

📊We match the performance of DeepSeek-Distill-Qwen-7B by finetuning Qwen-7B-Math-Instruct on our dataset.
🔎 Read our blog post for all the nitty gritty details: huggingface.co/blog/open-r1...
📊We match the performance of DeepSeek-Distill-Qwen-7B by finetuning Qwen-7B-Math-Instruct on our dataset.
🔎 Read our blog post for all the nitty gritty details: huggingface.co/blog/open-r1...
⏳ Automated filtering: We apply Math Verify to only retain problems with at least one correct answer. We also leverage Llama3.3-70B-Instruct as a judge to retrieve more correct examples (e.g for cases with malformed answers that can’t be verified with a rules-based parser)
10.02.2025 18:09 — 👍 0 🔁 0 💬 1 📌 0📀512 H100s running locally: Instead of relying on an API, we leverage vLLM and SGLang to run generations locally on our science cluster, generating 180k reasoning traces per day.
10.02.2025 18:09 — 👍 0 🔁 0 💬 1 📌 0🐳 800k R1 reasoning traces: We generate two answers for 400k problems using DeepSeek R1. The filtered dataset contains 220k problems with correct reasoning traces.
10.02.2025 18:09 — 👍 0 🔁 0 💬 1 📌 0
What’s new compared to existing reasoning datasets?
♾ Based on NuminaMath 1.5: we focus on math reasoning traces and generate answers for problems in NuminaMath 1.5, an improved version of the popular NuminaMath-CoT dataset.

Introducing OpenR1-Math-220k!
huggingface.co/datasets/ope...
The community has been busy distilling DeepSeek-R1 from inference providers, but we decided to have a go at doing it ourselves from scratch 💪
More details in 🧵

We are reproducing the full DeepSeek R1 data and training pipeline so everybody can use their recipe. Instead of doing it in secret we can do it together in the open!
Follow along: github.com/huggingface/...
Here's the links:
- Blog post: huggingface.co/spaces/Huggi...
- Code: github.com/huggingface/...
Enjoy!
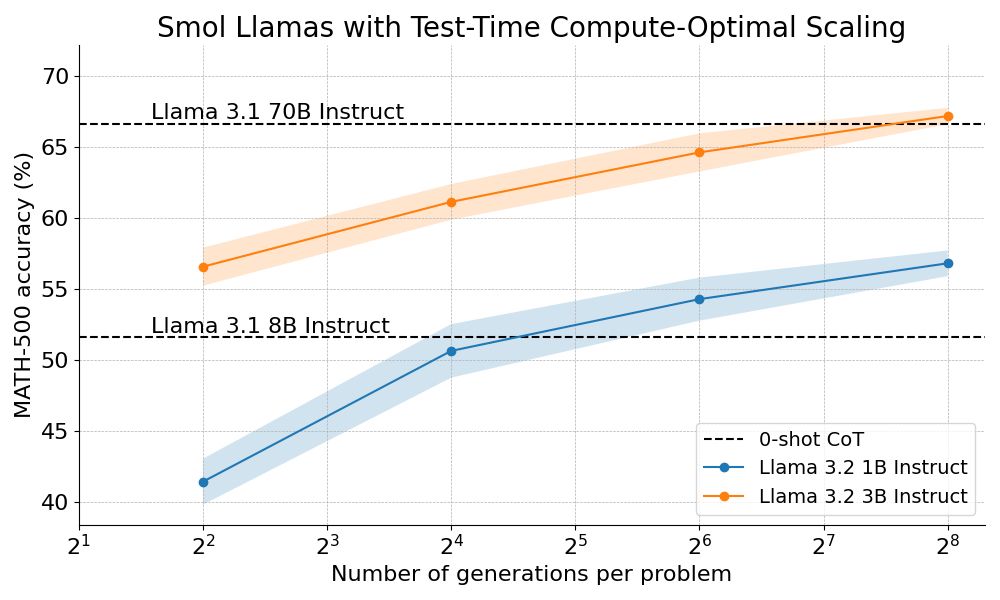
We outperform Llama 70B with Llama 3B on hard math by scaling test-time compute 🔥
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇

Hey ML peeps, we found a nice extension to beam search at Hugging Face that is far more scalable and produces more diverse candidates
The basic idea is to split your N beams into N/M subtrees and then run greedy node selection in parallel
Does anyone know what this algorithm is called?