

A city of drivers expands, relentlessly and inevitably, into sprawl.
A city of pedestrians, cyclists, and transit-users settles, gradually and elegantly, into itself.

@ysawej.bsky.social
Deep Learning, NLP, multimodal models and all things neural network. Also, math guy and computer scientist.
A city of drivers expands, relentlessly and inevitably, into sprawl.
A city of pedestrians, cyclists, and transit-users settles, gradually and elegantly, into itself.

Still the best two sentences on climate action.
29.12.2024 17:42 — 👍 7591 🔁 1565 💬 50 📌 62
An illustrated guide to never learning anything
25.12.2024 00:26 — 👍 146 🔁 20 💬 6 📌 3“The best part of waking up, is your house being quiet and your kids not tearing shit up”
29.11.2024 23:22 — 👍 7 🔁 1 💬 1 📌 0The next coffee drinker whom awakens, understands the joy, of a hot pot ready and waiting.
29.11.2024 11:34 — 👍 11 🔁 1 💬 0 📌 0There is no greater joy than everyone in the house being asleep as you drink your morning coffee.
29.11.2024 11:00 — 👍 7305 🔁 442 💬 304 📌 85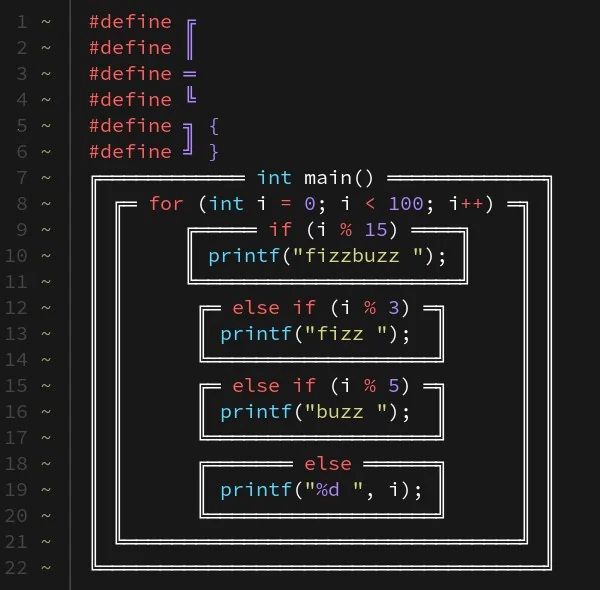
Code written with box characters used on old old software to make fake UIs
You’re still arguing about tabs vs. spaces? May I present…
25.12.2024 18:37 — 👍 5327 🔁 1293 💬 157 📌 149I didn't embark in machine learning thinking of it as an ideological project to disenfranchise human beings.
But we need to face reality, machine learning can easily become the driver of such change, shifting power structures.
We, actors of tech, can modulate this effect.
1/3
📌
21.12.2024 01:42 — 👍 0 🔁 0 💬 0 📌 0
Cartoon by singer sarcastically showing that people wrongly perceive car dependent infrastructure as “public investment” (it isn’t) and investment in public transit as a “wasteful subsidy” (it isn’t, it has an excellent return on investment and actually saves public money).
"Public investment" vs "Wasteful Subsidy." The only problem with this clever Singer cartoon is that some people might actually not get that it’s sarcastically illustrating the perception problem, NOT telling the truth. Just in case it actually needs to be said, the truth is the opposite.
18.12.2024 08:21 — 👍 7019 🔁 923 💬 127 📌 33
Dynamic programming alternatives to dynamic programming for optimal control. Replace your Bellman equation with backpropagation. www.argmin.net/p/twirling-t...
21.11.2024 15:36 — 👍 41 🔁 3 💬 2 📌 0Bookmark
16.12.2024 17:08 — 👍 1 🔁 0 💬 0 📌 0Bookmark
16.12.2024 06:33 — 👍 1 🔁 0 💬 0 📌 0Bookmark
16.12.2024 06:31 — 👍 1 🔁 0 💬 0 📌 0boundary2 just published a forum on the gordian knot of finance, where @stefeich.bsky.social, @aminsamman.bsky.social, @thisblue.bsky.social, Janet Roitman, Dick Bryan, and myself reflect on the infuriating hold of finance on economic policy (and how to break it)
www.boundary2.org/the-gordian-...
The tech bro fascination with eugenics is so on brand. The idea that you could make accurate, actionable predictions from individual genotypes (with all their complex, non-linear interactions) from averaged, linearly modeled population-level genomic statistics is just another big data fantasy
12.12.2024 16:13 — 👍 3070 🔁 483 💬 130 📌 101
jacob sansbury @jsnnsa having kids in the next 5 years might be a tragic mistake every smart bio founder/scientist i’ve talked to seems to think embryo editing for things like short sleeper, reduced cancer risk, etc is possible on a near term horizon imagine having two kids a couple years apart, one is a super human and the other isn’t “sorry jim, little timmy won’t get cancer, only needs 4 hours of sleep and you’re normal you were just born in the wrong order 🤷🏻 “
Tech bros know what every parent wants: children who sleep less
11.12.2024 14:39 — 👍 8650 🔁 1211 💬 515 📌 720noice!
09.12.2024 10:49 — 👍 14 🔁 5 💬 0 📌 0
Insane lack of transparency from OpenAI. Saying the models people use are different than the "final" evals they released. Do better. Especially enterprises will move elsewhere because of this stuff.
06.12.2024 22:00 — 👍 56 🔁 5 💬 5 📌 0Zuck is developing 2GW+ data center.
"Last big AI update of the year:
• Meta AI now has nearly 600M monthly actives
• Releasing Llama 3.3 70B text model that performs similarly to our 405B
• Building 2GW+ data center to train future Llama models
Next stop: Llama 4. Let's go!"

