
Also very thankful for the research environment provided by @ellis.eu and @mpi-is.bsky.social, which made this PhD such an inter-european experience!
04.08.2025 14:59 — 👍 1 🔁 0 💬 0 📌 0Also very thankful for the research environment provided by @ellis.eu and @mpi-is.bsky.social, which made this PhD such an inter-european experience!
04.08.2025 14:59 — 👍 1 🔁 0 💬 0 📌 0Huge thanks also to my thesis committee Peter Gehler, Matthias Bethge, @wielandbrendel.bsky.social and @phillipisola.bsky.social, and of course all the wonderful people and collaborators I had the pleasure of spending time and working with these past years!
04.08.2025 14:59 — 👍 2 🔁 0 💬 1 📌 0


💫 After four PhD years on all things multimodal, pre- and post-training, I’m super excited for a new research chapter at Google DeepMind 🇨🇭!
Biggest thanks to @zeynepakata.bsky.social and Oriol Vinyals for all the guidance, support, and incredibly eventful and defining research years ♥️!
How does lifelong knowledge editing currently hold up in the real world? Fun new work probing where we are at these days with injecting new knowledge into LLMs!
08.04.2025 19:59 — 👍 2 🔁 0 💬 0 📌 0
📄 Disentangled Representation Learning with the Gromov-Monge Gap
with Théo Uscidda, Luca Eyring, @confusezius.bsky.social, Fabian J Theis, Marco Cuturi
📄 Decoupling Angles and Strength in Low-rank Adaptation
with Massimo Bini, Leander Girrbach
Our EML team has 4 #ICLR25 Papers accepted! I am proud of my students and grateful to be a part of many successful collaborations. More details will appear on our website (www.eml-munich.de) but here are the snapshots.
24.01.2025 20:02 — 👍 19 🔁 2 💬 1 📌 0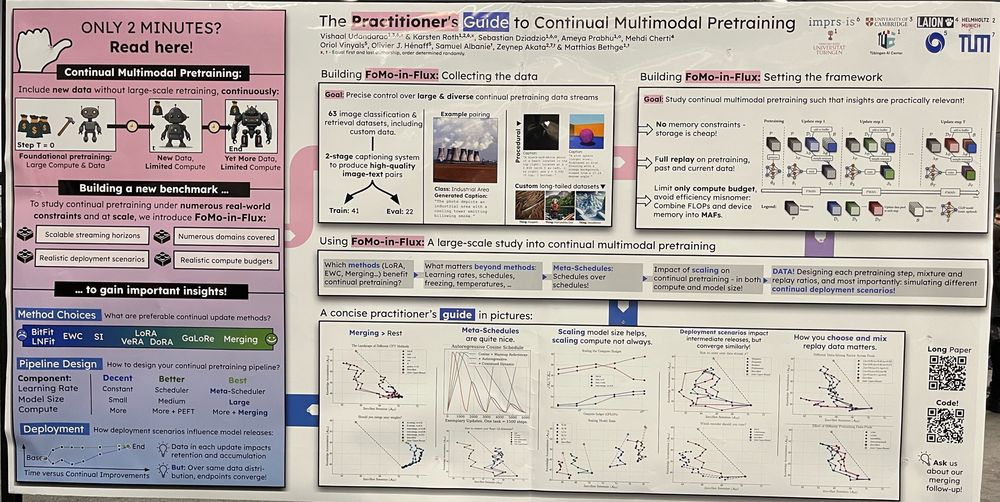
The Practitioner's Guide to Continual Multimodal Pretraining @dziadzio.bsky.social @confusezius.bsky.social @vishaalurao.bsky.social @bayesiankitten.bsky.social
12.12.2024 02:19 — 👍 24 🔁 4 💬 0 📌 0
Can we enhance the performance of T2I models without any fine-tuning?
We show that with our ReNO, Reward-based Noise Optimization, one-step models consistently surpass the performance of all current open-source Text-to-Image models within the computational budget of 20-50 sec!
#NeurIPS2024
How far can you push model merging over time, as more experts and options to model-merge arise?
We comprehensively and systematically investigate this in our new work, check it out!
Co-led with @vishaalurao.bsky.social, and with a wonderful team: @dziadzio.bsky.social @bayesiankitten.bsky.social Mehdi Cherti, Oriol Vinyals @olivierhenaff.bsky.social, Samuel Albanie, @bethgelab.bsky.social and @zeynepakata.bsky.social!
10.12.2024 16:42 — 👍 0 🔁 0 💬 0 📌 0
We will present on Wednesday - East Exhibit Hall A-C #3703 ☺️. We've also released the entire codebase with all the methods and 60+ dataloaders that can be mixed and matched in any fashion to study continual pretraining!
10.12.2024 16:42 — 👍 4 🔁 0 💬 1 📌 0
😵💫 Continually pretraining large multimodal models to keep them up-to-date all-the-time is tough, covering everything from adapters, merging, meta-scheduling to data design and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!

