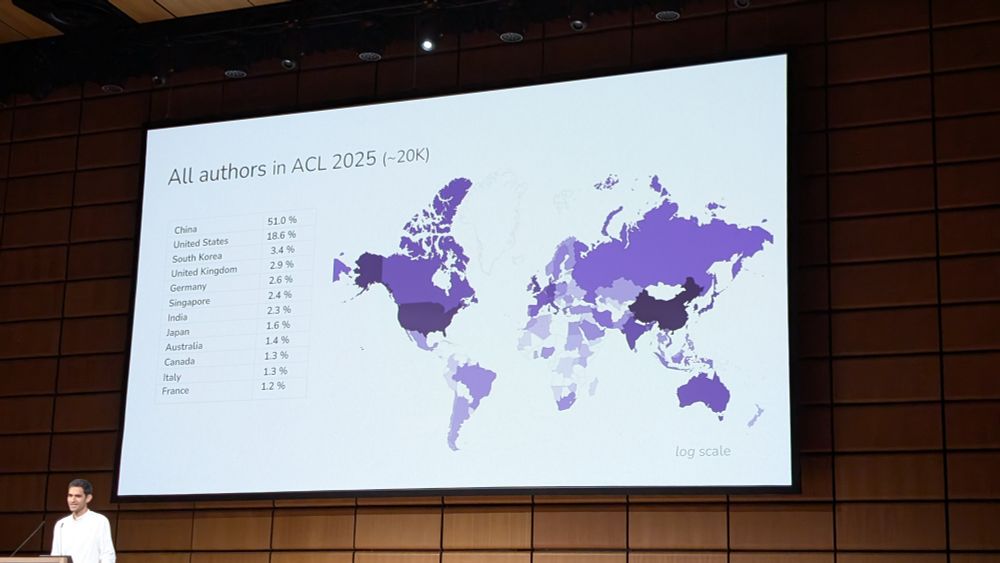
20000 authors! #acl2025
28.07.2025 07:12 — 👍 2 🔁 2 💬 0 📌 0
@ltgoslo.sigmoid.social.ap.brid.gy
We are Language Technology Group (LTG) at the University of Oslo, Norway. We do research on a number of topics related to Natural Language Processing (NLP), a […] [bridged from https://sigmoid.social/@ltgoslo on the fediverse by https://fed.brid.gy/ ]
20000 authors! #acl2025
28.07.2025 07:12 — 👍 2 🔁 2 💬 0 📌 0
Language Technology Group #Oslo at the #ACL2025 conference in #Vienna today
#NLProc
You are also welcome to the "Multilingualism: from data crawling to evaluation" birds-of-a-feather (BoF) event, which is co-organized by the #HPLT project.
Join us to discuss web-scale text data collection and processing, as well as open multilingual #LLM training and evaluation. You will have […]
If you are attending the ACL 2025 conference in Vienna, come to the poster presenting the latest #HPLT v2 datasets (the paper is available here: https://arxiv.org/abs/2503.10267).
You can find the HPLT folks on Wednesday, July 30, 11:00 at the in-person poster session, Level 0, Exhibit Halls X4 […]
In addition to the previously mentioned five papers: we are very proud for the LTG Master students who got their paper accepted to the ACL Fact Extraction and Verification Workshop (FEVER).
A big shout-out to Eivind Morris Bakke, Nora Winger Heggelund and their paper "(Fact) Check Your Bias"! […]
We're hiring! A postdoc-level researcher position in NLP, focusing on generative approaches to event extraction, is open at the University of Oslo. The contract is for 30 months. Closing date 11 Aug. Come join us! […]
30.06.2025 12:06 — 👍 0 🔁 3 💬 0 📌 0
This is how Language Technology Group at the University of Oslo looks like these days :)
#NLProc #Norway #Oslo

5. "Systematic Generalization in Language Models Scales with Information Entropy", defining a framework to measure entropy in sequence-to-sequence tasks. Authored by Sondre Wold, Lucas Charpentier, Étienne Simon
https://arxiv.org/abs/2505.13089 (ACL Findings)
See you in Vienna!
(end of 🧵)
"#NorEval: A Norwegian Language Understanding and Generation Evaluation Benchmark", introducing a new evaluation suite for benchmarking of #Norwegian generative language models. Authored by Vladislav Mikhailov, David Samuel, Andrey Kutuzov, Erik Velldal, Lilja Øvrelid (LTG), Tita Enstad, Hans […]
06.06.2025 13:19 — 👍 0 🔁 0 💬 0 📌 0
3. "Re-identification of De-identified Documents with Autoregressive Infilling" challenging the existing methods of masking personally identifiable information. Authored by Lucas Charpentier and Pierre Lison.
https://arxiv.org/abs/2505.12859 (main ACL)
2. "Circuit Compositions: Exploring Modular Structures in Transformer-Based Language Models", studying modularity of transformer based language models. Authored by Sondre Wold (LTG), Philipp Mondorf, Barbara Plank
https://arxiv.org/abs/2410.01434 (main ACL)
1. "An Expanded Massive Multilingual Dataset for High-Performance Language Technologies (HPLT)", describing a new generation of the #HPLT web-crawled corpora in 193 languages. LTG co-authors: Nikolay Arefyev, Mariia Fedorova, Andrey Kutuzov, Petter Mæhlum, Vladislav Mikhailov, Stephan Oepen […]
06.06.2025 13:17 — 👍 0 🔁 0 💬 0 📌 0Language Technology Group #Oslo will be presenting five papers at the #ACL2025NLP conference this summer in #Vienna: 🧵
#NLProc
