

Huge thanks to my amazing co-first author @rassouel.bsky.social and the fantastic @taylorwwebb.bsky.social and @yoshuabengio.bsky.social! Paper: arxiv.org/abs/2506.15871
05.02.2026 20:54 — 👍 7 🔁 1 💬 0 📌 0
Huge thanks to my amazing co-first author @rassouel.bsky.social and the fantastic @taylorwwebb.bsky.social and @yoshuabengio.bsky.social! Paper: arxiv.org/abs/2506.15871
05.02.2026 20:54 — 👍 7 🔁 1 💬 0 📌 0
For cogsci/neuro folks 🧠: Position IDs parallel the dorsal/ventral (where/what) stream separation in the brain. Space appears to be a convergent solution for binding across both biological and artificial systems!
05.02.2026 20:54 — 👍 3 🔁 1 💬 1 📌 0
When these mechanisms fail, behavior degrades. Conditions that degrade Position ID representations (e.g., low-entropy/overlapping features) produce increases in binding errors. Crucially, patching in clean position IDs partially recovers performance, causally linking the mechanism to model failures.
05.02.2026 20:54 — 👍 2 🔁 0 💬 1 📌 0
Interestingly, we found Position IDs use relative rather than absolute spatial coding. When we patch Position IDs between images, models identify objects based on their position relative to the other objects in the scene, rather than their absolute image coordinates.
05.02.2026 20:54 — 👍 1 🔁 0 💬 1 📌 0
We also found evidence that these mechanisms are engaged across tasks such as spatial reasoning, counting, and scene description, and support visual reasoning across diverse image types such as:
🎨 synthetic 2D images
🖼️ synthetic 3D scenes (PUG)
📸 real-world images (COCO)
This architecture generalizes across 7 VLMs, spanning model families (Qwen, LLaVA) and scales (3B→32B). The same three-stage structure and pattern of causal effects appears consistently, suggesting this is a fundamental solution to visual binding in current VLM architectures.
05.02.2026 20:54 — 👍 2 🔁 0 💬 1 📌 0
By intervening on the top-scoring heads, we can directly edit the position IDs to steer the model predictably – causing repetition errors (ID retrieval), redirecting which object is targeted (ID selection), or swapping retrieved features (feature retrieval) – confirming each stage’s causal role.
05.02.2026 20:54 — 👍 3 🔁 0 💬 1 📌 0
RSA reveals this same progression. We first see signatures of position retrieval at prompt tokens (blue), then selection of the target object at the last token (red), and finally retrieval of the target features (green) – representational signatures matching the circuit we identified causally.
05.02.2026 20:54 — 👍 4 🔁 0 💬 1 📌 0
The results confirm our three-stage hypothesis:
🔹ID retrieval heads cluster in layers 14-17
♦️ID selection heads in layers 18-21
🟢 feature retrieval heads in layers 22-27
➡ a clear functional progression through the network!

How did we identify heads for each stage? Causal mediation analysis: we patch head-level activations between conditions (e.g., images w/ swapped objects) and measure which heads produce the predicted behavioral effects (e.g., repeating an object description, retrieving the wrong features, etc.)
05.02.2026 20:54 — 👍 3 🔁 0 💬 1 📌 0
Position IDs operate through a three-stage circuit:
🔹 ID retrieval: link descriptions → spatial indices
♦️ ID selection: compute which position to query next
🟢 Feature retrieval: use position IDs to get features
A genuine visual symbol-processing circuit!

We find that VLMs discover a strikingly similar solution – 'Position IDs' – abstract spatial pointers that track objects by location (visible in intermediate layers), and can be used to retrieve those objects' features (late layers).
05.02.2026 20:54 — 👍 6 🔁 0 💬 1 📌 0
What form might such mechanisms take? Cognitive scientists have proposed that the brain employs spatial indices – content-independent pointers that track objects by location (Pylyshyn's Visual Indexing Theory).