🎉 Congratulations to our newly accepted ELLIS Fellows & Scholars in 2024! Top researchers in #MachineLearning join the network to advance science & mentor the next generation. #ELLISforEurope #AI
🌍 Know someone on the list? bit.ly/3ZJd9Cz
Tag them in a reply with congratulations.

🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
Read our paper:
Context-Aware Multimodal Pretraining
Now on ArXiv
Can you turn vision-language models into strong any-shot models?
Go beyond zero-shot performance in SigLixP (x for context)
Read @confusezius.bsky.social thread below…
And follow Karsten … a rising star!
Oh that's a really cool paper! Thanks for the pointer!
29.11.2024 07:22 — 👍 1 🔁 0 💬 0 📌 0
Beautiful paper! 😍😍😍
Captions go above the tables, but otherwise aesthetically very pleasing.
Oh neat, do you have a link? 😁
28.11.2024 16:32 — 👍 0 🔁 0 💬 2 📌 0
More than zero-shot generalization, few-shot *adaptation* is critical for many applications.
We find simple changes to multimodal pretraining are sufficient to yield outsized gains on a wide range of few-shot tasks.
Congratulations @confusezius.bsky.social on a very successful internship!
We maintain strong zero-shot transfer of CLIP / SigLIP across model size and data scale, while achieving up to 4x few-shot sample efficiency and up to +16% performance gains!
Fun project with @confusezius.bsky.social, @zeynepakata.bsky.social, @dimadamen.bsky.social and
@olivierhenaff.bsky.social.


LIxP was carefully designed and tested for scalability!
LIxP also maintains the strong zero-shot transfer of CLIP and SigLIP backbones across model sizes (S to L) and data (up to 15B), and allows up to 4x sample efficiency at test time, and up to +16% performance gains!