Old quant types (some base model types require these): - Q4_0: small, very high quality loss - legacy, prefer using Q3_K_M - Q4_1: small, substantial quality loss - legacy, prefer using Q3_K_L - Q5_0: medium, balanced quality - legacy, prefer using Q4_K_M - Q5_1: medium, low quality loss - legacy, prefer using Q5_K_M New quant types (recommended): - Q2_K: smallest, extreme quality loss - not recommended - Q3_K: alias for Q3_K_M - Q3_K_S: very small, very high quality loss - Q3_K_M: very small, very high quality loss - Q3_K_L: small, substantial quality loss - Q4_K: alias for Q4_K_M - Q4_K_S: small, significant quality loss - Q4_K_M: medium, balanced quality - recommended - Q5_K: alias for Q5_K_M - Q5_K_S: large, low quality loss - recommended - Q5_K_M: large, very low quality loss - recommended - Q6_K: very large, extremely low quality loss - Q8_0: very large, extremely low quality loss - not recommended - F16: extremely large, virtually no quality loss - not recommended - F32: absolutely huge, lossless - not recommended
Learning about quantization suffixes while `ollama pull llama3.3` download completes (fyi, quantization for the default 70b is q4_K_M)
• make-ggml .py: github.com/ggerganov/ll...
• pull request: github.com/ggerganov/ll...
Bookmark
06.12.2024 02:49 — 👍 0 🔁 0 💬 0 📌 0
Will be at #NeurIPS2024 Dec 10-13. Looking forward to run into everyone in #AI all at once🤞 The 2019 Vancouver one was the largest conf I ever attended--not sure how they plan to cram even more this time.. 😱
[Will be at our poster on 12/11 morning openreview.net/forum?id=kPB... ]
📣I'm hiring PhD interns for combined theory+empirical projects in: exploration in post-training, multi-task learning in autoregressive models, distillation, reasoning beyond CoT.
Apply on the link below. If you're at #NeurIPS2024, message me to chat.
jobs.careers.microsoft.com/global/en/jo...
The paper proposes a single-channel Deep Cascade Fusion of Diarization and Separation (DCF-DS) framework for back-end speech recognition, achieving first place in the realistic single-channel track of the CHiME-8 NOTSOFAR-1 challenge.
12.11.2024 10:03 — 👍 2 🔁 1 💬 0 📌 0📝 Summary:
The project is about Speaker Diarization using OpenAI Whisper, combining ASR capabilities with VAD and Speaker Embedding to identify speakers in transcriptions. The pipeline corrects timestamps, extracts vocals, and aligns timestamps for accurate speaker identification. (1/3)
I'm excited to share that we've released v1.0 of our podcast corpus, SPoRC, led by my PhD student Ben Litterer! This first dataset is a slice of time, comprising over one million episodes from May and June 2020, including transcripts, diarization, and extracted audio features.
15.11.2024 15:03 — 👍 52 🔁 16 💬 1 📌 4
Thrilled to share our NeurIPS spotlight on uncertainty disentanglement! ✨ We study how well existing methods disentangle different sources of uncertainty, like epistemic and aleatoric. While all tested methods fail at this task, there are promising avenues ahead. 🧵 👇 1/7
📖: arxiv.org/abs/2402.19460

It wasn't even the transformer paper that was first to show attention was all you need. Everyone forgets how aggressively folks were working on faster alternatives to RNNs ~2016, and another paper from Google did a pure attention model first: arxiv.org/abs/1606.01933
02.12.2024 03:48 — 👍 23 🔁 3 💬 3 📌 1


















