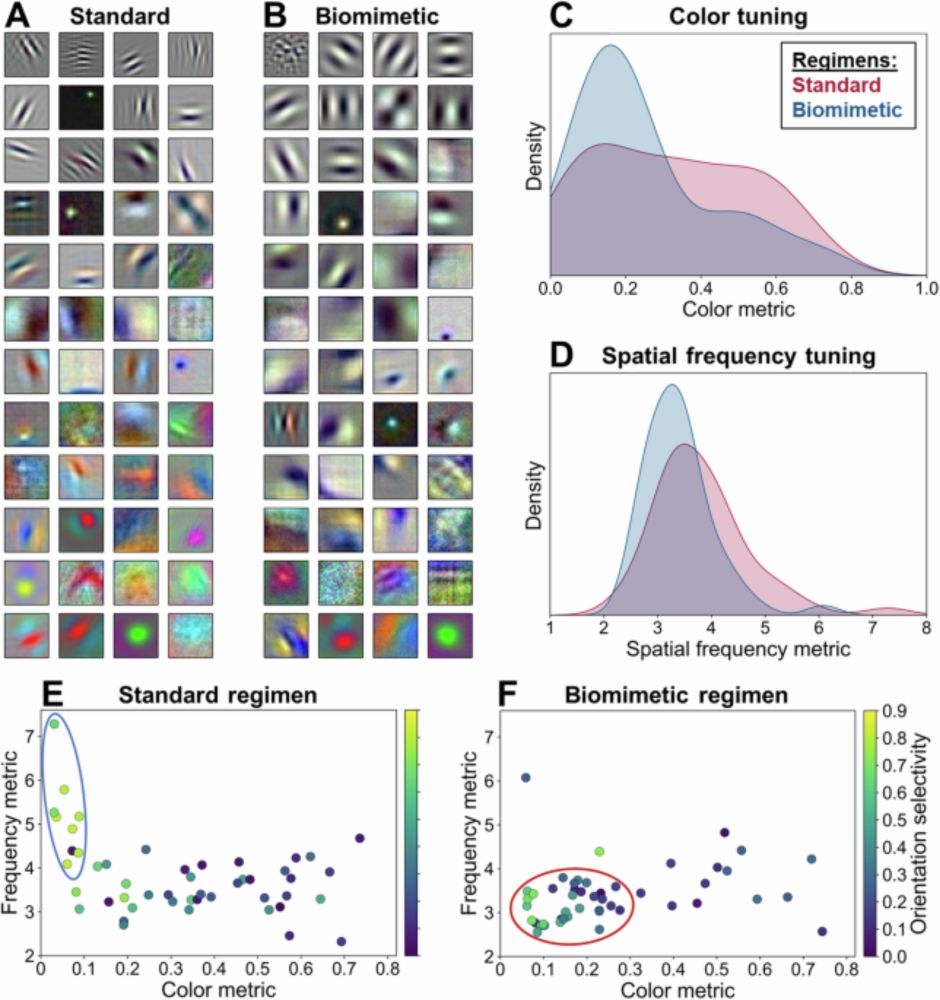
#transformers #neurips #eurips #ibmresearch | Jannis Born
𝗡𝗲𝘂𝗿𝗜𝗣𝗦 𝘀𝗽𝗼𝘁𝗹𝗶𝗴𝗵𝘁 for our work on "𝗤𝘂𝗮𝗻𝘁𝘂𝗺 𝗗𝗼𝘂𝗯𝗹𝘆 𝗦𝘁𝗼𝗰𝗵𝗮𝘀𝘁𝗶𝗰 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀" 🔦
𝘊𝘢𝘯 𝘱𝘳𝘪𝘯𝘤𝘪𝘱𝘭𝘦𝘴 𝘧𝘳𝘰𝘮 𝘲𝘶𝘢𝘯𝘵𝘶𝘮 𝘤𝘰𝘮𝘱𝘶𝘵𝘪𝘯𝘨 𝘣𝘦 𝘣𝘭𝘦𝘯𝘥𝘦𝘥 𝘪𝘯𝘵𝘰 𝘵𝘩𝘦 𝘮𝘰𝘴𝘵 𝘱𝘰𝘸𝘦𝘳𝘧𝘶𝘭 𝘔𝘓 𝘮𝘰𝘥𝘦𝘭𝘴? 🤔
𝗧𝗵𝗲 𝗽𝗿𝗼𝗯𝗹𝗲𝗺 𝗶𝗻 #𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀: Transf...
@jannisblrn.bsky.social wrote a very nice teaser about our Neurips paper Quantum Doubly Stochastic Transformers (spotlight). Our co-authors Filip and Kahn will present it in San Diego, and Jannis in EurIPS. You can find links to the paper, video, and poster below:
www.linkedin.com/posts/jannis...
14.11.2025 07:34 —
👍 2
🔁 1
💬 0
📌 0
🤓 Open position at IBM Research Zurich!
Passionate about AI for maths & curious about Quantum Computing?
Join our team & help to shape the future of computing!
We are offering internships & master theses. If you are looking for a PhD, please apply to the same ad!
👉 www.zurich.ibm.com/careers/2025...
19.09.2025 19:58 —
👍 0
🔁 0
💬 0
📌 0
Paperscraper
Documentation for the paperscraper python package
After several years of usage by the open-source community, our paperscraper package finally has its own Docs available: jannisborn.github.io/paperscraper/
Use #paperscraper for publication keyword search, download PDFs, extract citation statistics and many more! 🚀
13.08.2025 19:58 —
👍 1
🔁 0
💬 0
📌 0
Check out our workflow for AI-driven molecular design. We’ve successfully validated this experimentally already (papers coming soon)!
30.07.2025 22:00 —
👍 3
🔁 1
💬 0
📌 0

