Plus pip is just way too SLOWWW!
14.12.2024 19:05 — 👍 1 🔁 0 💬 0 📌 0
Even though UV is aiming to replace Poetry, they can still play together, "you can use uv with poetry now," good for those not ready to switch entirely.
It shows a willingness to integrate and improve the overall developer experience, not just replace tools.
14.12.2024 17:03 — 👍 1 🔁 0 💬 0 📌 0
Slow pip installs mess with CI/CD, but UV makes that process much quicker.
That's a win for devops who are constantly optimizing for speed and resource usage, and that has a big impact on the overall business.
14.12.2024 17:03 — 👍 1 🔁 0 💬 1 📌 0
UV wants to end that "This is so SLOWWWW!!!" feeling of managing Python dependencies, creating a more confident and less error prone experience for all.
We need our tools to be reliable, and that’s what UV aims to do, so we can build with confidence.
14.12.2024 17:03 — 👍 1 🔁 0 💬 1 📌 0

Built in Rust, UV delivers the kind of performance and reliability we all want, an efficient tool made with performance in mind.
It's not just some script, it's a serious approach to speed; that blazingly fast reputation is well deserved.
14.12.2024 17:03 — 👍 1 🔁 0 💬 1 📌 0
Tired of the nightmare of Python global libraries? UV is addressing that head-on, which is pretty cool.
It's about cutting through all that chaos that we all know too well. A unified tool can only make things much better.
14.12.2024 17:03 — 👍 1 🔁 0 💬 1 📌 0

It aims to be the only tool you need to manage Python projects by bundling pip, venv, pipx, and even ruff.
That's less context switching, which results in a much smoother development experience, it's about working smarter, not harder.
14.12.2024 17:03 — 👍 1 🔁 0 💬 1 📌 0
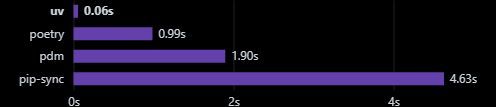
UV is built as a seamless swap for pip, pip-tools, and virtualenv, it’s a minimal disruption upgrade for your setup, which is always a plus.
This drop-in replacement does not force you to change everything, it's just a lot smoother, you know?
14.12.2024 17:03 — 👍 1 🔁 0 💬 1 📌 0
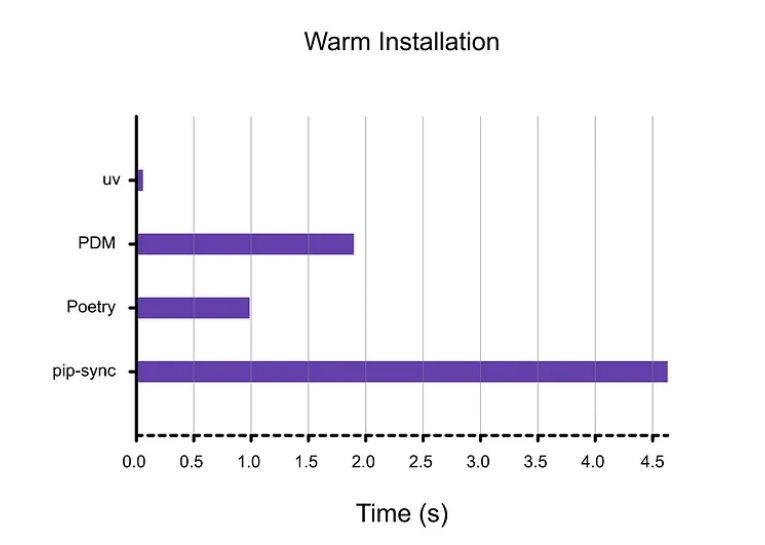
It's about getting back precious time and cutting through the frustration that slows down your workflow.
It's the little things that make a big difference to your productivity.
We all know how long it takes to get started with some projects, right?
