Diligent people can now run that rigorous process 100x faster. They don't use AI to skip the thinking. They use it to scale their standards.
The gap between people who care to look stuff up and people who don't isn't shrinking. It's about to become unbridgeable!
#AI #FutureOfWork
31.01.2026 16:18 —
👍 0
🔁 0
💬 0
📌 0
But for diligent people AI is a game changer! Think about the person who already cared about checking edge cases, looking up standard protocols and validating assumptions. Previously, that rigor was expensive. It took hours. It was the bottleneck. Now that friction is gone!
31.01.2026 16:18 —
👍 0
🔁 0
💬 1
📌 0
So while many people assume AI is a tool for the lazy, if you were lazy before AI (operating on "vibes," skipping research, trusting your gut over data), AI is a trap. You will just generate "synthetic vibes" faster. You won't spot the hallucinations. You will produce high-volume mediocrity.
31.01.2026 16:18 —
👍 0
🔁 0
💬 1
📌 0
The hard truth is: Most "knowledge work" (even at high levels) isn't actually novel reasoning. It is retrieval + synthesis of known strategies to a very high standard.
31.01.2026 16:18 —
👍 0
🔁 0
💬 1
📌 0
AI isn't coming for your creativity. It's coming for your lack of diligence.
People talk a lot about #AGI and "super-intelligence," but the immediate disruption is much simpler: AI is killing "vibe-based" decision-making.
31.01.2026 16:18 —
👍 0
🔁 0
💬 1
📌 0
Thanks a lot! Means a lot from you!
23.01.2026 13:05 —
👍 1
🔁 0
💬 0
📌 0

The Shape of Thought: Space Folding in Neural Networks
The mathematical description of deep learning has long been dominated by the language of algebra: matrices, gradients, and optimization landscapes. A parallel and perhaps more intuitive language howev
Over the past year Michał Lewandowski and I published a series of papers on Space Folding , and while Michał went to #AAAI to present the latest one, I worked on a blog-post explaining some the central ideas behind the papers.
Let me know what you think!
www.pisoni.ai/posts/space-...
23.01.2026 10:05 —
👍 5
🔁 0
💬 0
📌 0
After a long hiatus I decided to update my blog and write about some of the things I did over the last few years. Come have a look! pisoni.ai
23.01.2026 07:00 —
👍 3
🔁 0
💬 1
📌 0
Currently heading to #EurIPS in Copenhagen to present our work on space folding and model interpretability. If you're attending and would like to discuss Representation Learning, SSL, Multimodal LLMs, CV, or other topics that YOU are excited about, feel free to reach out.
01.12.2025 08:54 —
👍 4
🔁 0
💬 0
📌 0
The US government should subsidize Open AI rather than OpenAI
07.11.2025 06:43 —
👍 49
🔁 7
💬 0
📌 1

