Shlomo Zilberstein (2025 Autonomous Agents Research Award) - ACM SIGAI
The selection committee for the ACM/SIGAI Autonomous Agents Research Award is pleased to announce that Professor Shlomo Zilberstein is the recipient of the 2025 award. Shlomo Zilberstein is Professor…
This year's ACM/SIGAI Autonomous Agents Research Award goes to Prof. Shlomo Zilberstein. His work on decentralized Markov Decision Processes laid the foundation for decision-theoretic planning in multi-agent systems and multi-agent reinforcement learning.
sigai.acm.org/main/2025/03...
#SIGAIAward
11.03.2025 12:15 — 👍 12 🔁 3 💬 0 📌 1
I hear that the other site has been undergoing a Distributed Disinterest in Service attack.
10.03.2025 22:18 — 👍 0 🔁 0 💬 0 📌 0
I had one who was essentially head of Sales.
25.02.2025 18:00 — 👍 1 🔁 0 💬 0 📌 0

Constructive
12.02.2025 20:24 — 👍 1 🔁 0 💬 1 📌 0

Exciting news - early bird registration is now open for #RLDM2025!
🔗 Register now: forms.gle/QZS1GkZhYGRF...
Register now to save €100 on your ticket. Early bird prices are only available until 1st April.
11.02.2025 14:56 — 👍 16 🔁 15 💬 2 📌 2
to the above, I'd add Offline RL (I start with AWR, then IQL and CQL)
10.02.2025 16:27 — 👍 2 🔁 0 💬 0 📌 0
2025 is looking to be the year that information-theoretic principles in sequential decision making, finally make a comeback! (at least for me, I know others never stopped.) already 4 very exciting projects, and counting!
03.02.2025 16:57 — 👍 3 🔁 0 💬 0 📌 0