14.12.2024 17:03 — 👍 1 🔁 0 💬 1 📌 0
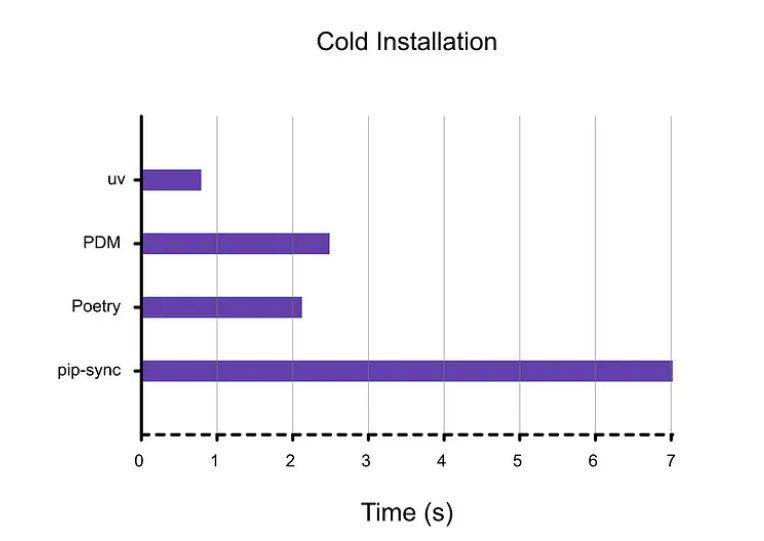
Setting up Python projects can often feel like a waiting game, not a coding session, don't you think?
The speed of UV is so fast it might make you wonder if the install actually completed, it really is that quick.
14.12.2024 17:03 — 👍 1 🔁 0 💬 1 📌 0

Every minute spent waiting is a minute not creating.
But what if there was a way to instantly speed up your workflow?
14.12.2024 17:03 — 👍 3 🔁 0 💬 2 📌 0
Feels like its harder to get any engagement here
14.12.2024 12:38 — 👍 2 🔁 0 💬 1 📌 0
Thank you!
13.12.2024 03:55 — 👍 1 🔁 0 💬 0 📌 0
Yeah but the think is that we constantly keep getting new models, honestly its kind of hard to keep up sometimes
12.12.2024 19:04 — 👍 1 🔁 0 💬 0 📌 0
Yeah it does provides developers more lower level control compared to other AI frameworks
12.12.2024 18:07 — 👍 1 🔁 0 💬 0 📌 0

You can test it for free on Google AI Studio and via the Gemini API. They're giving Free 10 RPM 1500 req/day. I’m thinking about what new projects I could build. What about you?
12.12.2024 12:00 — 👍 5 🔁 4 💬 0 📌 0
It’s available in Google AI Studio and Vertex AI right now and is slated to roll out to platforms like Android Studio, Chrome DevTools, and Firebase soon. Gemini 2.0 Flash will also be included in Gemini Code Assist for IDEs like VS Code, IntelliJ, PyCharm, and others.
12.12.2024 12:00 — 👍 6 🔁 4 💬 1 📌 0
What’s more, there’s the Multimodal Live API for real-time apps using audio and video streams. Imagine building, I don’t know, some sort of interactive AI video app, this is what you’d use.
12.12.2024 12:00 — 👍 5 🔁 4 💬 1 📌 0

And the best part? Native tool use. Gemini 2.0 Flash can now call tools like Google Search and execute code, along with custom third-party functions, directly. Imagine what we can do! cutting research times down considerably
12.12.2024 12:00 — 👍 6 🔁 4 💬 1 📌 0

Let's look at what this means for us developers. Expect better performance across the board: text, code, video, spatial understanding; plus, it's multimodal now, meaning it can output text, audio, and images all from a single API call.
12.12.2024 12:00 — 👍 5 🔁 4 💬 1 📌 0

Gemini 2.0 Flash is here, and it's a significant leap forward.
It like Gemini 1.5 Pro got a huge upgrade , adding a range of new features. The fact that it's twice as fast is very impressive, don't you think?