05.02.2026 20:54 — 👍 5 🔁 0 💬 1 📌 1
The visual world is composed of objects, and those objects are composed of features. But do VLMs exploit this compositional structure when processing multi-object scenes? In our 🆒🆕 #ICLR2026 paper, we find they do – via emergent symbolic mechanisms for visual binding. 🧵👇
05.02.2026 20:54 — 👍 83 🔁 25 💬 1 📌 3
How do diverse context structures reshape representations in LLMs?
In our new work, we explore this via representational straightening. We found LLMs are like a Swiss Army knife: they select different computational mechanisms reflected in different representational structures. 1/
Our paper “The cost of thinking is similar between large reasoning models and humans” is now out in PNAS! 🤖🧠
w/ @fepdelia.bsky.social, @hopekean.bsky.social, @lampinen.bsky.social, and @evfedorenko.bsky.social
Link: www.pnas.org/doi/10.1073/... (1/6)
When does new learning interfere with existing knowledge in people and ANNs? Great to have this out today in @nathumbehav.nature.com
Work with @summerfieldlab.bsky.social, @tsonj.bsky.social, Lukas Braun and Jan Grohn
www.nature.com/articles/s41...

Excited to share a new preprint w/ @annaschapiro.bsky.social! Why are there gradients of plasticity and sparsity along the neocortex–hippocampus hierarchy? We show that brain-like organization of these properties emerges in ANNs that meta-learn layer-wise plasticity and sparsity. bit.ly/4kB1yg5
16.07.2025 16:15 — 👍 64 🔁 25 💬 0 📌 3
LLMs have shown impressive performance in some reasoning tasks, but what internal mechanisms do they use to solve these tasks? In a new preprint, we find evidence that abstract reasoning in LLMs depends on an emergent form of symbol processing arxiv.org/abs/2502.20332 (1/N)
10.03.2025 19:08 — 👍 116 🔁 33 💬 4 📌 3
What counts as in-context learning (ICL)? Typically, you might think of it as learning a task from a few examples. However, we’ve just written a perspective (arxiv.org/abs/2412.03782) suggesting interpreting a much broader spectrum of behaviors as ICL! Quick summary thread: 1/7
10.12.2024 18:17 — 👍 123 🔁 32 💬 2 📌 1(8) This work wouldn't have been possible without my amazing collaborators Sunayana Rane, Tyler Giallanza, Nicolò De Sabbata, Kia Ghods, Amogh Joshi, Alexander Ku, @frankland.bsky.social, @cocoscilab.bsky.social, Jonathan Cohen, and @taylorwwebb.bsky.social.
15.11.2024 03:09 — 👍 7 🔁 0 💬 1 📌 0(7) The punchline? Capacity limits aren't just about the number of objects - they stem from interference between representations when processing multiple things at once. This 'binding problem' creates fundamental constraints on parallel processing in both humans and VLMs🧍♂️🤖 .
15.11.2024 03:09 — 👍 5 🔁 0 💬 1 📌 0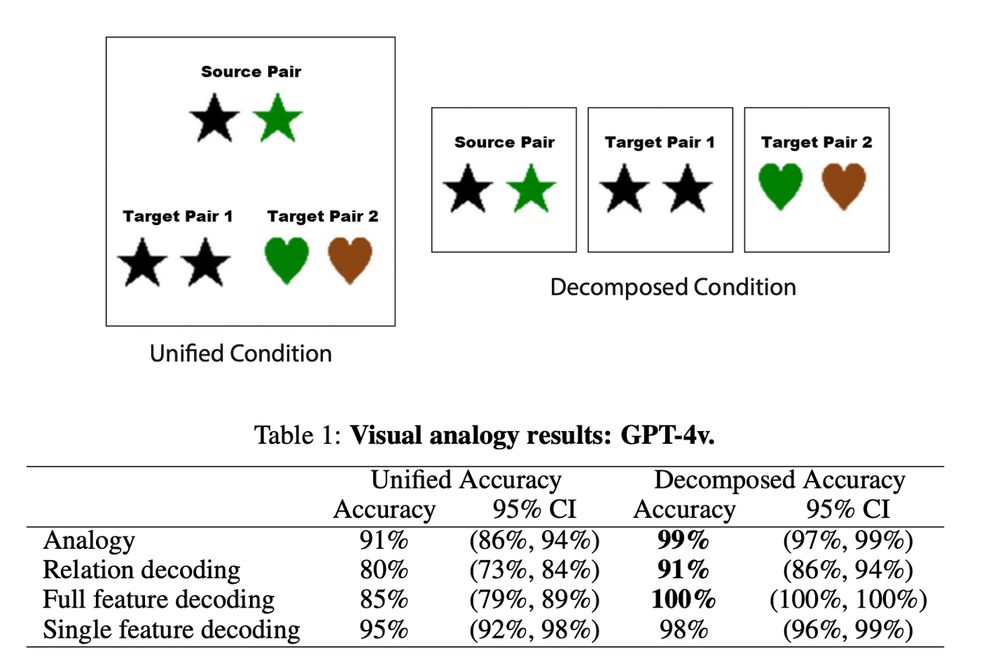
(6) Finally, we found that breaking 🪚🔨 visual analogy tasks into smaller chunks (i.e. performing object segmentation) to mitigate the influence of feature interference improves performance on those tasks.
