Available in PyTorch, MLX, on your iPhone, or in Rust for your server needs!
Project Page: kyutai.org/next/stt
OpenASR Leaderboard: huggingface.co/spaces/hf-au...
27.06.2025 10:31 — 👍 2 🔁 0 💬 0 📌 0
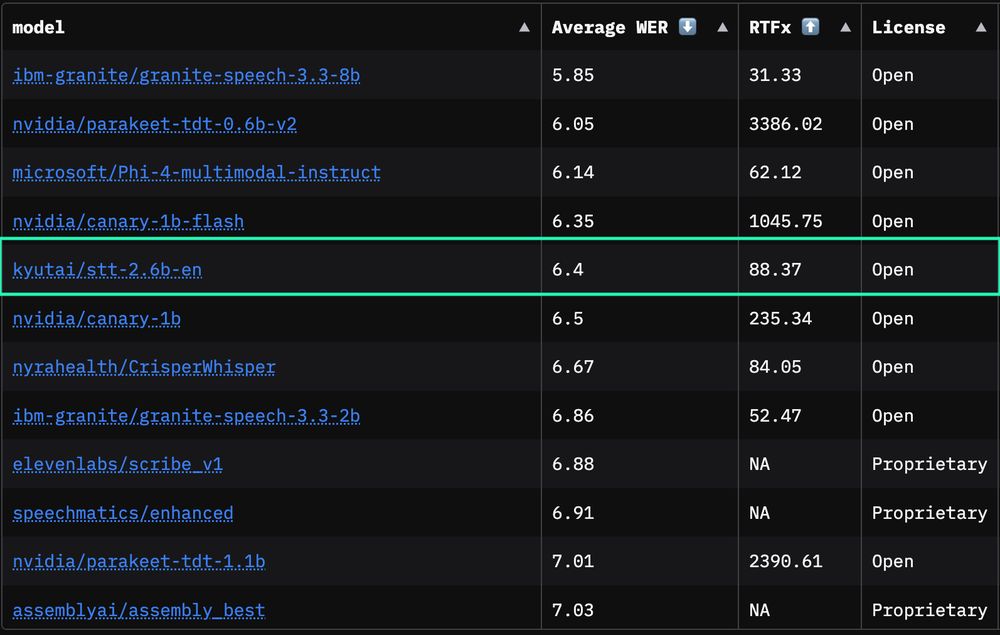
Our latest open-source speech-to-text model just claimed 1st place among streaming models and 5th place overall on the OpenASR leaderboard 🥇🎙️
While all other models need the whole audio, ours delivers top-tier accuracy on streaming content.
Open, fast, and ready for production!
27.06.2025 10:31 — 👍 4 🔁 3 💬 1 📌 0
What’s next? We strongly believe that the future of human-machine interaction lies in natural, full-duplex speech interactions, coupled with customization and extended abilities. Stay tuned for what’s to come!
23.05.2025 10:14 — 👍 2 🔁 0 💬 0 📌 0
The text LLM’s response is passed to our TTS, conditioned on a 10s voice sample. We’ll provide access to the voice cloning model in a controlled way. The TTS is also streaming *in text*, reducing the latency by starting to speak even before the full text response is generated.
23.05.2025 10:14 — 👍 2 🔁 0 💬 1 📌 0
Unmute’s speech-to-text is streaming, accurate, and includes a semantic VAD that predicts whether you’ve actually finished speaking or if you’re just pausing mid-sentence, meaning it’s low-latency but doesn’t interrupt you.
23.05.2025 10:14 — 👍 0 🔁 0 💬 1 📌 0
“But what about Moshi?” While Moshi provides unmatched latency and naturalness, it doesn’t yet match the abilities of text models such as function-calling, stronger reasoning, and in-context learning. Unmute allows us to directly bring all of these from text to real-time voice conversations.
23.05.2025 10:14 — 👍 0 🔁 0 💬 1 📌 0
Talk to unmute.sh 🔊, the most modular voice AI around. Empower any text LLM with voice, instantly, by wrapping it with our new speech-to-text and text-to-speech. Any personality, any voice. Interruptible, smart turn-taking. We’ll open-source everything within the next few weeks.
23.05.2025 10:14 — 👍 8 🔁 1 💬 2 📌 2
🧑💻 Read more about Helium 1 and dactory on our blog: kyutai.org/2025/04/30/h...
🤗 Get the models on HuggingFace: huggingface.co/kyutai/heliu...
📚 Try our pretraining data pipeline on GitHub: github.com/kyutai-labs/...
05.05.2025 10:39 — 👍 2 🔁 0 💬 0 📌 0

🚀 Thrilled to announce Helium 1, our new 2B-parameter LLM, now available alongside dactory, an open-source pipeline to reproduce its training dataset covering all 24 EU official languages. Helium sets new standards within its size class on European languages!
05.05.2025 10:39 — 👍 3 🔁 0 💬 1 📌 1