12.12.2024 12:00 — 👍 9 🔁 4 💬 2 📌 0
My branches now all merged and clean,
A seamless push, a tranquil scene,
With commits logged, a history told,
My work now in the cloud, so bold.
11.12.2024 22:23 — 👍 3 🔁 0 💬 0 📌 0
At least you are getting followers somewhere dude, i dont even get any interactions
11.12.2024 18:27 — 👍 0 🔁 0 💬 1 📌 0
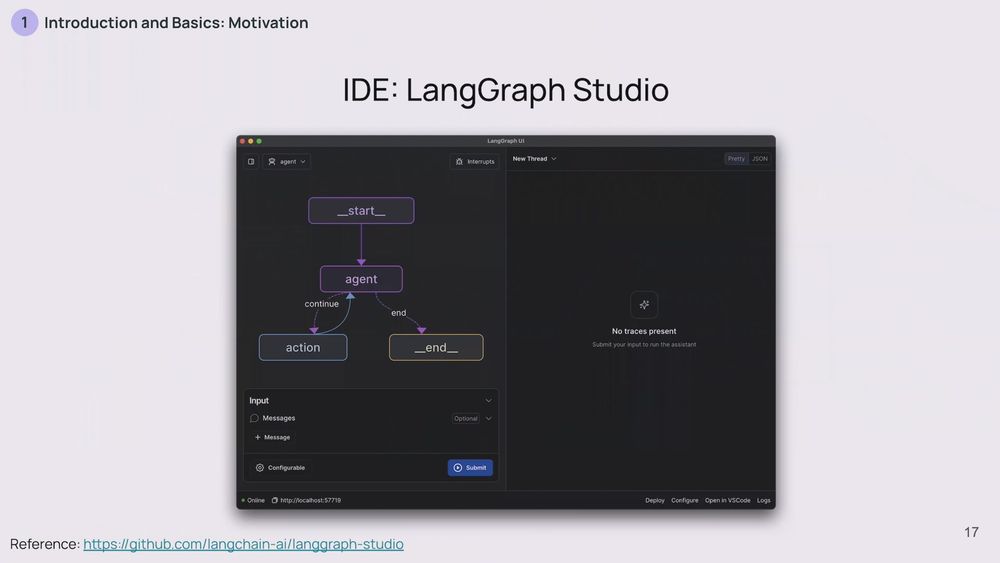
Oh, and there's a visual IDE too! It's super handy for debugging and visualizing your agents. Plus, LangGraph plays nicely with LangChain. It's got integrations with tons of different LLMs, vector stores, and other tools.
11.12.2024 17:03 — 👍 5 🔁 3 💬 0 📌 0
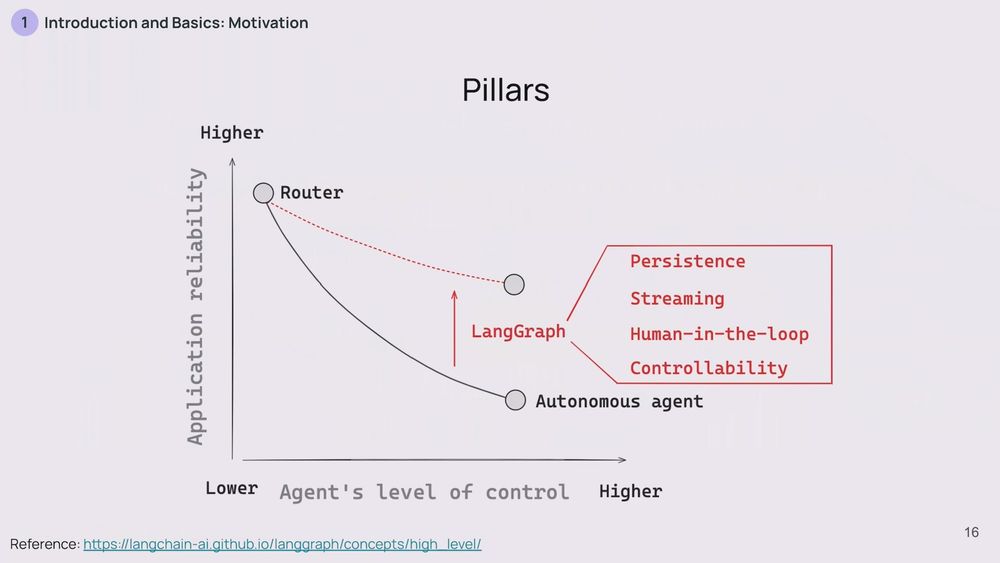
LangGraph has features that make all this possible: persistence, streaming, human-in-the-loop capabilities, and advanced controllability. Persistence helps with memory, streaming keeps things flowing, human-in-the-loop lets you, well, bring humans into the process.