I received an email from the Department of Energy stating that “DOE is moving aggressively to implement this Executive Order by directing the suspension of [...] DEI policies [...] Community Benefits Plans [... and] Justice40 requirements”.
This probably explains the NSF panel suspensions as well.
28.01.2025 02:54 — 👍 2 🔁 1 💬 0 📌 0

Screenshot of open roles at Fauna Robotics
Want a job in robotics in New York? faunarobotics.com
07.01.2025 01:17 — 👍 29 🔁 10 💬 2 📌 0
Quick links to the 2024 reviewed works:
1. bsky.app/profile/royf...
2. bsky.app/profile/royf...
3. bsky.app/profile/royf...
4. bsky.app/profile/royf...
5. bsky.app/profile/royf...
31.12.2024 20:03 — 👍 0 🔁 0 💬 0 📌 0
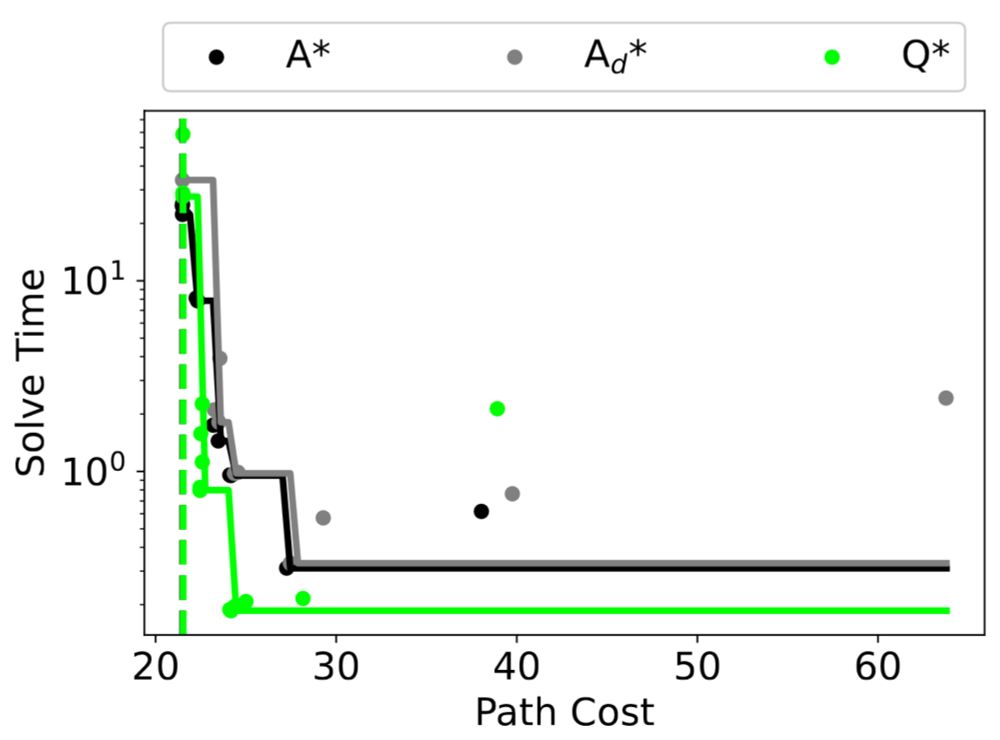
Q* Search: Heuristic Search with Deep Q-Networks
Efficiently solving problems with large action spaces using A* search has been of importance to the artificial intelligence community for decades. This is because the computation and memory requiremen...
2. Using RL to guide search. We called it Q* before OpenAI made that name famous.
“Q* Search: Heuristic Search with Deep Q-Networks”, by Forest Agostinelli, in collaboration with Shahaf Shperberg, Alexander Shmakov, Stephen McAleer, and Pierre Baldi. PRL @ ICAPS 2024.
31.12.2024 20:03 — 👍 3 🔁 0 💬 1 📌 0
Our 2024 research review isn't complete without mentioning 2 workshop papers that preview upcoming publications; I'll leave other things happening as surprises for 2025.
31.12.2024 20:03 — 👍 2 🔁 0 💬 1 📌 0
RLJ · Aquatic Navigation: A Challenging Benchmark for Deep Reinforcement Learning
Reinforcement Learning Journal (RLJ)
