Happy to share that our paper “Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization” (aka MiCRo) has been accepted to #ICLR2026!! 🎉
See you in Rio 🇧🇷 🏝️
27.01.2026 15:25 — 👍 6 🔁 2 💬 0 📌 0
Bridge AI and linguistics with the Computational and Theoretical Modelling of Language and Cognition (CLC) track at @cimecunitrento.bsky.social!
Apply to our MSc in Cognitive Science
First-call deadline for non-EU applicants: March 4, 2026.
ℹ️ corsi.unitn.it/en/cognitive-science
#cimec_unitrento #AI
27.01.2026 18:16 — 👍 3 🔁 2 💬 0 📌 0
In collaboration with @tomlamarra.bsky.social Andrea Amelio Ravelli @chiarasaponaro.bsky.social @beatricegiustolisi.bsky.social @mariannabolog.bsky.social
10.12.2025 19:28 — 👍 2 🔁 0 💬 0 📌 0
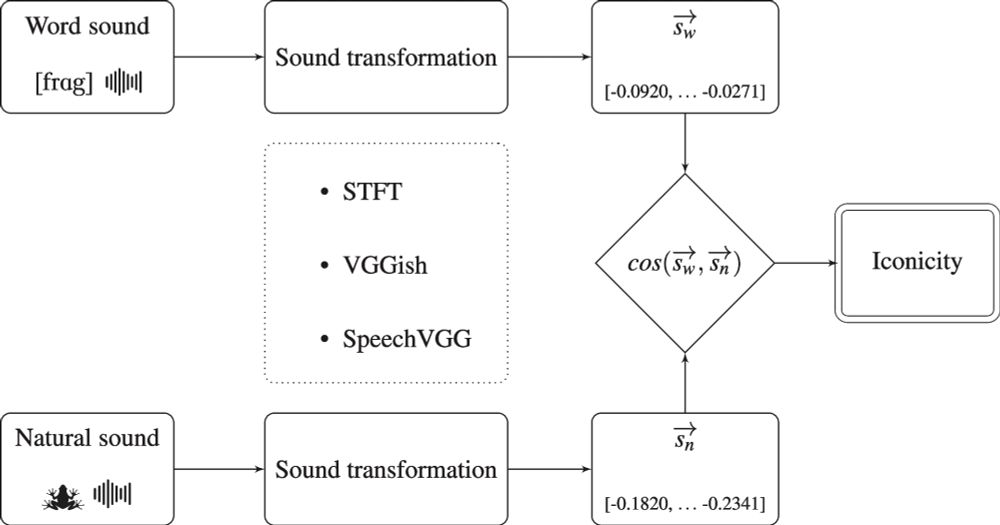
Some words sound like what they mean. In IconicITA we show that the (psycho)linguistic factors that modulate which words are most iconic are similar between English and Italian. Lots more details in the paper!
10.12.2025 19:25 — 👍 5 🔁 1 💬 1 📌 0
Great work led by Daria & Greta showing that diverse agreement types draw on shared units (even across languages)!
10.12.2025 14:43 — 👍 9 🔁 3 💬 0 📌 0

What does it mean to understand language?
Language understanding entails not just extracting the surface-level meaning of the linguistic input, but constructing rich mental models of the situation it describes. Here we propose that because pr...
What does it mean to understand language? We argue that the brain’s core language system is limited, and that *deeply* understanding language requires EXPORTING info to other brain regions.
w/ @neuranna.bsky.social @evfedorenko.bsky.social @nancykanwisher.bsky.social
arxiv.org/abs/2511.19757
1/n🧵👇
26.11.2025 16:26 — 👍 82 🔁 33 💬 2 📌 5
I'd love to watch this, is there a recording?
21.11.2025 16:11 — 👍 0 🔁 0 💬 1 📌 0
Computational psycho/neurolinguistics is lots of fun, but most studies only focus on English. If you think cross-linguistic evidence matters for understanding the language system, consider submitting an abstract to MMMM 2026!
21.11.2025 01:17 — 👍 2 🔁 0 💬 0 📌 0
Why does this alignment emerge? There are similarities in how reasoning models and humans learn: first by observing worked examples (pretraining), then by practicing with feedback (RL). In the end, just like humans, they allocate more effort to harder problems. (6/6)
19.11.2025 20:14 — 👍 3 🔁 0 💬 0 📌 0

