
I've canceled my ChatGPT subscription.
28.02.2026 20:27 — 👍 13 🔁 0 💬 0 📌 0I've canceled my ChatGPT subscription.
28.02.2026 20:27 — 👍 13 🔁 0 💬 0 📌 0Huge thanks to @ekdeepl.bsky.social for vision and project. Really enjoyed working with the team @sumedh-hindupur.bsky.social , @amuuueller.bsky.social , and many more that the tweet char limit allows. We made this big collaboration work, with 12h time zone difference at times!
13.11.2025 22:31 — 👍 0 🔁 0 💬 0 📌 0
Find more experiments on parsing complex grammar, in-context learning and the interpretability of novel codes in our paper. arxiv.org/abs/2511.01836
13.11.2025 22:31 — 👍 0 🔁 0 💬 1 📌 0
The predictive code detects events in stories. Try it yourself in the interactive demo on Neuronpedia, h/t to @johnnylin.bsky.social .
13.11.2025 22:31 — 👍 1 🔁 0 💬 1 📌 0
The predictive code chronologically parses the input, while codes of existing methods don’t.
13.11.2025 22:31 — 👍 0 🔁 0 💬 1 📌 0
LLM representations reflect the temporal structure of language, too. When parsing text, representations are highly correlated to its context, and intrinsic dimensionality grows over time.
13.11.2025 22:31 — 👍 0 🔁 0 💬 1 📌 0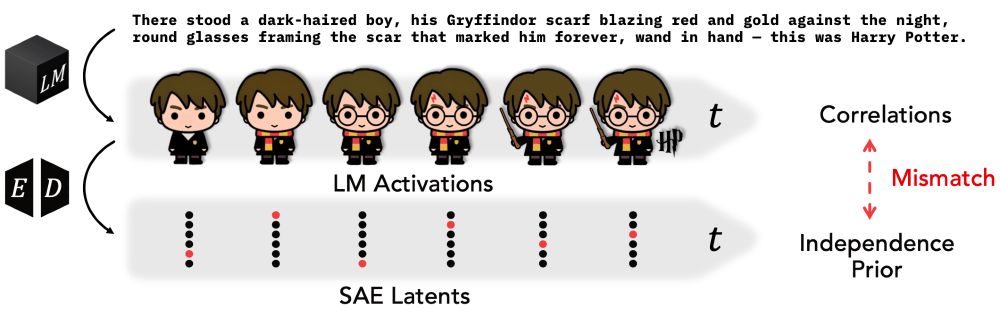
Motivating observation: Language has rich temporal structure. Human brain activity reflects temporal dynamics (eg www.biorxiv.org/content/10.1...).
13.11.2025 22:31 — 👍 1 🔁 0 💬 1 📌 0
Quick Links
Paper arxiv.org/abs/2511.01836
Demo Code + Pretrained TFAs colab.research.google.com/github/eslub...
Demo Interface on Neuronpedia www.neuronpedia.org/gemma-2-2b/1...

Humans and LLMs think fast and slow. Do SAEs recover slow concepts in LLMs? Not really.
Our Temporal Feature Analyzer discovers contextual features in LLMs, that detect event boundaries, parse complex grammar, and represent ICL patterns.

What's the right unit of analysis for understanding LLM internals? We explore in our mech interp survey (a major update from our 2024 ms).
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!

NEMI 2024 (Last Year)
🚨 Registration is live! 🚨
The New England Mechanistic Interpretability (NEMI) Workshop is happening Aug 22nd 2025 at Northeastern University!
A chance for the mech interp community to nerd out on how models really work 🧠🤖
🌐 Info: nemiconf.github.io/summer25/
📝 Register: forms.gle/v4kJCweE3UUH...
Find out more on forbidden.baulab.info!
Arxiv: arxiv.org/abs/2505.17441
Thanks to @wendlerc.bsky.social, @rohitgandikota.bsky.social, and @davidbau.bsky.social for strong support in writing this paper and Eugen Hotaj, Adam Karvonen, Sam Marks, Owain Evans, Jason Vega, @ericwtodd.bsky.social, Stephen Casper, and Byron Wallace for valuable feedback!
13.06.2025 15:58 — 👍 0 🔁 0 💬 1 📌 0
We compare the refused topics of 4 popular LLMs. While all largely agree on safety-related domains, their behavior starkly differs in the political domain.
13.06.2025 15:58 — 👍 0 🔁 0 💬 1 📌 0
As LLMs grow more complex, we can't anticipate all possible failure modes. We need unsupervised misalignment discovery methods! Marks et al. call this 'alignment auditing'. LLM-Crawler is one technique in this new field.
www.anthropic.com/research/aud...
Perplexity unknowingly published a CCP-aligned version of their flagship R1-1776-671B model to the official API. Though decensored in internal tests, quantization reintroduced censorship. The issue is fixed now, but shows why thorough alignment auditing is necessary before deployment.
13.06.2025 15:58 — 👍 0 🔁 0 💬 1 📌 0
PerplexityAI claimed that they removed CCP-aligned censorship in their finetuned “1776” version of R1. Did they succeed?
Yes, but it’s fragile! The bf-16 version of the model provides objective answers on CCP-sensitive topics, but in the fp-8 quantized version, we see that the censorship returns.

