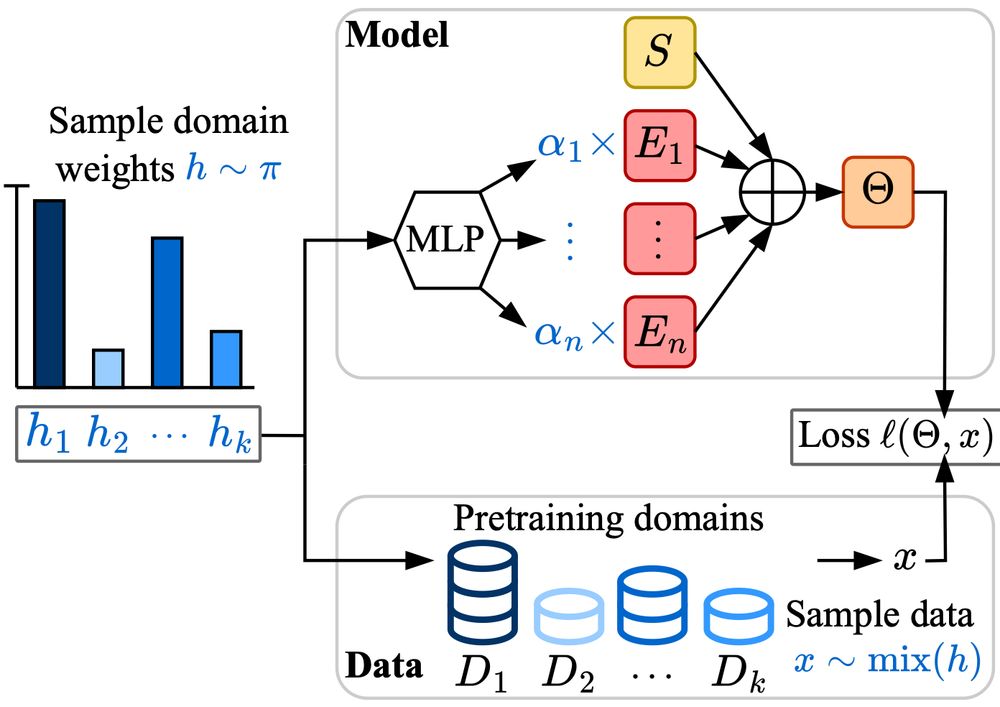
Excited to share Soup-of-Experts, a new neural network architecture that, for any given specific task, can instantiate in a flash a small model that is very good on it.
Made with ❤️ at Apple
Thanks to my co-authors David Grangier, Angelos Katharopoulos, and Skyler Seto!
arxiv.org/abs/2502.01804
05.02.2025 09:32 —
👍 12
🔁 4
💬 0
📌 0

Distillation Scaling Laws
We provide a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher. Our findings reduce the risks associated ...
Reading "Distilling Knowledge in a Neural Network" left me fascinated and wondering:
"If I want a small, capable model, should I distill from a more powerful model, or train from scratch?"
Our distillation scaling law shows, well, it's complicated... 🧵
arxiv.org/abs/2502.08606
13.02.2025 21:50 —
👍 3
🔁 3
💬 1
📌 2
Paper🧵 (cross-posted at X): When does composition of diffusion models "work"? Intuitively, the reason dog+hat works and dog+horse doesn’t has something to do with independence between the concepts being composed. The tricky part is to formalize exactly what this means. 1/
11.02.2025 05:59 —
👍 39
🔁 15
💬 2
📌 2
Big thanks to our amazing collaborators: @aggieinca.bsky.social , @harshay-shah.bsky.social , Dan Busbridge, @alaaelnouby.bsky.social , Josh Susskind.
28.01.2025 06:25 —
👍 1
🔁 0
💬 0
📌 0
However, CoT isn’t parallelizable. Next, It would be exciting to dive into the trade-offs between parallel and sequential compute to understand how we can best combine their strengths!
28.01.2025 06:25 —
👍 0
🔁 0
💬 1
📌 0

For presumably reasoning-heavy downstream tasks, sparsity negatively affects transfer. Inference compute plays a crucial role here. Good news: mechanisms like Chain-of-Thought (CoT) can adaptively increase inference compute.
28.01.2025 06:25 —
👍 0
🔁 0
💬 1
📌 0

For many downstream tasks, sparsity doesn't affect the relationship between upstream and downstream performance in a few-shot in-context learning.
28.01.2025 06:25 —
👍 0
🔁 0
💬 1
📌 0


In practical settings, where total parameters are bounded, the optimal sparsity level depends on model size and training budget, eventually approaching 1.0 as model size grows.
28.01.2025 06:25 —
👍 0
🔁 0
💬 1
📌 0

With a fixed training budget, compute-optimal models with higher sparsity not only have more total parameters but also fewer active parameters (i.e., fewer FLOPs per token).
28.01.2025 06:25 —
👍 0
🔁 0
💬 1
📌 0

We find that during pretraining, if memory and communication costs are ignored, higher sparsity is always better and Increasing model capacity via total parameters is the optimal strategy.
28.01.2025 06:25 —
👍 0
🔁 0
💬 1
📌 0

In MoE models, sparsity can be adjusted by varying total parameters and FLOPs per token (via active parameters). Scaling laws for optimal sparsity levels reveal key insights into the trade-off between parameters vs. compute per token in sparse models at different scales.
28.01.2025 06:25 —
👍 0
🔁 0
💬 1
📌 0

🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, parallelizable compute, or sequential compute?
We explored this through the lens of MoEs:
28.01.2025 06:25 —
👍 18
🔁 8
💬 1
📌 3