Token count also captures differences across tasks. Avg. token count predicts avg. RT across domains (r = 0.97, left), and even item-level RTs across all tasks (r = 0.92 (!!), right). (5/6)
19.11.2025 20:14 — 👍 0 🔁 0 💬 1 📌 0

We found that the number of reasoning tokens generated by the model reliably correlates with human RTs within each task (mean r = 0.57, all ps < .001). (4/6)
19.11.2025 20:14 — 👍 1 🔁 0 💬 1 📌 0

Large reasoning models can solve many reasoning problems, but do their computations reflect how humans think?
We compared human RTs to DeepSeek-R1’s CoT length across seven tasks: arithmetic (numeric & verbal), logic (syllogisms & ALE), relational reasoning, intuitive reasoning, and ARC (3/6)
19.11.2025 20:14 — 👍 0 🔁 0 💬 1 📌 0
Neural networks are powerful in-silico models for studying cognition: LLMs and CNNs already capture key behaviors in language and vision. But can they also capture the cognitive demands of human reasoning? (2/6)
19.11.2025 20:14 — 👍 1 🔁 0 💬 1 📌 0
PNAS
Proceedings of the National Academy of Sciences (PNAS), a peer reviewed journal of the National Academy of Sciences (NAS) - an authoritative source of high-impact, original research that broadly spans...
Our paper “The cost of thinking is similar between large reasoning models and humans” is now out in PNAS! 🤖🧠
w/ @fepdelia.bsky.social, @hopekean.bsky.social, @lampinen.bsky.social, and @evfedorenko.bsky.social
Link: www.pnas.org/doi/10.1073/... (1/6)
19.11.2025 20:14 — 👍 35 🔁 10 💬 1 📌 1

Top: A syntax tree for the sentence "the doctor by the lawyer saw the artist".
Bottom: A continuous vector.
🤖🧠I'll be considering applications for PhD students & postdocs to start at Yale in Fall 2026!
If you are interested in the intersection of linguistics, cognitive science, & AI, I encourage you to apply!
PhD link: rtmccoy.com/prospective_...
Postdoc link: rtmccoy.com/prospective_...
14.11.2025 16:40 — 👍 36 🔁 13 💬 2 📌 2

Can't wait for #CCN2025! Drop by to say hi to me / collaborators!
10.08.2025 16:52 — 👍 27 🔁 1 💬 0 📌 0
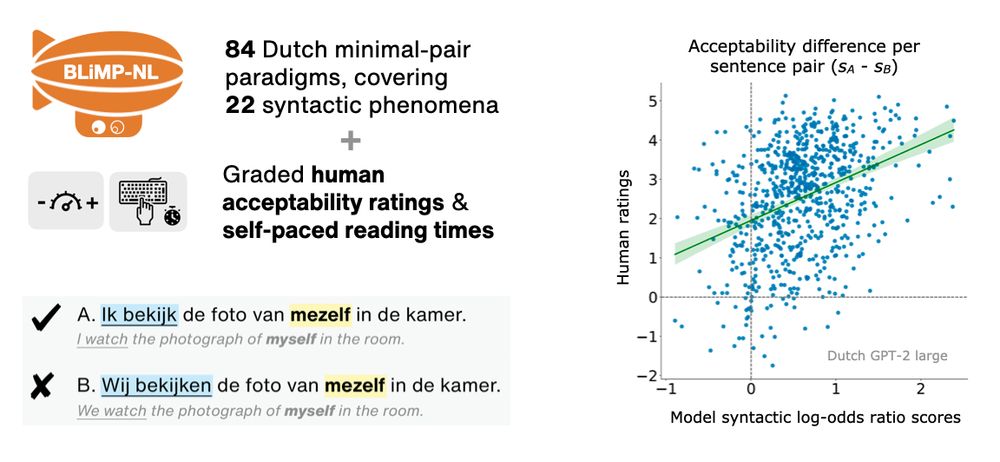
The BLiMP-NL dataset consists of 84 Dutch minimal pair paradigms covering 22 syntactic phenomena, and comes with graded human acceptability ratings & self-paced reading times.
An example minimal pair:
A. Ik bekijk de foto van mezelf in de kamer (I watch the photograph of myself in the room; grammatical)
B. Wij bekijken de foto van mezelf in de kamer (We watch the photograph of myself in the room; ungrammatical)
Differences in human acceptability ratings between sentences correlate with differences in model syntactic log-odds ratio scores.
Next week I’ll be in Vienna for my first *ACL conference! 🇦🇹✨
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
24.07.2025 15:30 — 👍 28 🔁 4 💬 2 📌 2
I'm sharing a Colab notebook on using large language models for cognitive science! GitHub repo: github.com/MarcoCiappar...
It's geared toward psychologists & linguists and covers extracting embeddings, predictability measures, comparing models across languages & modalities (vision). see examples 🧵
18.07.2025 13:39 — 👍 11 🔁 4 💬 1 📌 0
Many LM applications may be formulated as text generation conditional on some (Boolean) constraint.
Generate a…
- Python program that passes a test suite.
- PDDL plan that satisfies a goal.
- CoT trajectory that yields a positive reward.
The list goes on…
How can we efficiently satisfy these? 🧵👇
13.05.2025 14:22 — 👍 12 🔁 6 💬 2 📌 0