15.11.2024 03:09 — 👍 3 🔁 0 💬 1 📌 0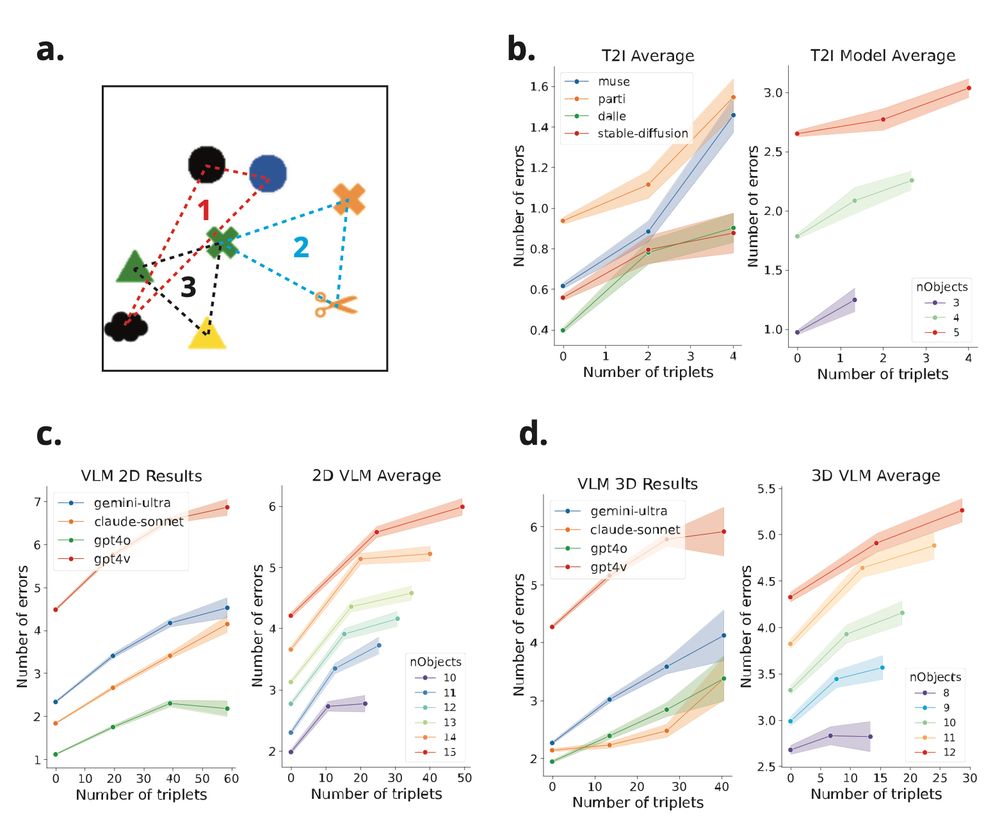
(5) We developed a scene description benchmark inspired by visual working memory tasks to more directly evaluate how feature overlap affects performance. Key finding: Errors spike when objects share overlapping features - driven by 'illusory conjunctions' where features get mixed up!
