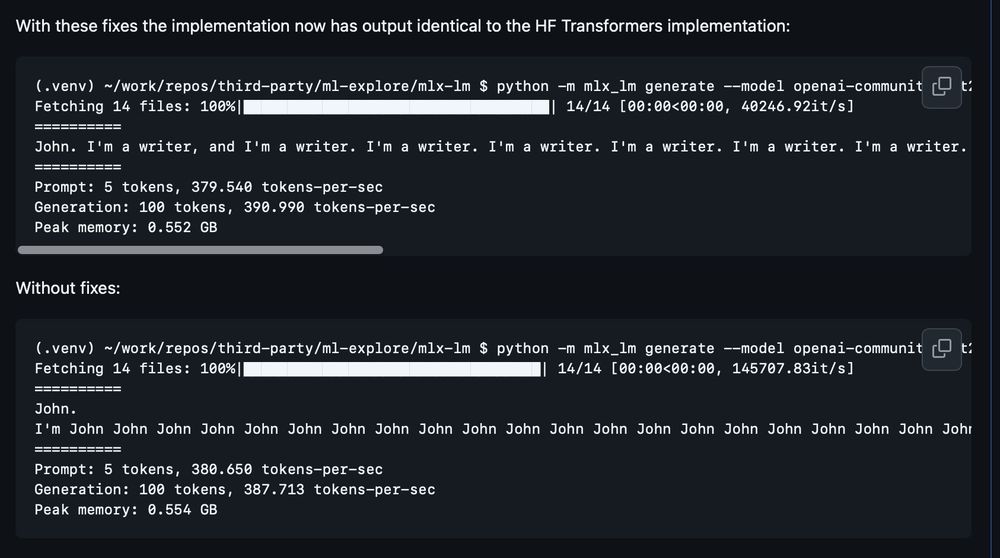
While fixing a KV Cache generation bug today in the MLX GPT-2 implementation that I submitted last year, I discovered that the gpt2 (128M) model is much more dependent on positional encodings than the larger gpt2-xl (1.5B). Guess that explains why linear positional encoding layers were dropped.
14.04.2025 02:04 — 👍 0 🔁 0 💬 1 📌 0
Qwen2.5 models are exceptionally strong at tool calling for their size. Definitely stronger than the Llama 3.1/3.2 models.
18.03.2025 02:21 — 👍 0 🔁 0 💬 0 📌 0
Key Highlights:
• LangChain/LangGraph for powerful, flexible AI agents
• Real-time streaming chat interface with Next.js & SSE
• Multiple RAG patterns with PGVector embeddings
• FastAPI backend, PostgreSQL storage, comprehensive telemetry via OpenTelemetry
12.03.2025 19:37 — 👍 1 🔁 0 💬 1 📌 0
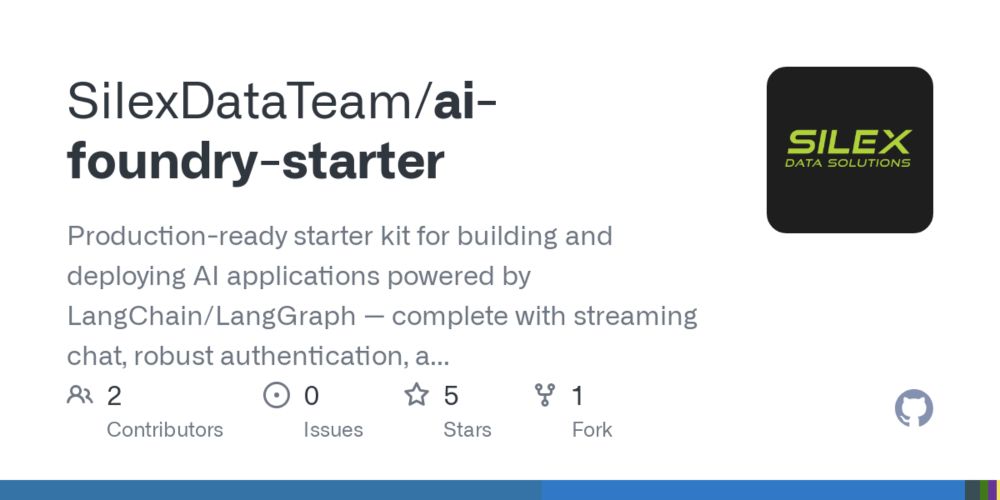
We’re excited to announce the open sourcing of our AI Foundry Starter Template at Silex Data! This production-ready starter kit empowers you to build and deploy AI apps with LangChainAI/LangGraph, featuring streaming chat, robust Keycloak authentication, Kong's multi-model gateway, and OpenShift.