Davide Corsi @dcorsi.bsky.social, a rising star in Safe Robot Learning, led this work in collaboration with Guy Amir, Andoni Rodríguez, César Sánchez, and Guy Katz, published in RLC 2024. Not to be confused with Davide's other work in RLC 2024, for which he won a Best Paper Award (see below).
31.12.2024 19:43 — 👍 1 🔁 0 💬 1 📌 0
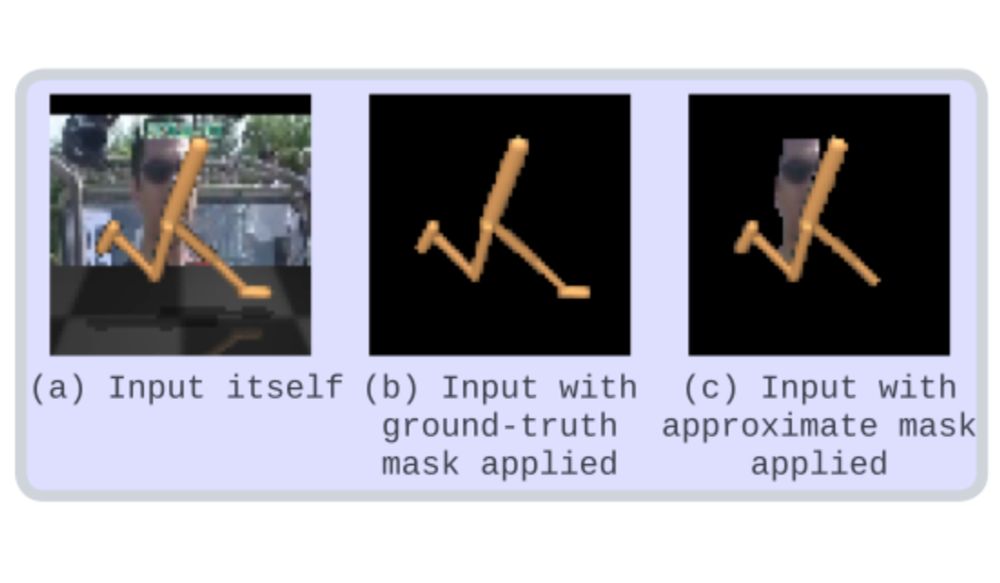
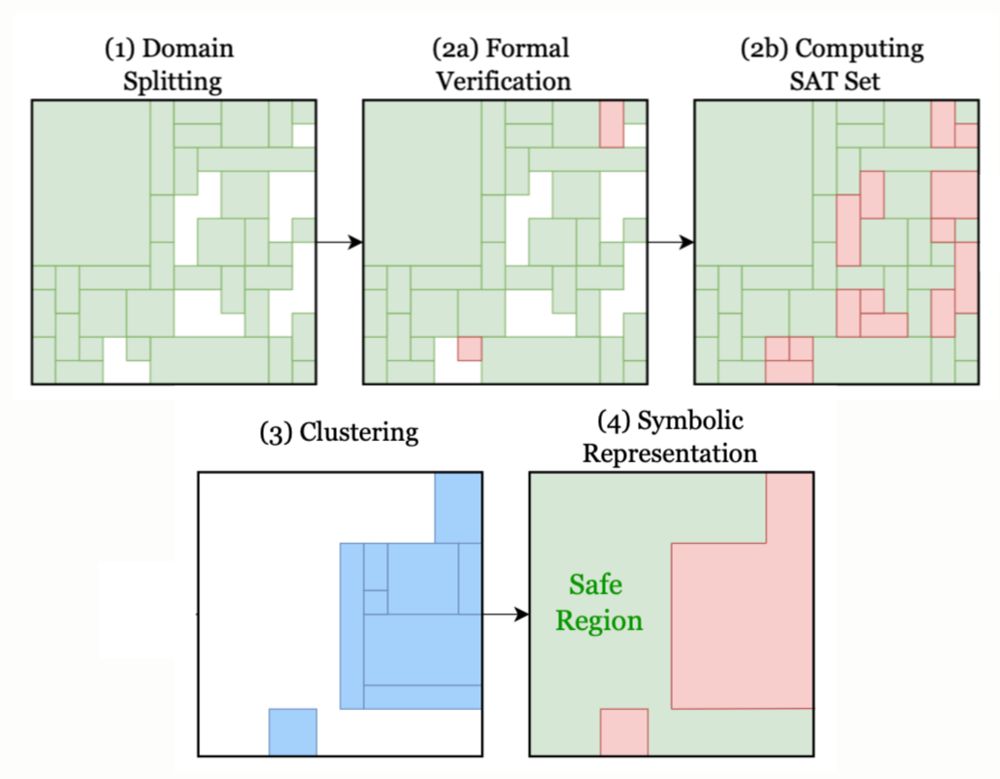
If the unsafe state space is small, and the boundary simplification is careful not to expand it much, the result is that we can safely run the policy and only rarely invoke the shield on unsafe states, leading to significant speedup with safety guarantees.
31.12.2024 19:43 — 👍 0 🔁 0 💬 1 📌 0
The trick is to use offline verification not only to label a policy safe/unsafe, but to label each state safe/unsafe, resp. if the policy's action there satisfies/violates safety constraints. The partition is complex, so we simplify it while guaranteeing no false negatives (no unsafe labeled safe).
31.12.2024 19:43 — 👍 0 🔁 0 💬 1 📌 0
Online verification can be slow but more useful than offline: it's easier to replace occasional unsafe actions than entire unsafe policies. And unsafe actions are often rare, only reducing optimality a little. But it's costly that we need to run the shield on every action, even if it turns out safe.
31.12.2024 19:43 — 👍 0 🔁 0 💬 1 📌 0
Given a control policy (say, a reinforcement-learned neural network) and a set of safety constraints, there are 2 ways to verify safety: offline, where the policy is verified to always output safe actions; and online, where a “shield” intercepts unsafe actions and replaces them with safe ones.