In LIxP, we utilize a learnable temperature separation and a simple cross-attention-based formalism to augment existing contrastive vision-language training.
We teach models what to expect at test-time in few-shot scenarios.
They can struggle with applications that require operating on new context, e.g. few-shot adaptation.
Why? They do not explicitly train for that!
We find a surrogate objective to optimize for -- context-aware language-image pretraining (LIxP)
This was an insightful project I worked on at Google DeepMind alongside the amazing @zeynepakata.bsky.social , @dimadamen.bsky.social , @ibalazevic.bsky.social and @olivierhenaff.bsky.social:
👉Language-image pretraining with CLIP or SigLIP is widely used due to strong zero-shot transfer, but ....
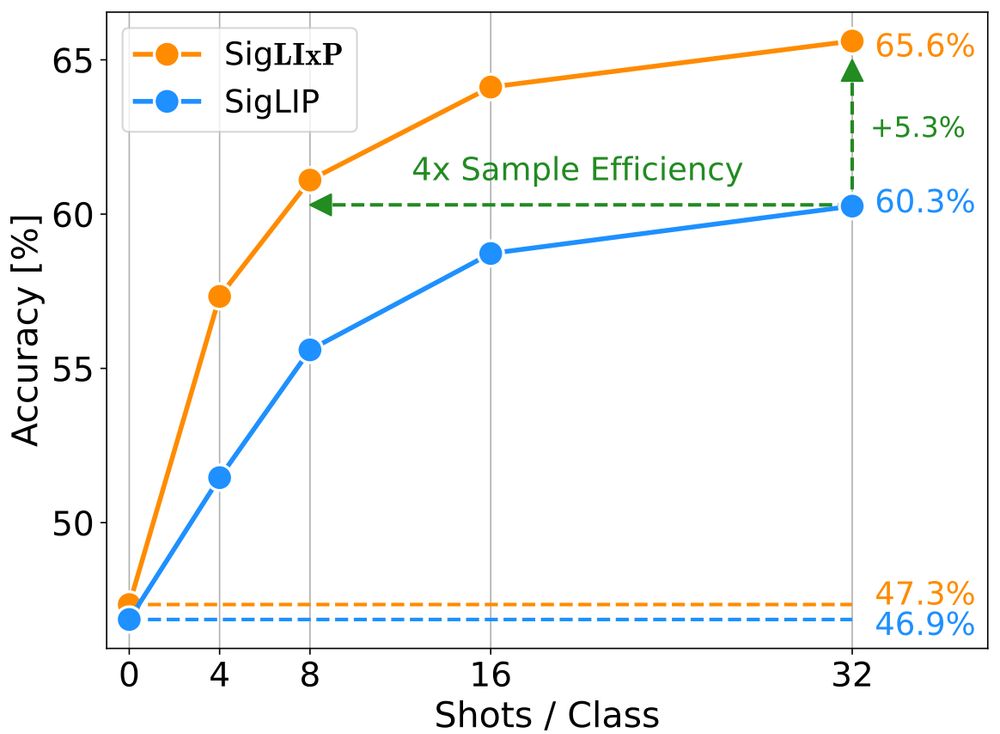
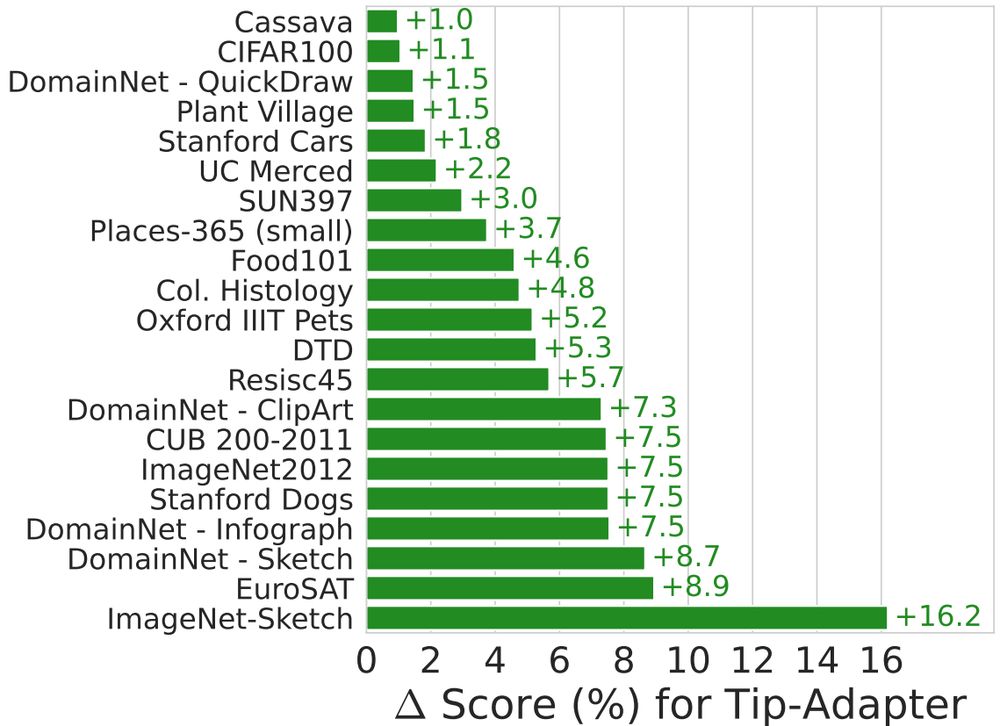

🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Hi 👋 We're glad to be here on @bsky.app and looking forward to engaging in this community. But first, learn a little more about us...
#ELLISforEurope #AI #ML #CrossBorderCollab #PhD
Cool starterpack, would love to be added as well :)
20.11.2024 09:34 — 👍 1 🔁 0 💬 1 📌 0