11.12.2024 17:03 — 👍 4 🔁 3 💬 1 📌 0
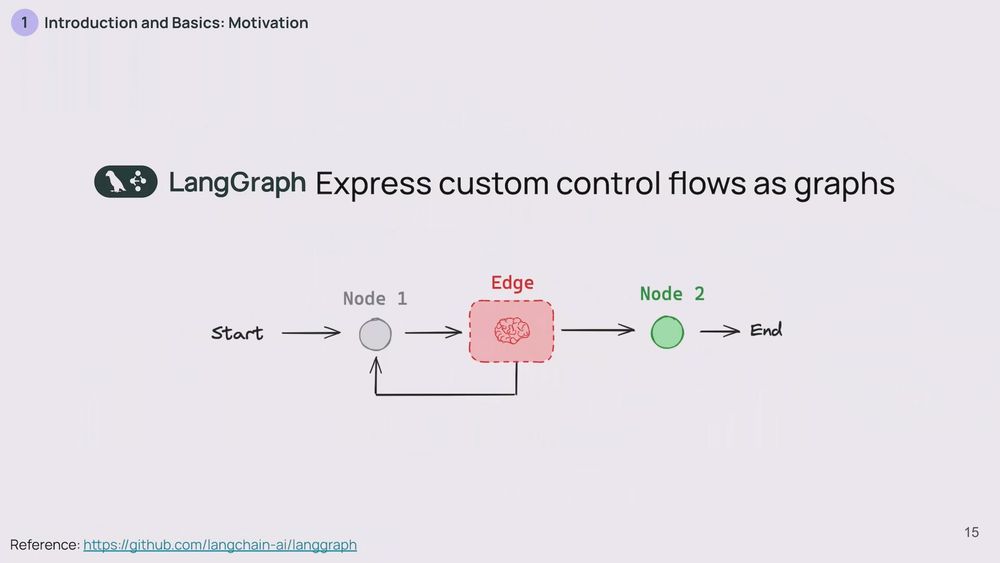
LangGraph represents these workflows as graphs. In these graphs, nodes are the steps in your application – a tool call, a retrieval step, anything like that. Edges are simply the connections between these nodes. You've got flexibility in how you set up these nodes and edges.