12.03.2025 19:36 — 👍 1 🔁 0 💬 1 📌 0
Building the IBKR C++ API Client Library
Recently, I wanted to use the C++ API client library that Interactive Brokers provides and experiment with some algorithmitic trading and monitoring of my positions. I had hoped there would be some pr...
Recently, I wanted to experiment with some algorithmic trading. Building the Interactive Brokers C++ API client library on macOS & Linux/aarch64 had a few more barriers than I anticipated. Wrote up a brief blog post with the steps. dlewis.io/ibkr-cpp-api/
11.02.2025 23:16 — 👍 0 🔁 0 💬 0 📌 0
Would be nice to see the training code (not just inference code) from DeepSeek for the R1 models. One can hope...
27.01.2025 14:01 — 👍 1 🔁 0 💬 1 📌 0
Some of the training techniques are novel and some have been around for a while now. The combination of FP8/BF16 at training is novel. MHLA and MTP are both interesting, but MTP is only used for training - not inference, though it can be used for speculative decoding (not new).
27.01.2025 13:52 — 👍 0 🔁 0 💬 0 📌 0
DeepSeek has been out for a week now, so why the panic this morning? I can only assume it is because of the app in the App Store rising to #1. Should be a wake up call to OpenAI/etc., but more efficient models that use less compute at inference-time will just drive larger models.
27.01.2025 13:51 — 👍 0 🔁 0 💬 1 📌 0
Whenever code is made more efficient, other code never expands to fill the available compute... This seems to be logic at play this morning on Wall Street and some tech circles re: DeepSeek. Great model, Sputnik moment for foundation model companies, but it isn't over for Nvidia.
27.01.2025 13:51 — 👍 0 🔁 0 💬 1 📌 0
Doing some retro programming: Cocoa-based LLM streaming chat application on OS X 10.5 circa 2009 making calls to a FastAPI back-end, which streams events from a LangChain/LangGraph agent capable of making tool calls. 10.5 did not have a NSJSONSerialization, yet.
25.01.2025 17:05 — 👍 0 🔁 0 💬 0 📌 0
Interesting data point on adoption. Apple does have a great ecosystem for passkeys. It just works. Most of the concern that I’ve heard expressed is around vendor lock-in. Lose your Apple account and you are screwed. The same issue exists for MS and Google, too.
01.01.2025 15:16 — 👍 1 🔁 0 💬 0 📌 0
Gemini 2.0 Flash does become less effective at >50K token lengths. I’ve had much more success starting over with a new conversation and continuing the task than continuing on with the same one.
14.12.2024 03:17 — 👍 4 🔁 0 💬 0 📌 0
Gemini 2.0 Flash from my experience today is definitely stronger on coding tasks than gpt-4o and slightly better than Sonnet 3.5 and o1. The Google-published benchmarks confirm this, as well.
14.12.2024 03:16 — 👍 4 🔁 0 💬 2 📌 0
Gemini 2.0 Flash is pretty good for coding. Just solved a problem I have been working on for the last day with streaming LLM inputs/outputs & tool calls working reliably. Claude Sonnet 3.5 & o1 (not pro) failed.
13.12.2024 19:03 — 👍 1 🔁 0 💬 0 📌 0

API, ChatGPT & Sora Facing Issues
OpenAI's Status Page - API, ChatGPT & Sora Facing Issues.
Thorough RCA from OpenAI on last night’s outage. Was related to a telemetry rollout that overwhelmed K8S internal DNS and exacerbated by the resulting lockout to the K8S admin API. status.openai.com/incidents/ct...
13.12.2024 04:24 — 👍 1 🔁 0 💬 0 📌 0
Getting Siri to use ChatGPT isn’t 100% and the TeX formatting isn’t available in the Siri output when ChatGPT is used. Markdown formatting seems to there at a glance.
12.12.2024 03:57 — 👍 1 🔁 0 💬 0 📌 0
And logged into ChatGPT now on iOS 18.2.
