
🙏Big thanks to @danielbarath.bsky.social @andreasgeiger.bsky.social and @marcpollefeys.bsky.social
for a great collaboration on this project!
🙏Big thanks to @danielbarath.bsky.social @andreasgeiger.bsky.social and @marcpollefeys.bsky.social
for a great collaboration on this project!

🏆ReSplat achieves state-of-the-art performance on DL3DV and RealEstate10K, across various input views (2, 8, 16) and resolutions (256x256-540×960).
Check out our paper for detailed results: arxiv.org/abs/2510.08575

🧠To initialize the recurrent process, we design a compact reconstruction model that operates in a 16x subsampled space, producing 16x fewer Gaussians than previous pixel-aligned models. This substantially reduces computational overhead and allows for efficient Gaussian updates.
10.10.2025 20:12 — 👍 1 🔁 0 💬 1 📌 0
🎯Key idea: the Gaussian splatting rendering error provides a rich feedback signal, guiding the recurrent network to learn effective Gaussian updates. This feedback naturally adapts to unseen data, enabling robust generalization across datasets and resolutions.
10.10.2025 20:12 — 👍 1 🔁 0 💬 1 📌 0
⚡Feed-forward Gaussian splatting is fast but limited: it only makes a single forward pass. ReSplat introduces recurrent refinement, enabling the model to iteratively improve the 3D Gaussians. ReSplat converges fast, requiring only three iterations.
10.10.2025 20:12 — 👍 1 🔁 0 💬 1 📌 0
🚀Excited to share our recent work on test-time scaling for feed-forward Gaussian splatting:
we learn a recurrent model ReSplat that is able to iteratively improve the reconstruction quality in a feed-forward manner!
haofeixu.github.io/resplat/
Check out Frano's amazing work on multi-view 3D point tracking! 🚀 Code, models, datasets, and interactive results — all available!
29.08.2025 15:20 — 👍 2 🔁 0 💬 0 📌 0
🚀 Introducing our new paper, MDPO: Overcoming the Training-Inference Divide of Masked Diffusion Language Models.
📄 Paper: www.scholar-inbox.com/papers/He202...
arxiv.org/pdf/2508.13148
💻 Code: github.com/autonomousvi...
🌐 Project Page: cli212.github.io/MDPO/
Project page: chengzhag.github.io/publication/...
Code: github.com/chengzhag/Pa...
Interact with the scene in this video (best viewed on a desktop browser or Youtube app): www.youtube.com/watch?v=9bKZ...
Wanna scale your feed-forward Gaussian Splatting model to 4K resolution? Come check out our #CVPR2025 poster PanSplat today 10:30–12:30 (June 14) at ExHall D, Poster #74!
14.06.2025 05:06 — 👍 4 🔁 0 💬 1 📌 0Kudos to my amazing co-authors: @songyoupeng.bsky.social @fangjinhuawang.bsky.social @hermannblum.bsky.social @danielbarath.bsky.social @andreasgeiger.bsky.social @marcpollefeys.bsky.social !
05.06.2025 12:26 — 👍 2 🔁 0 💬 0 📌 0Catch us on Saturday, June 14 at 5 PM, ExHall D Poster #58!
05.06.2025 12:21 — 👍 0 🔁 0 💬 0 📌 0
Your personalized CVPR 25 @cvprconference.bsky.social conference programs are now available for you!
www.scholar-inbox.com/conference/c...
DepthSplat: Connecting Gaussian Splatting and Depth
Project page: haofeixu.github.io/depthsplat/
Code, models, data: github.com/cvg/depthsplat
Excited to present our #CVPR2025 paper DepthSplat next week!
DepthSplat is a feed-forward model that achieves high-quality Gaussian reconstruction and view synthesis in just 0.6 seconds.
Looking forward to great conversations at the conference!
📣 Excited to share our #CVPR2025 Spotlight paper and my internship project @wayve: SimLingo.
