
Looking back and forth between Barthes, Sedgwick, and Hirsch trying to interpret a Star Trek scene when I'm 90% sure the explanation is just "the actor had a crush on his costar"
07.03.2026 09:38 — 👍 0 🔁 0 💬 0 📌 0Looking back and forth between Barthes, Sedgwick, and Hirsch trying to interpret a Star Trek scene when I'm 90% sure the explanation is just "the actor had a crush on his costar"
07.03.2026 09:38 — 👍 0 🔁 0 💬 0 📌 0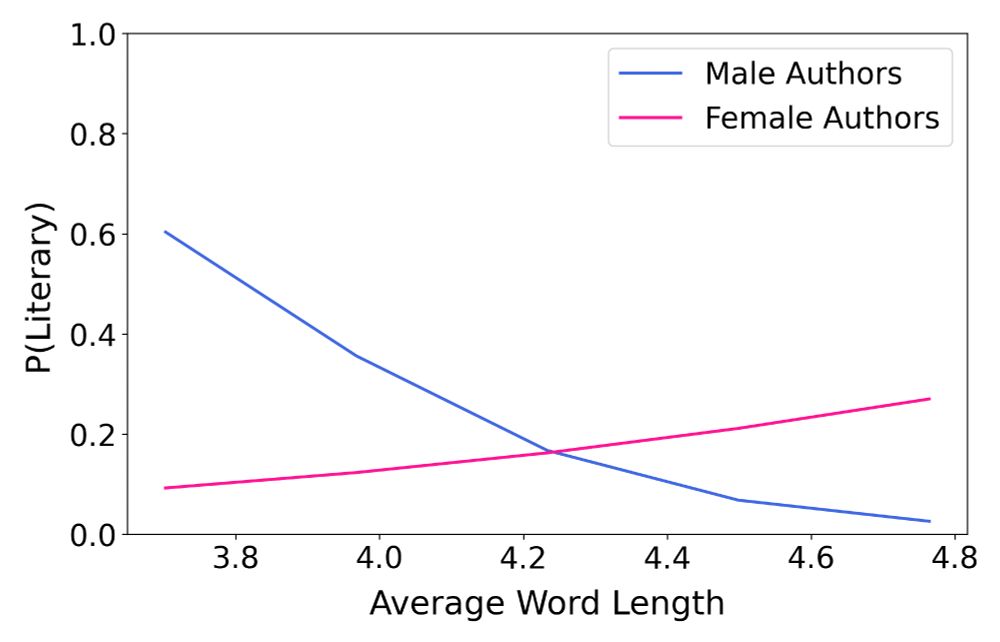
Plot illustrating how a book's probability of being classified as literary fiction varies with average word length and author gender. For female authors, longer words are correlated with an increased likelihood of literary classification. For male authors, the inverse is true.
Unsurprising: Using longer words makes female authors more “literary”
Surprising: The opposite is true for male authors
For more cool plots + findings, take a look at my #CHR2025 paper exploring the role of form vs gender in the classification of genre & literary fiction
doi.org/10.63744/Ztw...
I’ll be presenting this work in **2 hours** at EMNLP’s Gather Session 3. Come by to chat about fanfiction, literary notions of similarity, long-context modeling, and consent-focused data collection!
05.11.2025 22:01 — 👍 7 🔁 1 💬 0 📌 0
This was joint work with @abertsch.bsky.social, Maria-Emil Deal, and @strubell.bsky.social
Paper: arxiv.org/abs/2510.20926
Dataset: huggingface.co/datasets/fic...

The performance (Spearman's rank correlation coefficient) of a number of embedding models across fine-grained semantic categories and superficial categories like author name. All models perform far worse on fine-grained categories than superficial categories. Explicit prompting for the category of interest is ineffective.
Even strong embedding models over-index on surface features—for every model tested, similarity scores are more reflective of author or fandom than semantic aspects like theme or characterization. This is true even if models are explicitly instructed to focus on these aspects!
05.11.2025 21:59 — 👍 6 🔁 0 💬 1 📌 0
A screenshot of Archive of Our Own's story metadata for one of the stories in FicSim, annotated for different types of similarity. Some fields (like content rating and category) are always assigned to categories like style or relationship dynamic, while other groups of tags are classified individually by annotators.
All selected fanfiction has detailed metadata and author-generated tags describing the fanfic content. Informed by fan studies and digital humanities literature, we classify these into 12 categories to construct gold labels for a fine-grained semantic similarity task.
05.11.2025 21:59 — 👍 7 🔁 0 💬 1 📌 0
Histogram of story length, ranging from 10 thousand to over 400 thousand words. Most stories are between 10 to 90 thousand words.
We introduce FicSim, a dataset of 90 recently written long-form fanfics from Archive of Our Own. We *reach out to the authors for permission* to use each work and prioritize continual, informed author consent. Fics range in length from 10K to 400K+ words.
05.11.2025 21:59 — 👍 10 🔁 0 💬 1 📌 0
Figure showing a similarity comparison between three stories. Story A and story B have the same author, and story A and story C have the same tone. A human might care about which stories are tonally the most similar, but a language model's notion of similarity is strongly informed by surface-level features like small differences in writing style across authors.
Digital humanities researchers often care about fine-grained similarity based on narrative elements like plot or tone, which don’t necessarily correlate with surface-level textual features.
Can embedding models capture this? We study this in the context of fanfiction!