11.12.2024 17:03 — 👍 5 🔁 4 💬 1 📌 0
You can set up specific parts of your application's workflow that always stay the same. You might say, "Always start here, then do step 1, and always end with step 2." But then, you can also let the LLM take over at certain points, giving it control over how the application flows
11.12.2024 17:03 — 👍 5 🔁 4 💬 1 📌 0
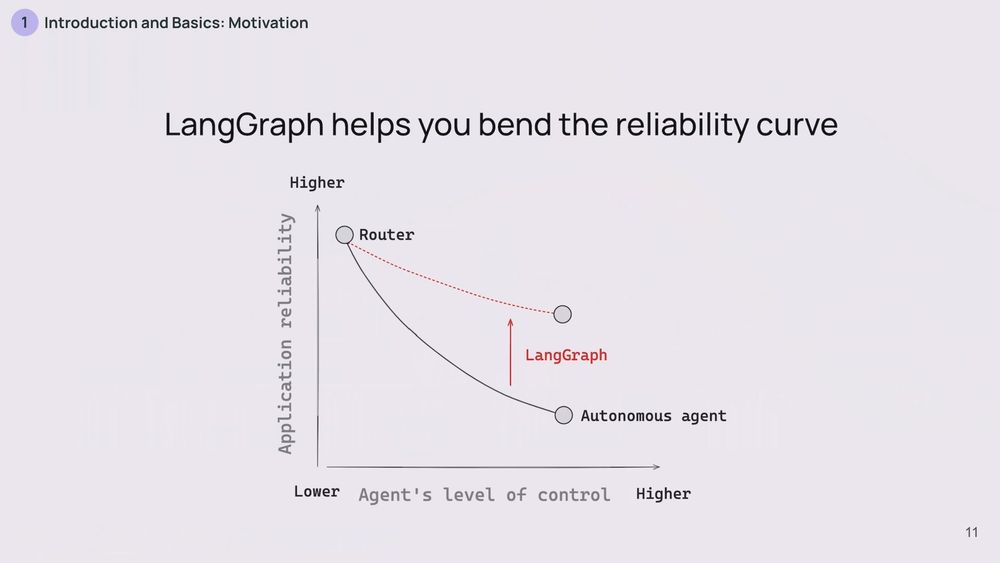
This is where LangGraph steps in. The big idea behind LangGraph is to let you build agents that are both flexible and reliable. It's about getting the best of both worlds. How? By letting you mix and match developer control with LLM control.
11.12.2024 17:03 — 👍 5 🔁 4 💬 1 📌 0
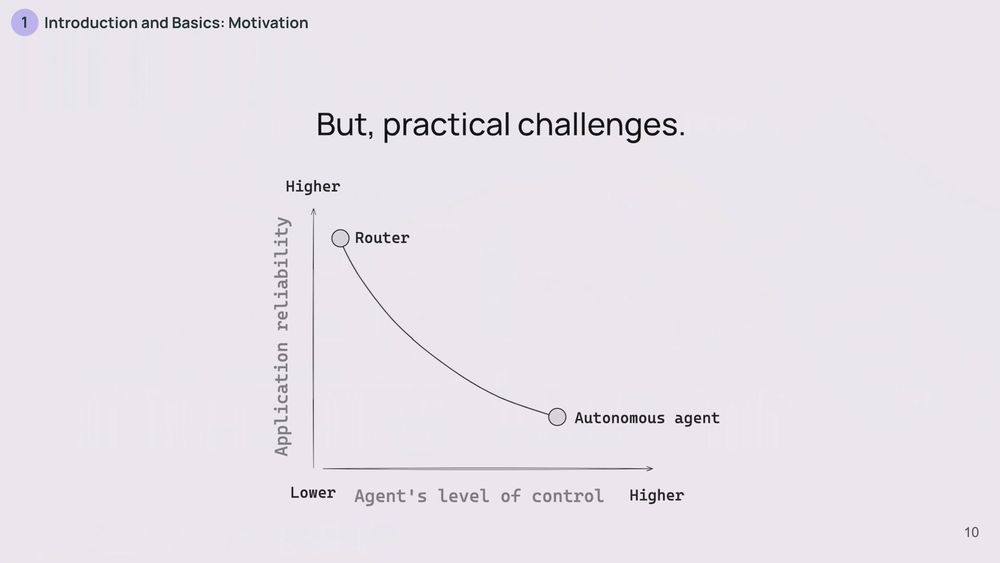
But, you know what? There's a catch. The more control you give an LLM, the less reliable it tends to be. It's like the difference between a well-tested function and a brand-new, experimental one. You're trading reliability for flexibility.
11.12.2024 17:03 — 👍 5 🔁 4 💬 1 📌 0
On the other end, you've got fully autonomous agents. These bad boys can pick any sequence of steps from a given set, or even create their own steps. It's like giving the LLM the keys to the car and a map and saying, "Go wherever you need to."
11.12.2024 17:03 — 👍 5 🔁 4 💬 1 📌 0




















