
31% of US adults use generative AI for healthcare 🤯But most AI systems answer questions assertively—even when they don’t have the necessary context. Introducing #MediQ a framework that enables LLMs to recognize uncertainty🤔and ask the right questions❓when info is missing: 🧵
06.12.2024 22:51 —
👍 68
🔁 14
💬 2
📌 2
Excited to be at #ICLR2025 🤩
I'll be giving an oral presentation for Creativity Index on Fri 25th 11:06, Garnet 212&219 🎙️
I'll also be presenting posters:
📍ExploreToM, Sat 26th 10:00, Hall 3 + 2B #49
📍CreativityIndex, Fri 25th 15:00, Hall 3 + 2B #618
Hope to see you there!
24.04.2025 02:25 —
👍 8
🔁 1
💬 0
📌 0

A screenshot of the first page of the paper, containing the paper title: Finding Flawed Fictions: Evaluating Complex Reasoning in Language Models via Plot Hole Detection and the names of the authors: Kabir Ahuja, Melanie Sclar, and Yulia Tsvetkov. All the three authors are from CSE department in the University of Washington in Seattle, USA. They can be reached at {kahuja,msclar,yuliats}@cs.washington.edu
📢 New Paper!
Tired 😴 of reasoning benchmarks full of math & code? In our work we consider the problem of reasoning for plot holes in stories -- inconsistencies in a storyline that break the internal logic or rules of a story’s world 🌎
W @melaniesclar.bsky.social, and @tsvetshop.bsky.social
1/n
22.04.2025 18:50 —
👍 10
🔁 4
💬 1
📌 1

Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
High-quality training data has proven crucial for developing performant large language models (LLMs). However, commercial LLM providers disclose few, if any, details about the data used for training. ...
Want to know what training data has been memorized by models like GPT-4?
We propose information-guided probes, a method to uncover memorization evidence in *completely black-box* models,
without requiring access to
🙅♀️ Model weights
🙅♀️ Training data
🙅♀️ Token probabilities 🧵 (1/5)
21.03.2025 19:08 —
👍 97
🔁 27
💬 4
📌 8

🚨New Paper! So o3-mini and R1 seem to excel on math & coding. But how good are they on other domains where verifiable rewards are not easily available, such as theory of mind (ToM)? Do they show similar behavioral patterns? 🤔 What if I told you it's...interesting, like the below?🧵
20.02.2025 17:34 —
👍 22
🔁 5
💬 3
📌 1

We are launching HALoGEN💡, a way to systematically study *when* and *why* LLMs still hallucinate.
New work w/ Shrusti Ghela*, David Wadden, and Yejin Choi 💫
📝 Paper: arxiv.org/abs/2501.08292
🚀 Code/Data: github.com/AbhilashaRav...
🌐 Website: halogen-hallucinations.github.io 🧵 [1/n]
31.01.2025 18:27 —
👍 34
🔁 8
💬 3
📌 4

I’m on the academic job market this year! I’m completing my @uwcse.bsky.social @uwnlp.bsky.social Ph.D. (2025), focusing on overcoming LLM limitations like hallucinations, by building new LMs.
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
04.12.2024 13:26 —
👍 71
🔁 17
💬 3
📌 2
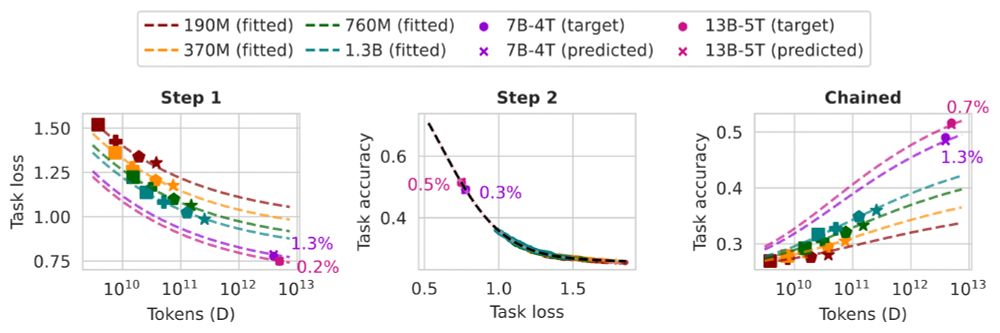
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
09.12.2024 17:07 —
👍 33
🔁 14
💬 2
📌 0

poster for paper
excited to be at #NeurIPS2024! I'll be presenting our data mixture inference attack 🗓️ Thu 4:30pm w/ @jon.jon.ke — stop by to learn what trained tokenizers reveal about LLM development (‼️) and chat about all things tokenizers.
🔗 arxiv.org/abs/2407.16607
11.12.2024 22:08 —
👍 13
🔁 4
💬 0
📌 0
See our latest work on (among other things) machine text detection through linguistic creativity measurement!
22.11.2024 19:07 —
👍 3
🔁 1
💬 0
📌 0
1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
19.11.2024 16:30 —
👍 161
🔁 39
💬 6
📌 8
We'd love to be in your starter pack!
19.11.2024 01:19 —
👍 2
🔁 0
💬 1
📌 0