GitHub - tum-ai/number-token-loss: A regression-alike loss to improve numerical reasoning in language models
A regression-alike loss to improve numerical reasoning in language models - tum-ai/number-token-loss
Jonas Zausinger*, Lars Pennig*, Anamarija Kozina, Sean Sdahl, Julian Sikora, Adrian Dendorfer, Timofey Kuznetsov, Mohamad Hagog, Nina Wiedemann, Kacper Chlodny, Vincent Limbach, Anna Ketteler, Thorben Prein, Vishwa Mohan Singh & Michael Danziger.
💻 GitHub code: ibm.biz/ntl-code
03.07.2025 21:20 —
👍 0
🔁 0
💬 0
📌 0
Regress, Don’t Guess – Number Token Loss
A regression-like loss on number tokens for language models.
5. Text-task friendly: Doesn’t interfere with CE on purely textual tasks 📚
6. Scalable: Tested up to 3B, e.g., with hashtag#IBMGranite 3.2🚀
7. Plug-and-play: It’s “just a loss,” so it’s super easy to adopt 🔢
📄 ICML paper: ibm.biz/ntl-paper
03.07.2025 21:20 —
👍 0
🔁 0
💬 1
📌 0
Regress, Don't Guess -- A Regression-like Loss on Number Tokens for Language Models
While language models have exceptional capabilities at text generation, they lack a natural inductive bias for emitting numbers and thus struggle in tasks involving quantitative reasoning, especially ...
1. Better math performance: NTL consistently boosts accuracy on math benchmarks (e.g., GSM-8K) 📊
2. Lightning-fast: 100× faster to compute than CE, so there’s no training overhead ⚡
3. Model-agnostic: Works with Transformers, Mamba, etc. 🤖
(continued ⬇️ )
🎛️ Hugging Face Spaces demo: ibm.biz/ntl-demo
03.07.2025 21:20 —
👍 0
🔁 0
💬 1
📌 0