12.12.2024 03:56 — 👍 2 🔁 0 💬 0 📌 0
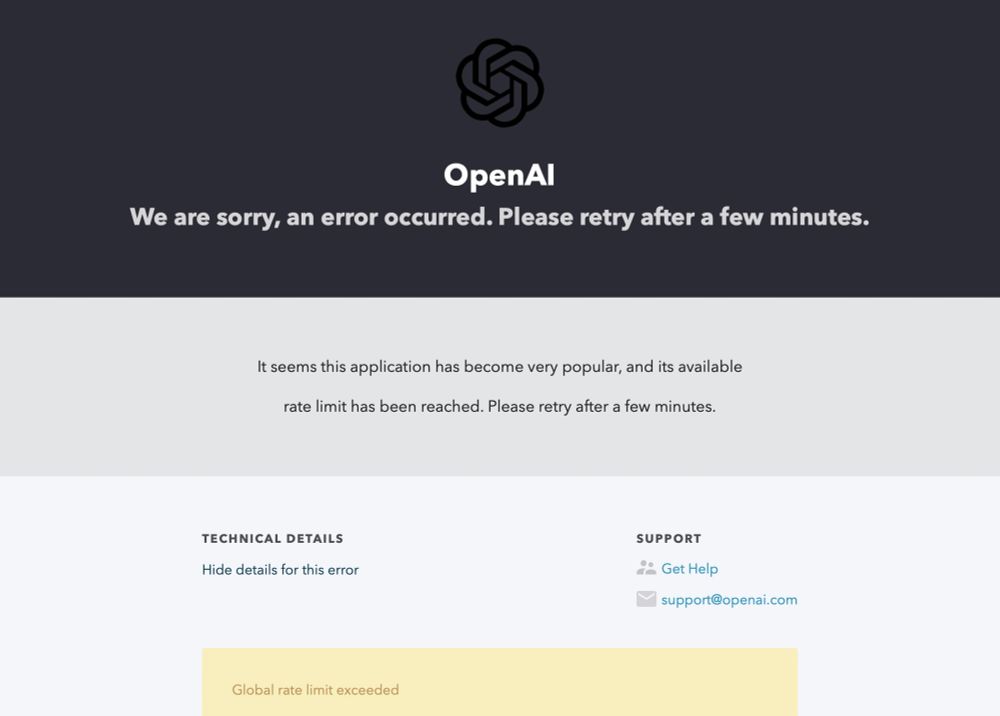
And that global rate limit got hit:
11.12.2024 23:59 — 👍 1 🔁 0 💬 0 📌 0
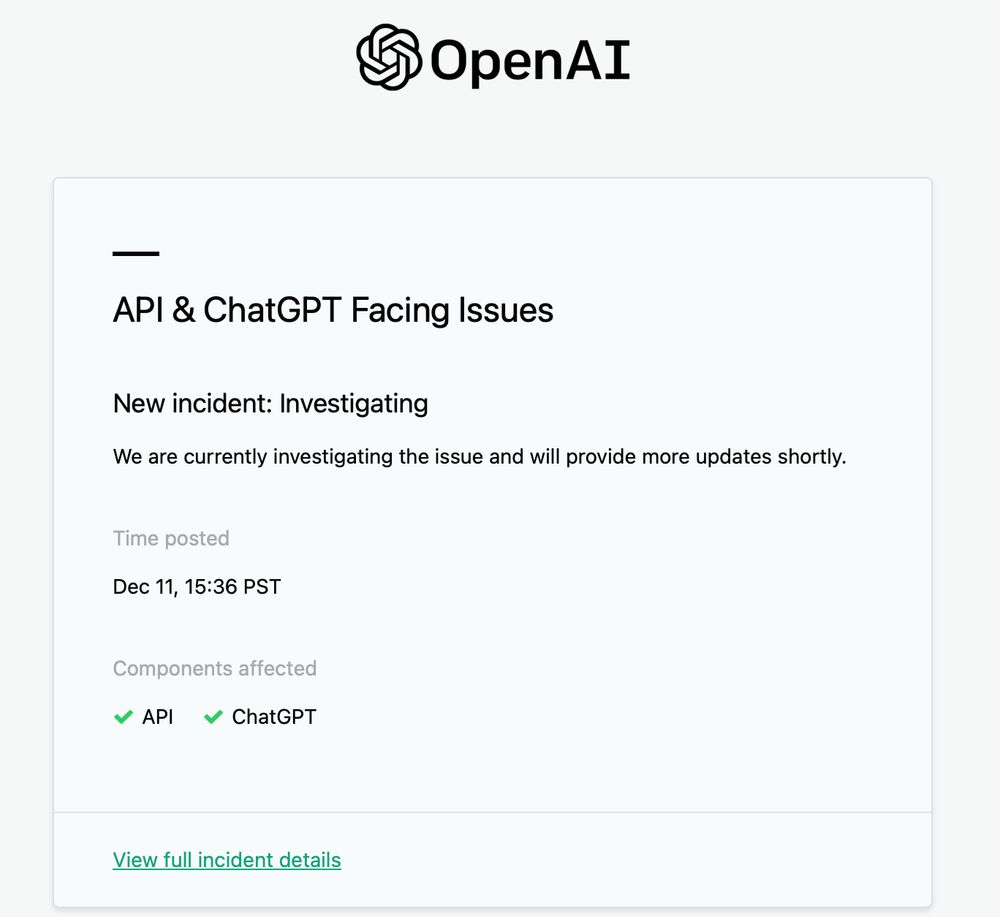
And now there's this:
11.12.2024 23:48 — 👍 1 🔁 0 💬 1 📌 0
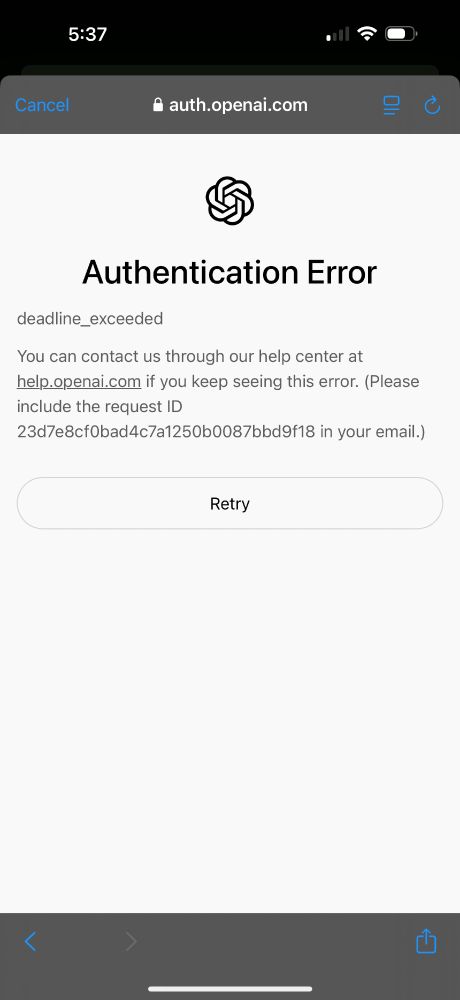
Looks like OpenAI is getting overloaded after the iOS 18.2 rollout. Trying to sign into my account on my phone after the upgrade to test out the new integration.
11.12.2024 23:44 — 👍 1 🔁 0 💬 1 📌 0
Of course, someone using dataclasses or Pylance helps here a lot, but there always seems to be some reverse engineering required when trying to understand someone else's Python code.
05.12.2024 15:59 — 👍 2 🔁 0 💬 0 📌 0
I write Daring Fireball and created Markdown.
macOS security researcher espousing no one's opinions but my own. Dogged follower of #lufc, at least until the world stops going round (IYKYK).
philastokes.com
Mac Software Developer at @ccommand.bsky.social building @dropdmg.bsky.social, @eaglefiler.bsky.social, @spamsieve.bsky.social, and @toothfairymac.bsky.social.
https://mastodon.social/@mjtsai
https://mjtsai.com/blog
Building ChatGPT for iOS and mac at OpenAI
Fan Account | Conta Não-Oficial - Unofficial Account
Scuderia Ferrari F1 Fan Page. All updates, news, live race commentary and more here. Unaffiliated
Charles Leclerc 16 Lewis Hamilton 44
#Tifosi #essereFerrari #ForzaFerrari #F1BSKY #F1 #Ferrari
📖 F1 Understanding Starts by Clicking Follow!
📈Learn To Read F1 Telemetry Data
⚙️ Performance Engineer, PhD in Motorcycle Dynamics
Unlock extra content: buymeacoffee.com/f1dataanalysis