GitHub - kyutai-labs/moshi-finetune
Contribute to kyutai-labs/moshi-finetune development by creating an account on GitHub.
If you have audio data with speaker separated streams 🗣️🎙️🎤🤖 head over to github.com/kyutai-labs/moshi-finetune and train your own Moshi! We have already witnessed nice extensions of Moshi like J-Moshi 🇯🇵 hope this release will allow more people to create their very own voice AI!
01.04.2025 15:47 — 👍 2 🔁 0 💬 0 📌 0
Fine-tuning Moshi only takes a couple hours and can be done on a single GPU thanks to LoRA ⚡. The codebase contains an example colab notebook that demonstrates the simplicity and the efficiency of the procedure 🎮.
🔎 github.com/kyutai-labs/...
01.04.2025 15:47 — 👍 3 🔁 0 💬 1 📌 0
Have you enjoyed talking to 🟢Moshi and dreamt of making your own speech to speech chat experience🧑🔬🤖? It's now possible with the moshi-finetune codebase! Plug your own dataset and change the voice/tone/personality of Moshi 💚🔌💿. An example after finetuning w/ only 20 hours of the DailyTalk dataset. 🧵
01.04.2025 15:47 — 👍 6 🔁 1 💬 1 📌 2
If you want to work on cutting-edge research, join our non-profit AI lab in Paris 🇫🇷
Thanks to Iliad Group, CMA-CGM Group, Schmidt Sciences — and the open-source community.
21.03.2025 14:39 — 👍 2 🔁 0 💬 0 📌 0
🧰 Fully open-source
We’re releasing a preprint, model weights and a benchmark dataset for spoken visual question answering:
📄 Preprint arxiv.org/abs/2503.15633
🧠 Dataset huggingface.co/datasets/kyu...
🧾 Model weights huggingface.co/kyutai/moshi...
🧪 Inference code github.com/kyutai-labs/...
21.03.2025 14:39 — 👍 1 🔁 0 💬 1 📌 0
🧠 How it works
MoshiVis builds on Moshi, our speech-to-speech LLM — now enhanced with vision.
206M lightweight parameters on top of a frozen Moshi give it the power to discuss images while still remaining real-time on consumer-grade hardware.
21.03.2025 14:39 — 👍 1 🔁 0 💬 1 📌 0
Try it out 👉 vis.moshi.chat
Blog post 👉 kyutai.org/moshivis
21.03.2025 14:39 — 👍 1 🔁 0 💬 1 📌 0
Meet MoshiVis🎙️🖼️, the first open-source real-time speech model that can talk about images!
It sees, understands, and talks about images — naturally, and out loud.
This opens up new applications, from audio description for the visual impaired to visual access to information.
21.03.2025 14:39 — 👍 6 🔁 2 💬 1 📌 2
Even Kavinsky 🎧🪩 can't break Hibiki! Just like Moshi, Hibiki is robust to extreme background conditions 💥🔊.
11.02.2025 16:11 — 👍 8 🔁 4 💬 0 📌 1
Hibiki’s smaller alternative, Hibiki-M, runs on-device in real time. Hibiki-M was obtained by distilling the full model into a smaller version with only 1.7B parameters. On an iPhone 16 Pro, Hibiki-M runs in real-time for more than a minute as shown by Tom.
07.02.2025 08:22 — 👍 2 🔁 1 💬 1 📌 0

To train Hibiki, we generated bilingual data of simultaneous interpretation where a word only appears in the target when it's predictable from the source. We developed a new method based on an off-the-shelf text translation system and using a TTS system with constraints on word locations.
07.02.2025 08:22 — 👍 1 🔁 0 💬 1 📌 0
Based on objective and human evaluations, Hibiki outperforms previous systems for quality, naturalness and speaker similarity and approaches human interpreters.
Here is an example of a live conference interpretation.
07.02.2025 08:22 — 👍 1 🔁 0 💬 1 📌 0
Meet Hibiki, our simultaneous speech-to-speech translation model, currently supporting 🇫🇷➡️🇬🇧.
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech. 🧵
07.02.2025 08:22 — 👍 11 🔁 2 💬 1 📌 2
Helium 2B running locally on an iPhone 16 Pro at ~28 tok/s, faster than you can read your loga lessons in French 🚀 All that thanks to mlx-swift with q4 quantization!
14.01.2025 16:38 — 👍 1 🔁 1 💬 0 📌 1
We are looking forward to the feedback from the community, which will help us drive the development of Helium and make it the best multi-lingual lightweight model. Thanks @hf.co for helping us on this release!
13.01.2025 17:51 — 👍 2 🔁 0 💬 0 📌 0
We will also release the full model, a technical report, and we will open-source the code for training the model and for reproducing our dataset.
13.01.2025 17:51 — 👍 4 🔁 0 💬 1 📌 0

Helium currently supports 6 languages (English, French, German, Italian, Portuguese and Spanish) and will be extended to more languages shortly. Here is a summary of Helium's performance on multilingual benchmarks.
13.01.2025 17:50 — 👍 2 🔁 0 💬 1 📌 0

kyutai/helium-1-preview-2b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Meet Helium-1 preview, our 2B multi-lingual LLM, targeting edge and mobile devices, released under a CC-BY license. Start building with it today!
huggingface.co/kyutai/heliu...
13.01.2025 17:50 — 👍 16 🔁 5 💬 1 📌 5


















