🙌🥳Had great fun doing this during my summer internship with folks from Apple (Yuan Zhang, Joel Ruben Antony Moniz, Xiou Ge, Bo-Hsiang Tseng, Dhivya Piraviperumal, Hong Yu) and USC (@swabhs.bsky.social)
Looking forward to the feedback! 🙂
#LLMs #NLProc
(7/n)
30.04.2025 18:54 —
👍 0
🔁 0
💬 0
📌 0
🚫Bottom line: There’s no single metric that captures hallucinations reliably across the board.
🎯Our work highlights the need for robust, context-aware, and generalizable hallucination detection tools as a prerequisite to meaningful mitigation.
(6/n)
30.04.2025 18:54 —
👍 0
🔁 0
💬 1
📌 0

✅What works better?
Unsurprisingly, GPT4-based evaluators show the highest reliability with humans across settings 🌟
Using ensembles of multiple metrics is a promising avenue⭐️
Instruction tuning & mode-seeking decoding help reduce hallucinations📈
(5/n)
30.04.2025 18:54 —
👍 0
🔁 0
💬 1
📌 0
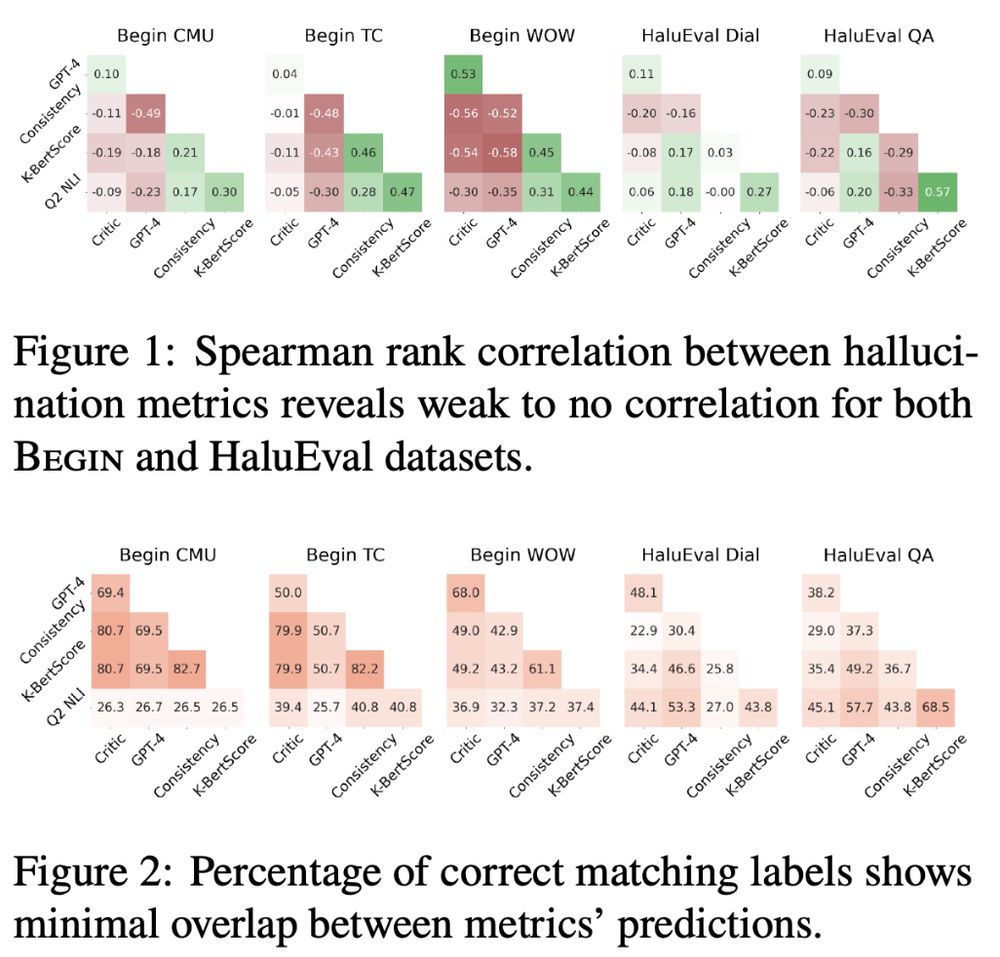

Our findings highlight:
⚠️Many existing metrics show poor alignment with human judgments
⚠️The inter-metric correlation is also weak
⚠️The show limited generalization across datasets, tasks, and models
⚠️They do not consistent improvement with larger models
(4/n)
30.04.2025 18:54 —
👍 0
🔁 0
💬 1
📌 0
🧐Focusing on faithfulness and factuality errors in QA and dialogue tasks, we study diverse metrics spanning:
1. Syntactic and semantic similarity
2. Natural language inference
3. Multi-step question answering pipelines
4. Custom-trained models
5. SOTA LLMs as judge.
(3/n)
30.04.2025 18:54 —
👍 0
🔁 0
💬 1
📌 0
🤔Despite a surge in research on hallucination mitigation, few ask the critical questions:
1. Are the metrics capturing the hallucinations effectively?
2. Do they align with each other and the human notion of hallucination?
3. Do they generalize across different settings?
(2/n)
30.04.2025 18:54 —
👍 0
🔁 0
💬 1
📌 0