A Vision-Language-Action (VLA) model that achieves state-of-the-art driving performance with language capabilities.
Code: github.com/RenzKa/simli...
Paper: arxiv.org/abs/2503.09594
📢 New paper CVPR 25!
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
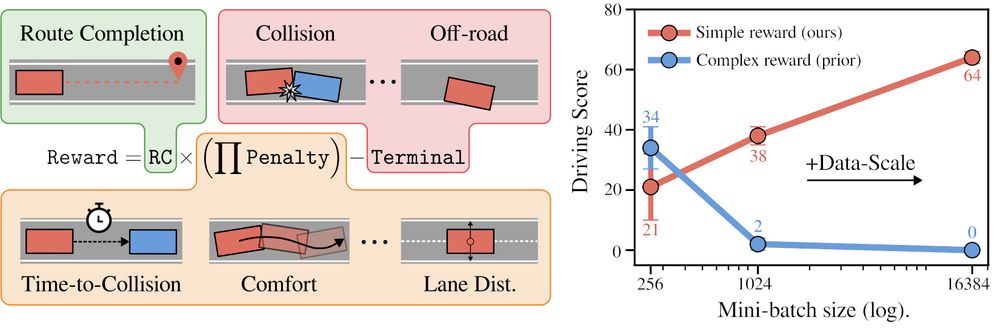
Introducing CaRL: Learning Scalable Planning Policies with Simple Rewards
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
🏠 Introducing DepthSplat: a framework that connects Gaussian splatting with single- and multi-view depth estimation. This enables robust depth modeling and high-quality view synthesis with state-of-the-art results on ScanNet, RealEstate10K, and DL3DV.
🔗 haofeixu.github.io/depthsplat/
Personal programs for ICLR 25 @iclr-conf.bsky.social are now available at www.scholar-inbox.com. Enjoy!