15.11.2024 03:09 — 👍 3 🔁 0 💬 1 📌 0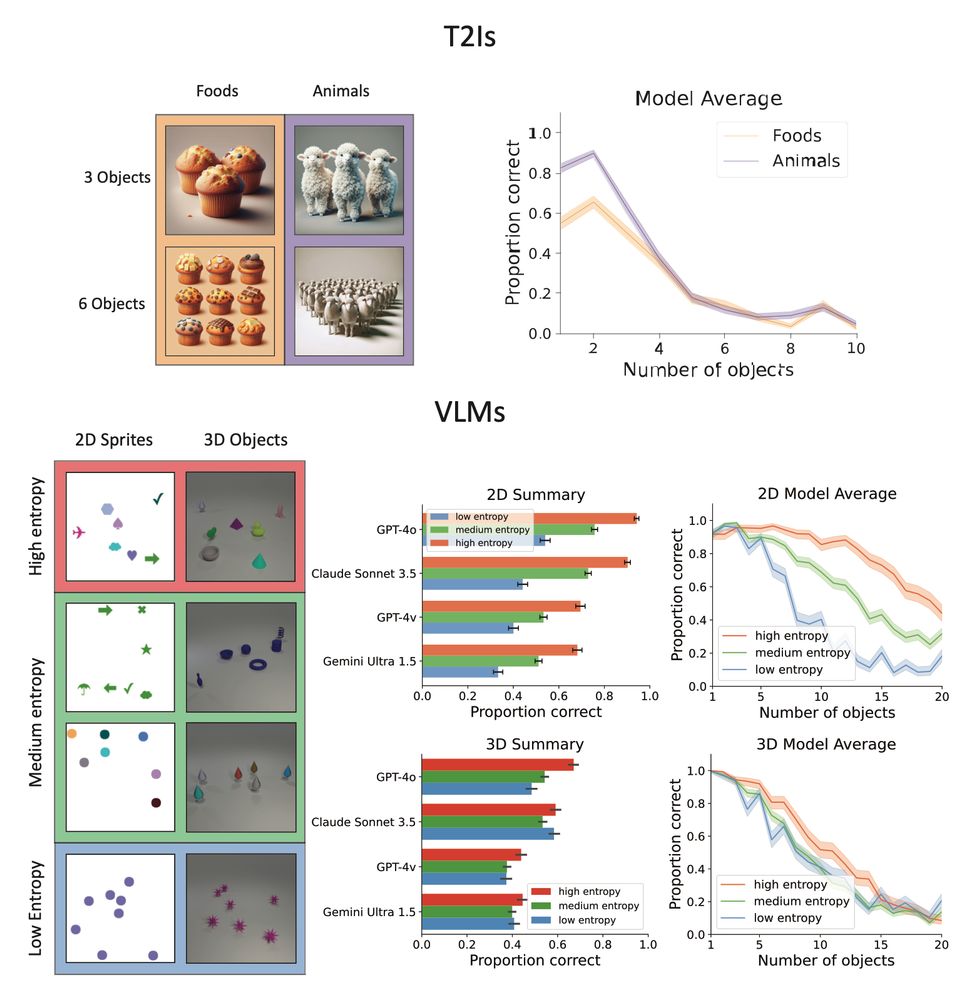
(4) Both multimodal LMs & text-to-image models show strict capacity limits - similar to human 'subitizing' limits during rapid parallel processing. Key finding: They improve with visually distinct objects, suggesting failures stem from feature interference.
