CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
17.02.2025 18:22 — 👍 13 🔁 9 💬 1 📌 1
Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
07.01.2025 22:25 — 👍 233 🔁 77 💬 8 📌 2

🎉 Had fun at #NeurIPS2024 Workshop on #AdaptiveFoundationModels!
🚀 Speakers: @rsalakhu.bsky.social @sedielem.bsky.social Kate Saenko, Matthias Bethge / @vishaalurao.bsky.social Minjoon Seo, Bing Liu, Tianqi Chen
🌐Posters: adaptive-foundation-models.org/papers
🎬 neurips.cc/virtual/2024...
🧵Recap!
19.12.2024 04:59 — 👍 10 🔁 2 💬 1 📌 0

Our workshop in numbers:
🖇️ 128 Papers
💬 8 Orals
🖋️ 564 Authors
✅ 40 Reviewers
🔊 7 Invited Speakers
👕 100 T-Shirts
🔥 Organizers: Paul Vicol, Mengye Ren, Renjie Liao, Naila Murray, Wei-Chiu Ma, Beidi Chen
#NeurIPS2024 #AdaptiveFoundationModels
19.12.2024 04:59 — 👍 1 🔁 1 💬 1 📌 0

🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
10.12.2024 17:44 — 👍 18 🔁 5 💬 1 📌 2
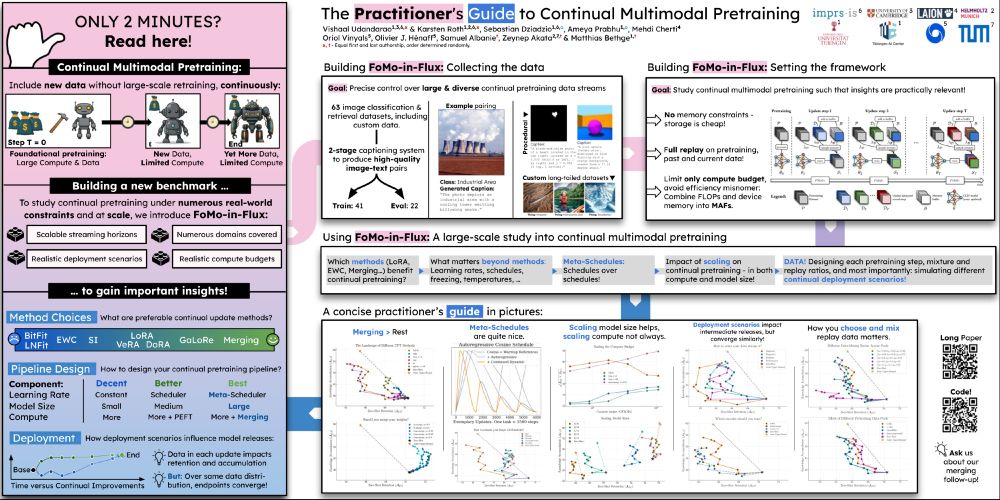
😵💫 Continually pretraining large multimodal models to keep them up-to-date all-the-time is tough, covering everything from adapters, merging, meta-scheduling to data design and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!
10.12.2024 16:42 — 👍 40 🔁 6 💬 1 📌 2
This was work done during my internship with amazing folks @google @deep-mind.bsky.social: @nikparth1.bsky.social (joint-first) Ferjad Talfan @samuelalbanie.bsky.social Federico Yongqin Alessio & @olivierhenaff.bsky.social
Super excited about this direction of strong pretraining for smol models!
02.12.2024 18:06 — 👍 0 🔁 0 💬 0 📌 0

Bonus: Along the way, we found current state of CLIP zero-shot benchmarking in disarray—some test datasets have a seed std of ~12%!
We construct a stable & reliable set of evaluations (StableEval) inspired by the inverse-variance-weighting method, to prune out unreliable evals!
02.12.2024 18:03 — 👍 0 🔁 0 💬 1 📌 0

Finally, we scale all our insights to pretrain SoTA FLOP-efficient models across three different FLOP-scales: ACED-F{0,1,2}
Outperforming strong baselines including Apple's MobileCLIP, TinyCLIP and @datologyai.com CLIP models!
02.12.2024 18:02 — 👍 0 🔁 0 💬 1 📌 0
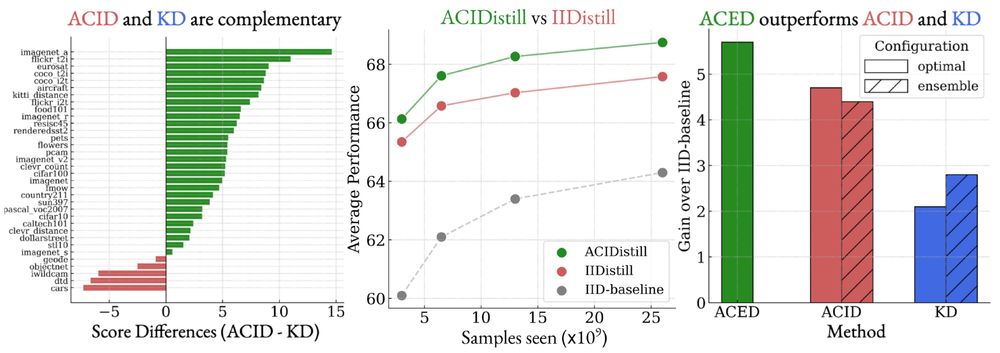
There's more! ACID and KD are complementary — they can be profitably combined, at scale! Our simple pretraining recipe ACED-ACIDistill showcases continued benefits as we scale to 26B samples seen!
02.12.2024 18:01 — 👍 0 🔁 0 💬 1 📌 0