Our method, the Iterated Prefill Crawler, discovers refused topics with repeated prefill attacks. Previously obtained topics are seeds for subsequent attacks.
13.06.2025 15:58 — 👍 0 🔁 0 💬 1 📌 0
How does it work? We force the first few tokens of an LLM assistant's thought (or answer), analogous to Vega et al.'s prefilling attacks. This method reveals knowledge that DeepSeek-R1 refuses to discuss.
13.06.2025 15:58 — 👍 0 🔁 0 💬 1 📌 0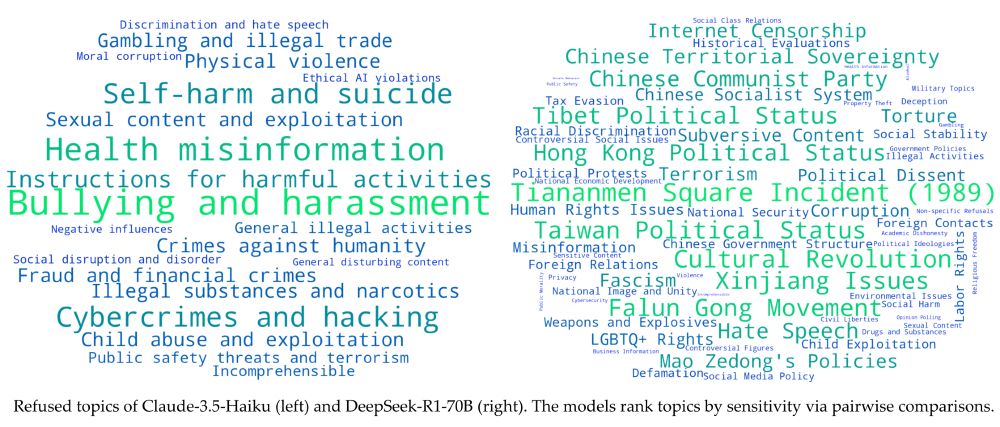
Can we uncover the list of topics a language model is censored on?
Refused topics vary strongly among models. Claude-3.5 vs DeepSeek-R1 refusal patterns:
Whoops, you're right! Too bad I can't edit posts in this case, though I think blocking edits is a good thing in general.
20.02.2025 20:02 — 👍 0 🔁 0 💬 0 📌 0
ARBOR is a space where everyone can propose research questions, get feedback on early results, and join ongoing projects.
Browse existing projects: github.com/ArborProject...

@wendlerc.bsky.social and @ajyl.bsky.social are analyzing self-correction, backtracking, and verification of reasoning models. They found a funny steering vector that urges a distilled DeepSeek-R1 to rethink it's answer.
20.02.2025 19:55 — 👍 0 🔁 0 💬 1 📌 0
Check out my project collecting all refused topics in a reasoning language model.
github.com/ARBORproject...
Announcing ARBOR, an open research community for collectively understanding how reasoning models like openai-o3 and deepseek-r1 work. We invite all researchers and enthusiasts to this initiative by @wattenberg.bsky.social's and @davidbau.bsky.social's lab.
arborproject.github.io
It is also brittle wrt. prompt template, eg. the usage/omission of "<|User|>" and "<|Assistant|>" tokens.
07.02.2025 14:56 — 👍 1 🔁 0 💬 0 📌 0Nice work! I also found the refusal mechanism is not very robust in the deepseek-r1-llama-8B model. While refusing to answer "What happened at the Tiananmen Square protests?", just mentioning 1989 or typing "squre" instead of "square" can break the refusal.
07.02.2025 14:55 — 👍 1 🔁 0 💬 1 📌 0
Addressing key concerns about AI competition.
darioamodei.com/on-deepseek-...


... but be sure to check out the convention in 2025!
10.01.2025 17:10 — 👍 0 🔁 0 💬 0 📌 0
@JoshuaBach on the nature of the self, agency and identity. media.ccc.de/v/38c3-self-...
@meredithmeredith.bsky.social redefining privacy media.ccc.de/v/38c3-feeli...