Places to find me: linktr.ee/fdataanalysis
Swift Server Engineer at Apple 🍎🇨🇿🇺🇸 he/him
This is my dev account, see @honzadvorsky.com for my personal alt account. I only speak for myself.
https://github.com/czechboy0
https://honzadvorsky.com
Signal: honzadvorsky.99
WebKit Platform Experience Engineer | B.Eng., Software Engineering | I love coding and sushi and puns and dogs
SwiftUI at · Made in Milan, Italy
Engineering Manager, watchOS SwiftUI @ Apple
Developer Experience at Apple. Designer, prototyper, occasional engineer. Probably dreams in SwiftUI at this point.
“Life is Study!”; Swift Actors, Concurrency & Distributed Systems @ Previously: Reactive Streams (TCK), @akkateam Actors, HTTP & Streams, @geecon Conference, Java Champion. he/him.
FastAPI framework, high performance, easy to learn, fast to code, ready for production. 🚀
Web APIs with Python type hints. 🐍
By @tiangolo.com 🤓
GitHub: https://github.com/fastapi/fastapi
Web: https://fastapi.tiangolo.com/
Creator of @fastapi.tiangolo.com, Typer, SQLModel, Asyncer, etc. 🚀
From 🇨🇴 in 🇩🇪 .
Open Source, APIs, and tools for data/ML. 🤖
Machine Learning Librarian at @hf.co
RecSys, AI, Engineering; Principal Applied Scientist @ Amazon. Led ML @ Alibaba, Lazada, Healthtech Series A. Writing @ eugeneyan.com, aiteratelabs.com.
Professor, Programmer in NYC.
Cornell, Hugging Face 🤗
Working towards the safe development of AI for the benefit of all at Université de Montréal, LawZero and Mila.
A.M. Turing Award Recipient and most-cited AI researcher.
https://lawzero.org/en
https://yoshuabengio.org/profile/