We also show that ACID strongly outperforms KD across different reference/teacher training datasets, KD objectives, and student sizes.
02.12.2024 18:01 — 👍 0 🔁 0 💬 1 📌 0

Our ACID method shows very strong scaling properties as the size of the reference model increases, until we hit a saturation point — the optimal reference-student capacity ratio.
Further, ACID significantly outperforms KD as we scale up the reference/teacher sizes.
02.12.2024 18:01 — 👍 0 🔁 0 💬 1 📌 0

As our ACID method performs implicit distillation, we can further combine our data curation strategy with an explicit distillation objective, and conduct a series of experiments to determine the optimal combination strategy.
02.12.2024 18:00 — 👍 0 🔁 0 💬 1 📌 0

Our online curation method (ACID) uses large pretrained reference models (adopting from prior work: JEST) & we show a theoretical equivalence b/w KD and ACID (appx C in paper).
02.12.2024 18:00 — 👍 0 🔁 0 💬 1 📌 0

TLDR: We introduce an online data curation method that when coupled with simple softmax knowledge distillation produces a very effective pretraining recipe yielding SoTA inference-efficient two-tower contrastive VLMs!
02.12.2024 17:59 — 👍 1 🔁 0 💬 1 📌 0

🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
02.12.2024 17:58 — 👍 23 🔁 6 💬 1 📌 2

Technical Deep-Dive: Curating Our Way to a State-of-the-Art Text Dataset
Our data curation pipeline to obtain substantial improvements in LLM quality, training speed, and inference efficiency.
ICYMI, check out our latest results @datologyai.com on curating data for LLMs.
Intervening only on training data, our pipeline can train models faster (7.7x less compute), better (+8.5% performance), and smaller (models half the size outperform by >5%)!
www.datologyai.com/post/technic...
29.11.2024 16:36 — 👍 5 🔁 2 💬 0 📌 0
Great paper! Why do you think it doesn’t make sense for pretraining to be made aware of the model being used in a few-shot setting downstream? Do you see any potential downsides of this kind of approach?
29.11.2024 09:39 — 👍 3 🔁 0 💬 1 📌 0
@bayesiankitten.bsky.social @dziadzio.bsky.social and I also work on continual pretraining :)
28.11.2024 21:13 — 👍 2 🔁 0 💬 0 📌 0
Congrats, super exciting!!
22.11.2024 12:50 — 👍 0 🔁 0 💬 1 📌 0
1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
19.11.2024 16:30 — 👍 161 🔁 39 💬 6 📌 8

Tübingen AI
Join the conversation
Here's a fledgling starter pack for the AI community in Tübingen. Let me know if you'd like to be added!
go.bsky.app/NFbVzrA
19.11.2024 13:14 — 👍 24 🔁 13 💬 18 📌 0
Head of Research @ Simular. Professor @ UC Santa Cruz. Working on #Multimodal #Embodied #AIAgents. AI for Humanity in the long run. he/him
📍Bay Area 🔗 https://eric-xw.github.io
Prof (CS @Stanford), Co-Director @StanfordHAI, Cofounder/CEO @theworldlabs, CoFounder @ai4allorg #AI #computervision #robotics #AI-healthcare
Co-CEO, Yutori. Join the waitlist at yutori.com
Research scientist at Naver Labs Europe. https://mbsariyildiz.github.io/
Research Scientist at DeepMind. PhD from Sorbonne Université. Merging and aligning Gemmas.
https://alexrame.github.io/
Working on something new, combining active, multimodal, and memory-augmented learning.
Formerly Senior Staff Scientist @GoogleDeepMind, PhD @NYU, @Polytechnique
FAIR Researcher @metaai.bsky.social Previously Mila-Quebec, Microsoft Research, Adobe Research, IIT Roorkee
Research on AI and biodiversity 🌍
Asst Prof at MIT CSAIL,
AI for Conservation slack and CV4Ecology founder
#QueerInAI 🏳️🌈
PhD student @ UW & visiting researcher @ MetaAI.
Previously Google Brain resident & Stanford'19.
Curating better training data for language & multimodal models.
https://thaonguyen19.github.io/
Research Scientist GoogleDeepMind
Ex @UniofOxford, AIatMeta, GoogleAI
Professor at UW; Researcher at Meta. LMs, NLP, ML. PNW life.
I develop tough benchmarks for LMs and then I build agents to try and beat those benchmarks. Postdoc @ Princeton University.
https://ofir.io/about
Research Scientist @ Google DeepMind making multi-modal learning more efficient. Prev: PhD in bio-inspired visual representation learning from the Simoncelli lab @ NYU Center for Neural Systems. BS/MS @ Stanford
Researching reasoning at OpenAI | Co-created Libratus/Pluribus superhuman poker AIs, CICERO Diplomacy AI, and OpenAI o-series / 🍓
PhD student at Meta-FAIR and Université Gustave Eiffel with Yann LeCun and Laurent Najman.
Ex MVA and ESIEE Paris
garridoq.com
Ph.D. student @MPS_cog @MPICybernetics | I dream patterns 👾| Creativity | Complexity | Curiosity | CoCoSci 👩🏻💻
AI + security | Stanford PhD in AI & Cambridge physics | techno-optimism + alignment + progress + growth | 🇺🇸🇨🇿
Multimodal Multi-lingual research at Google DeepMind for Gemini post-training.
#NLProc #Multimodal