Hallucinations in LLMs are real—and so are the problems with how we measure them 📉
Our latest work questions the generalizability of hallucination detection metrics across tasks, datasets, model sizes, training methods, and decoding strategies 💥
arxiv.org/abs/2504.18114
(1/n)
30.04.2025 18:54 —
👍 1
🔁 0
💬 1
📌 0
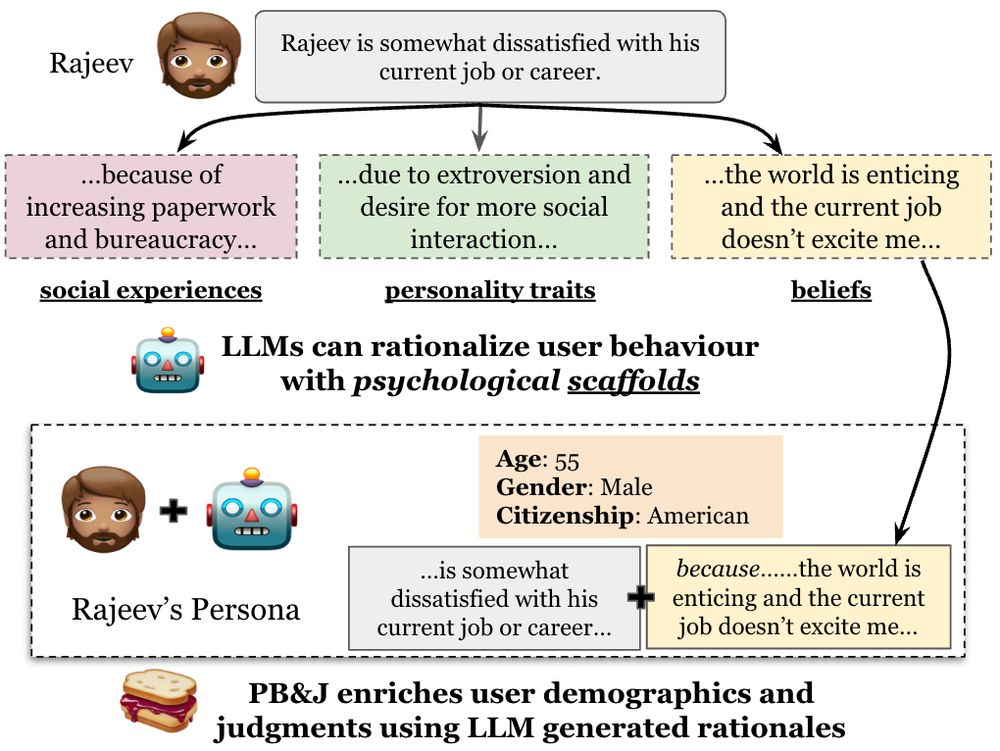
Reasoning about the "why" behind user behavior can improve LLM personas! ✨🧠📈
📝Excited to share our new work: Improving LLM Personas via Rationalization with Psychological Scaffolds
🔗 arxiv.org/abs/2504.17993
🧵 (1/n)
29.04.2025 01:05 —
👍 14
🔁 4
💬 1
📌 1

NLP grad students
Join the conversation
There's too many starter packs.
👇 Here's a list, mostly for NLP, ML, and related areas.
01.12.2024 03:05 —
👍 40
🔁 11
💬 3
📌 2

#socalnlp is the biggest it's ever been in 2024! We have 3 poster sessions up from 2! How many years until it's a two-day event?? 🤯
22.11.2024 21:50 —
👍 26
🔁 3
💬 1
📌 0
Started a SoCal AI/ML/NLP researchers starter pack! It's a bit sparse right now, and perhaps more NLP heavy, but hey, nominate yourself and others! go.bsky.app/6QckPj9
19.11.2024 15:28 —
👍 43
🔁 8
💬 17
📌 1
🙋🏻♂️🙋🏻♂️
19.11.2024 23:31 —
👍 1
🔁 0
💬 1
📌 0
Hey John, thanks for starting this packet! Could you please add me as well?
18.11.2024 18:09 —
👍 0
🔁 0
💬 1
📌 0
Can you please add me to the pack! Looking forward to interacting with everyone!
15.11.2024 06:59 —
👍 1
🔁 0
💬 1
📌 0
Great initiative!! Can you please add me! Looking forward to interacting with everyone!!💯
15.11.2024 06:56 —
👍 0
🔁 0
💬 1
📌 0