23.04.2025 21:07 — 👍 27 🔁 4 💬 0 📌 0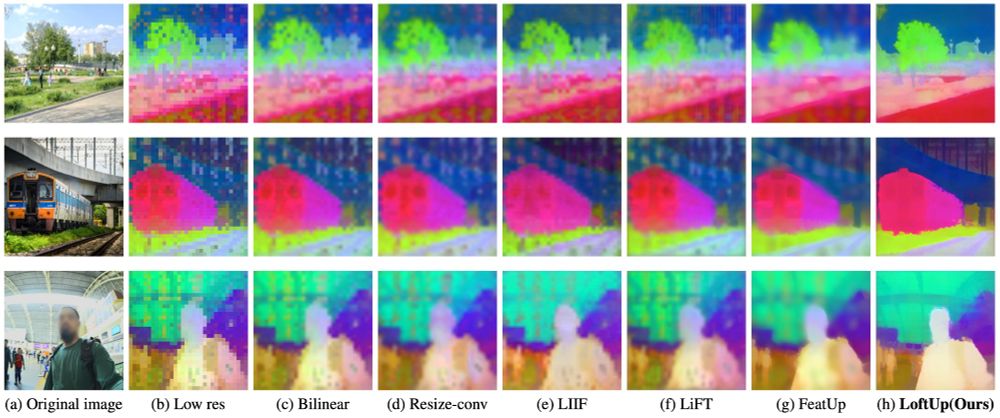
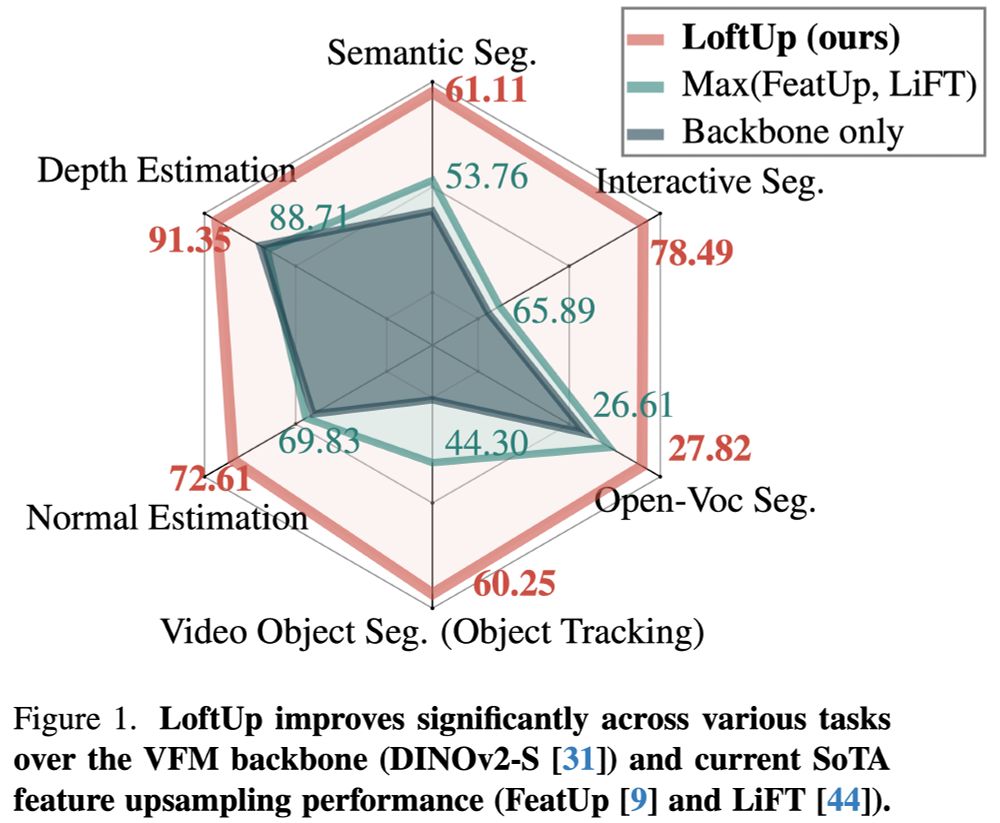
Excited to introduce LoftUp!
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
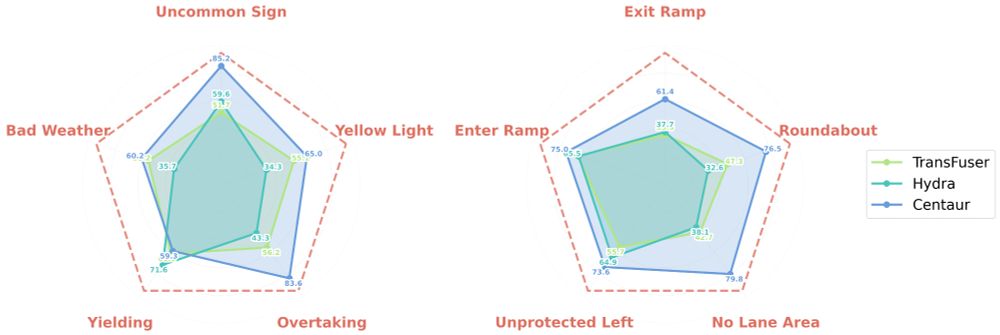
🐎 Centaur, our first foray into test-time training for end-to-end driving. No retraining needed, just plug-and-play at deployment given a trained model. Also, theoretically nearly no overhead in latency with some clever use of buffers. Surprising how effective this is! arxiv.org/abs/2503.11650
17.03.2025 11:03 — 👍 12 🔁 7 💬 1 📌 1



This week we had our winter retreat jointly with Daniel Cremer's group in Montafon, Austria. 46 talks, 100 Km of slopes and night sledding with some occasionally lost and found. It has been fun!
16.01.2025 17:49 — 👍 72 🔁 11 💬 0 📌 1