In our upcoming #ICML2025 paper, we introduce the #NumberTokenLoss (NTL) to address this -- see the demo above! NTL is a regression-style loss computed at the token level—no extra regression head needed. We propose adding NTL on top of CE during LLM pretraining. Our experiments show: (see ⬇️ )
03.07.2025 21:20 —
👍 1
🔁 1
💬 1
📌 0
#ICML Why are LLMs so powerful but still suck at math? 🤔 A key problem is cross-entropy loss: It is nominal-scale, so tokens are unordered. That makes sense for words, but not for numbers. For a "5" label, predicting “6” or “9” gives the same loss 😱 Yes, it's crazy! No, nobody has fixed this yet! ⬇️
03.07.2025 21:20 —
👍 2
🔁 0
💬 1
📌 0
Great to hear! 🙃 Let me know if there are questions
16.01.2025 20:58 —
👍 1
🔁 0
💬 0
📌 0
Redirecting
Our next journal club meeting will be discussing "A Computational Investigation of Inventive Spelling and the 'Lesen durch Schreiben' Method" by @jannisblrn.bsky.social et al. on 23 Jan 2025, 11am - 12pm (GMT+1). Join us by emailing us at gewonn.contact.us@gmail.com, and stay tuned for more news!
16.01.2025 16:20 —
👍 3
🔁 3
💬 1
📌 1

If you're @neuripsconf.bsky.social and into #OptimalTransport & bio, dont miss on Alice Driessen's spotlight talk on #ConditionalMongeGap for modeling CAR Response. Today #AIDrugX workshop!
Positive results on OOD perturbations -> accurate gene expression prediction. Paper: ibm.biz/carot-pre
15.12.2024 21:29 —
👍 4
🔁 1
💬 0
📌 0

Full poster
14.12.2024 22:48 —
👍 0
🔁 0
💬 0
📌 0

Number token loss
A new loss improves math capabilities in language models! The loss is model-agnostic and only requires to know which tokens represent numbers.
No computational overhead but better performance.
Poster today @NeurIPS - MathAI Workshop! Thx to collaborators from TUM AI!
Paper: arxiv.org/abs/2411.02083
14.12.2024 22:31 —
👍 7
🔁 0
💬 1
📌 0
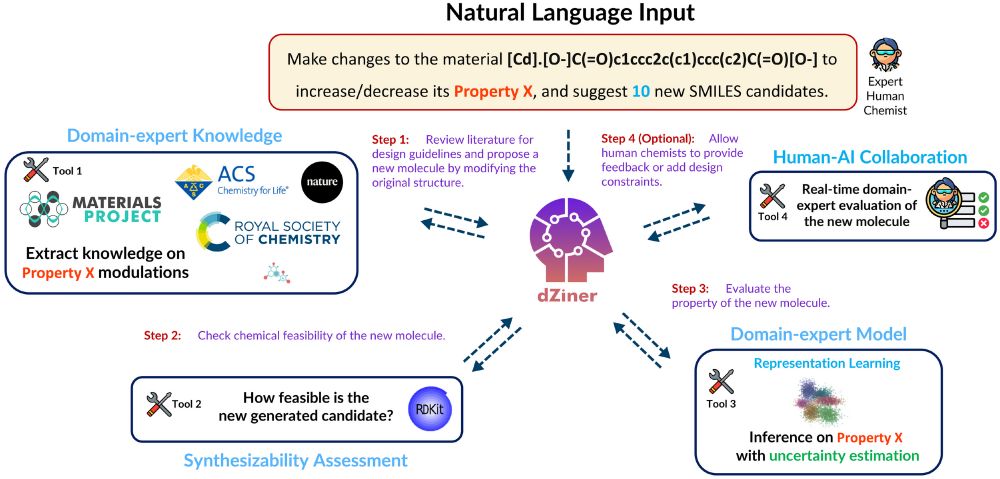
Can we iteratively design small molecules with desired target properties, simply by sending messages on Slack? YES!
Super excited to give a live demo on🤖dZiner🧪 during the SPOTLIGHT 🔦 talk at #AI4Mat #NeurIPS2024!
Preprint: lnkd.in/e-24AEHC
Code: lnkd.in/egF4hGCg
06.12.2024 22:33 —
👍 14
🔁 3
💬 0
📌 0