The cerebellar components of the human language network
The cerebellum's capacity for neural computation is arguably unmatched. Yet despite evidence of cerebellar contributions to cognition, including language, its precise role remains debated. Here, we sy...
New paper! 🧠 **The cerebellar components of the human language network**
with: @hsmall.bsky.social @moshepoliak.bsky.social @gretatuckute.bsky.social @benlipkin.bsky.social @awolna.bsky.social @aniladmello.bsky.social and @evfedorenko.bsky.social
www.biorxiv.org/content/10.1...
1/n 🧵
21.04.2025 15:19 — 👍 50 🔁 20 💬 2 📌 3
APA PsycNet
PINEAPPLE, LIGHT, HAPPY, AVALANCHE, BURDEN
Some of these words are consistently remembered better than others. Why is that?
In our paper, just published in J. Exp. Psychol., we provide a simple Bayesian account and show that it explains >80% of variance in word memorability: tinyurl.com/yf3md5aj
10.04.2025 14:38 — 👍 40 🔁 14 💬 1 📌 0
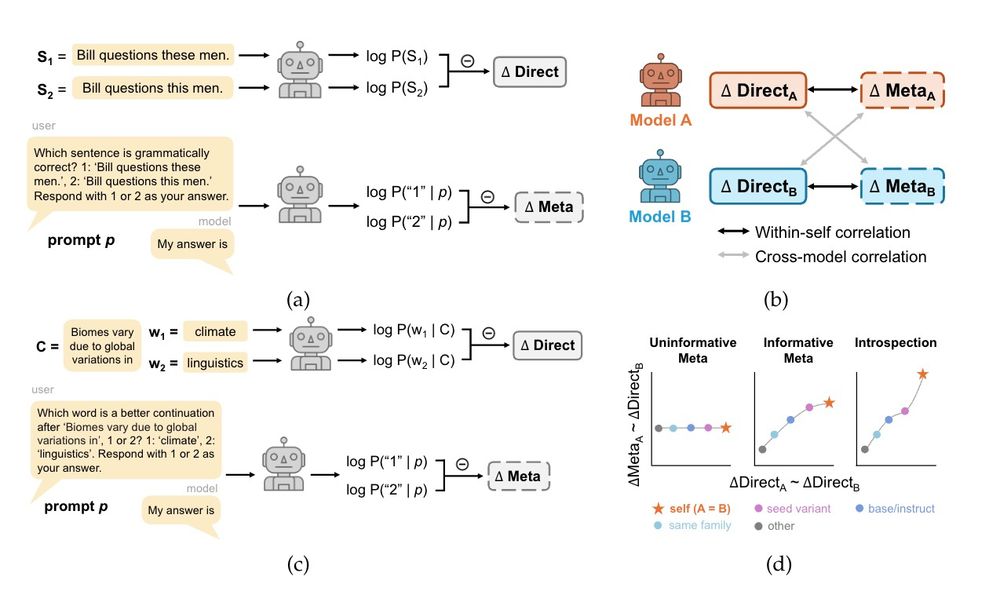
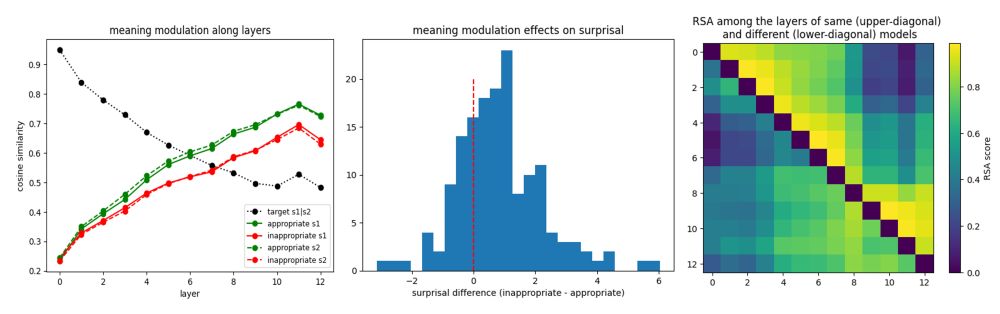
New preprint w/ @jennhu.bsky.social @kmahowald.bsky.social : Can LLMs introspect about their knowledge of language?
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
12.03.2025 14:31 — 👍 60 🔁 16 💬 2 📌 4
PhD supervised by Tim Rocktäschel and Ed Grefenstette, part time at Cohere. Language and LLMs. Spent time at FAIR, Google, and NYU (with Brenden Lake). She/her.
IVADO est un consortium de recherche, de formation et de mobilisation des connaissances qui a pour mission de bâtir et de promouvoir une IA robuste, raisonnante et responsable.
Medical Doctor (UCL). Interests in communication, psychopathology of language, abstraction and metaphor. New to Bluesky
Official profile of the Center for Mind/Brain Sciences, University of Trento (Italy)
www.cimec.unitn.it
comparative linguist, MPI for Evolutionary Anthropology (Leipzig); https://www.eva.mpg.de/linguistic-and-cultural-evolution/staff/martin-haspelmath
CCC-SLP, Spanish-English bilingual, and doc student at UW-Madison 🦡