On the occasion of the 1000th citation of our Sinkhorn-Knopp self-supervised representation learning paper, I've written a whole post about the history and the key bits of this method that powers the state-of-the-art SSL vision models.
Read it here :): docs.google.com/document/d/1...
15.10.2025 10:00 —
👍 18
🔁 4
💬 1
📌 0
We're ready!
21.09.2025 06:39 —
👍 0
🔁 0
💬 0
📌 0
The single most undervalued property of neural networks is self-consistency. We should change that!
06.09.2025 12:58 —
👍 2
🔁 0
💬 0
📌 0
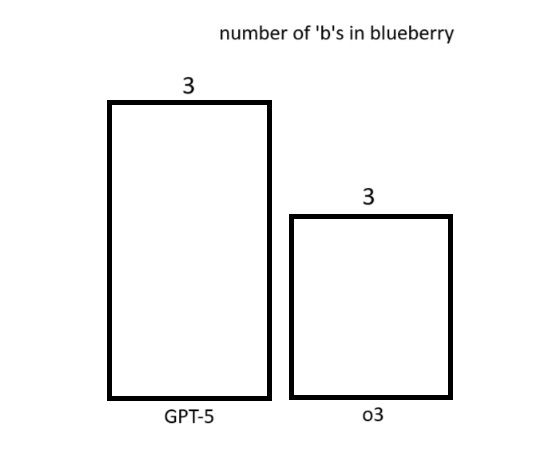 08.08.2025 03:56 —
👍 160
🔁 22
💬 2
📌 3
08.08.2025 03:56 —
👍 160
🔁 22
💬 2
📌 3
You've been researching for a while!
Time to have some SOTA!
#aislop
26.07.2025 12:51 —
👍 3
🔁 0
💬 0
📌 0
I wanna talk to those experts you claim to have trained! Are they in the room with us now?
26.07.2025 10:48 —
👍 1
🔁 0
💬 0
📌 0
You and Adam keep beating Sota? Stop doing that! Poor Sota!
26.07.2025 09:50 —
👍 9
🔁 0
💬 1
📌 0
Have some cool idea but only evaluate it on small models? Tough luck buddy. You only get your paper accepted if your experimental results are 0.2% above SOTA and too expensive to falsify!
Is academic publishing pay to win yet?
26.07.2025 09:45 —
👍 3
🔁 0
💬 0
📌 0

GitHub - 4rtemi5/modded-nanogpt
Contribute to 4rtemi5/modded-nanogpt development by creating an account on GitHub.
I ran my experiments on this "Gaussian-Kernel Attention" on the GPT speedrun repo by Keller Jordan on 8xH100. How much that's worth to compare against BIG models I don't know but I found it interesting so here is the code:
github.com/4rtemi5/modd...
23.07.2025 20:14 —
👍 0
🔁 0
💬 0
📌 0

Is there a reason why none of the recent models use RBF-kernel Attention to get rid of the softmax-bottleneck for long context?
I tried replacing dot-product attention with the negative squared KQ-distance and was able to remove the softmax without issues and loss in performance!
23.07.2025 20:14 —
👍 3
🔁 1
💬 1
📌 0

eurips.cc
A NeurIPS-endorsed conference in Europe held in Copenhagen, Denmark
NeurIPS is endorsing EurIPS, an independently-organized meeting which will offer researchers an opportunity to additionally present NeurIPS work in Europe concurrently with NeurIPS.
Read more in our blog post and on the EurIPS website:
blog.neurips.cc/2025/07/16/n...
eurips.cc
16.07.2025 22:05 —
👍 124
🔁 38
💬 2
📌 3
This could be a way to nudge a neuron with a negative activation to still get a small positive gradient, potentially avoiding dead ReLUs in a more direct way.
Would this offer more granular control over learning dynamics compared to variants like Leaky ReLU?
08.07.2025 05:59 —
👍 0
🔁 0
💬 1
📌 0
Has anyone experimented with "conditional gradients"?
Thinking about a setup where, within a specific activation range (e.g., right before a ReLU), you'd only permit positive or negative gradients.
08.07.2025 05:59 —
👍 1
🔁 0
💬 1
📌 0
With non-car stuff you mean IT-startups right?
03.07.2025 18:12 —
👍 1
🔁 0
💬 0
📌 0
Quick question to the SSL experts out there: Usually you evaluate an ssl-model by freezing it and training a linear probing layer. Would it be fair to somehow learn a final layer with more dimensions than classes and do a nearest-neighbor evaluation?
29.06.2025 11:17 —
👍 0
🔁 0
💬 0
📌 0
There is an oak forest in central France that was planted 400 years ago by Colbert so that France would have quality hard wood by the 2000s to build ships for its navy.
This is the type of long term planning that Seldonian predictions can help improving.
17.06.2025 08:17 —
👍 7
🔁 2
💬 1
📌 0

New anti-censorship jailbreak just dropped ;)
13.05.2025 02:17 —
👍 32
🔁 7
💬 1
📌 2