15.11.2024 03:09 — 👍 4 🔁 0 💬 1 📌 0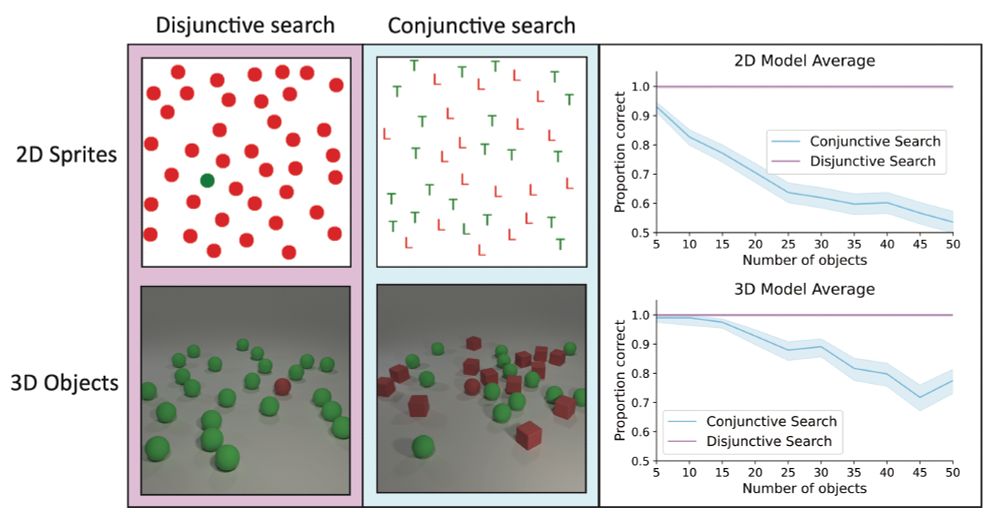
(3) To investigate this, we tested VLMs on classic visual search tasks. They excel at finding unique objects (e.g., one green shape among red shapes 🔴🟢🔴🔴). But searching for specific feature combinations? Performance drops substantially - similar to people when under time pressure.
15.11.2024 03:09 — 👍 4 🔁 0 💬 1 📌 0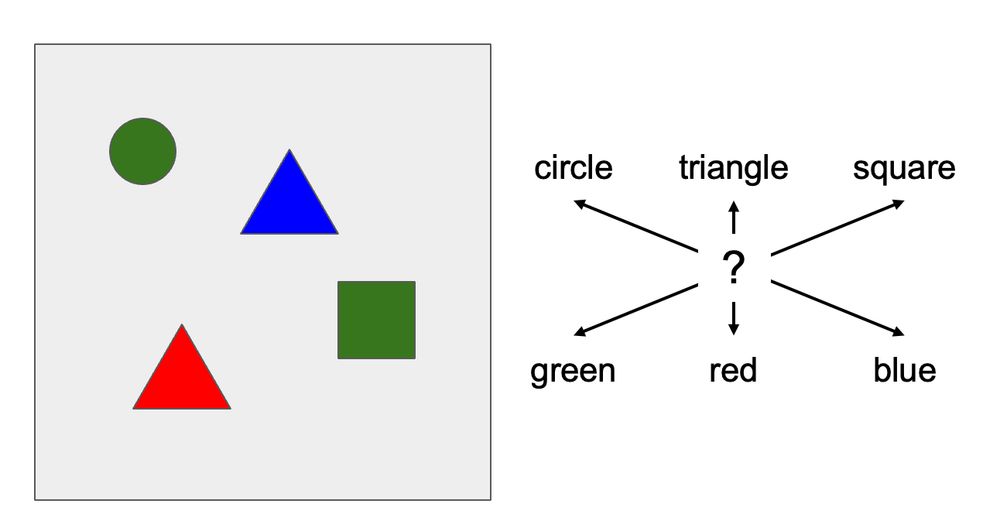
(2) The binding problem refers to difficulties in maintaining correct associations between features (like color & shape 🖍️⬛️) when representing multiple objects over the same representational substrate. These difficulties are a consequence of interference in parallel processing systems.
15.11.2024 03:09 — 👍 6 🔁 0 💬 1 📌 0
(1) Vision language models can explain complex charts & decode memes, but struggle with simple tasks young kids find easy - like counting objects or finding items in cluttered scenes! Our 🆒🆕 #NeurIPS2024 paper shows why: they face the same 'binding problem' that constrains human vision! 🧵👇
15.11.2024 03:09 — 👍 86 🔁 25 💬 5 📌 4