Researching speech in children with craniofacial conditions 💬
Postdoctoral researcher: synthetic philosophy, the mind and life sciences, history of medicine, psychiatry
Producer @manymindspod.bsky.social;
Contributing editor @publicdomainrev.bsky.social
https://www.linkedin.com/in/urte-laukaityte
https://jessyli.com Associate Professor, UT Austin Linguistics.
Part of UT Computational Linguistics https://sites.utexas.edu/compling/ and UT NLP https://www.nlp.utexas.edu/
Vision science enthusiast, currently PhD student @ Vaziri Lab, UDel.
Simons Postdoctoral Fellow in Pawan Sinha's Lab at MIT. Experimental and computational approaches to vision, time, and development. Just joined Bluesky!
I am Ted Gibson, and I study human language in MIT's Brain and Cognitive Sciences. My lab is sometimes called the Language Lab or Tedlab. I work a lot with Ev Fedorenko.
Cognitive, Systems and Computational Neuroscientist, Professor at UC Berkeley, and lab head. Check out our lab web site http://gallantlab.org For the latest news, publications, brain viewers, code and tutorials, and data.
PhD candidate CLTL VU Amsterdam
Prev. Research Intern Huawei
stefanfs.me
- Harvard Graduate School of Education PhD student studying early language & literacy development
- University of Wisconsin-Madison Language & Cognitive Neuroscience Lab alum
- Big fan of books, tortoises, and ice cream
Postdoc @ Harvard (Buckner Lab)
cognitive neuroscience, precision functional mapping
https://jingnandu93.github.io/
The MIT Siegel Family Quest for Intelligence's community of scientists, engineers, faculty, students, staff, and supporters are aiming to understand intelligence – how brains produce it and how it can be replicated in artificial systems.
Neuroscientist | Brain Inspired Podcast
https://braininspired.co/
Journalist and podcast host @newscientist.com. Former Tokyoite. Books: SUPERHUMAN (2018) and HOW TO SPEND A TRILLION DOLLARS (2021). Next book: TOGETHERNESS (2026). すごい!
computational linguistics @ uw