31.12.2024 19:43 — 👍 0 🔁 0 💬 1 📌 0
Led by the fantastic Armin Karamzade in collaboration with Kyungmin Kim and Montek Kalsi, this work was published in RLC 2024.
30.12.2024 19:44 — 👍 1 🔁 0 💬 0 📌 0
This method works well for short delays, but gets worse as the WM drifts over longer horizons than it was trained for. For longer delays, our experiments suggest a simpler method that directly conditions the policy on the delayed WM state and the following actions.
30.12.2024 19:44 — 👍 0 🔁 0 💬 1 📌 0
This suggests several delayed model-based RL methods. Most interestingly, when observations are delayed, we can use the WM to imagine how recent actions could have affected the world state, in order to choose the next action.
30.12.2024 19:44 — 👍 0 🔁 0 💬 1 📌 0
But real-world control problems are often partially observable. Can we use the structure of delayed POMDPs? Recent world modeling (WM) methods have a cool property: they can learn an MDP model of a POMDP. We show that for a good WM of an undelayed POMDP, the delayed WM models the delayed POMDP.
30.12.2024 19:44 — 👍 0 🔁 0 💬 1 📌 0
Previous works have noticed some important modeling tricks. First, delays can be modeled as just partial observability (POMDP), but generic POMDPs lose the nice temporal structure provided by delays. Second, delayed MDPs are still MDPs, in a larger state space — exponential, but keeps the structure.
30.12.2024 19:44 — 👍 0 🔁 0 💬 1 📌 0
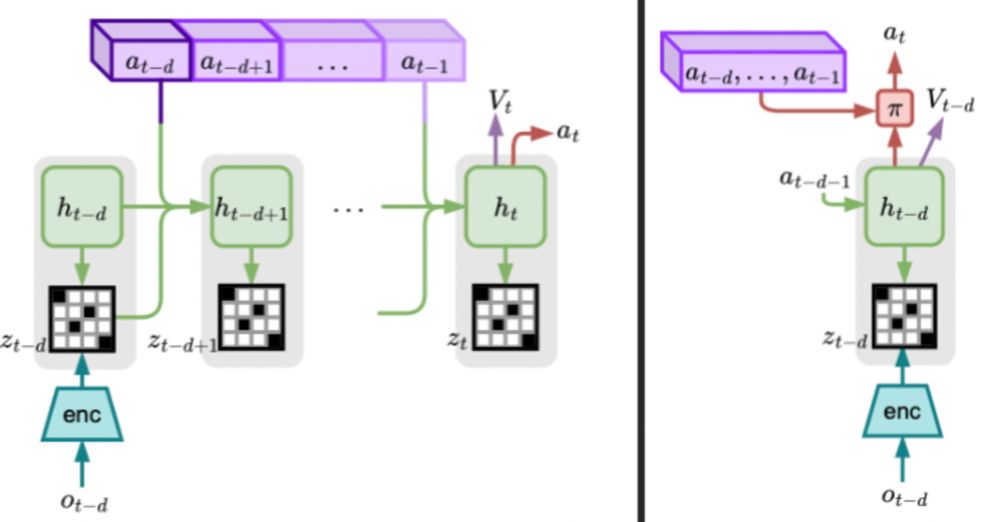
Reinforcement Learning from Delayed Observations via World Models
In standard reinforcement learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true du...
Next up in our 2024 research overview: reinforcement learning under delays. The usual control loop assumes immediate observation and action in each time step, but that's not always possible, as processing observations and decisions can take time. How can we learn to control delayed systems?
30.12.2024 19:44 — 👍 2 🔁 0 💬 1 📌 0
Led by the tireless Kolby Nottingham, partly during his AI2 internship, in collaboration with Bodhisattwa Majumder, Bhavana Dalvi Mishra, @sameer-singh.bsky.social, and Peter Clark, this work was published in ICML 2024.
24.12.2024 03:47 — 👍 0 🔁 0 💬 0 📌 0
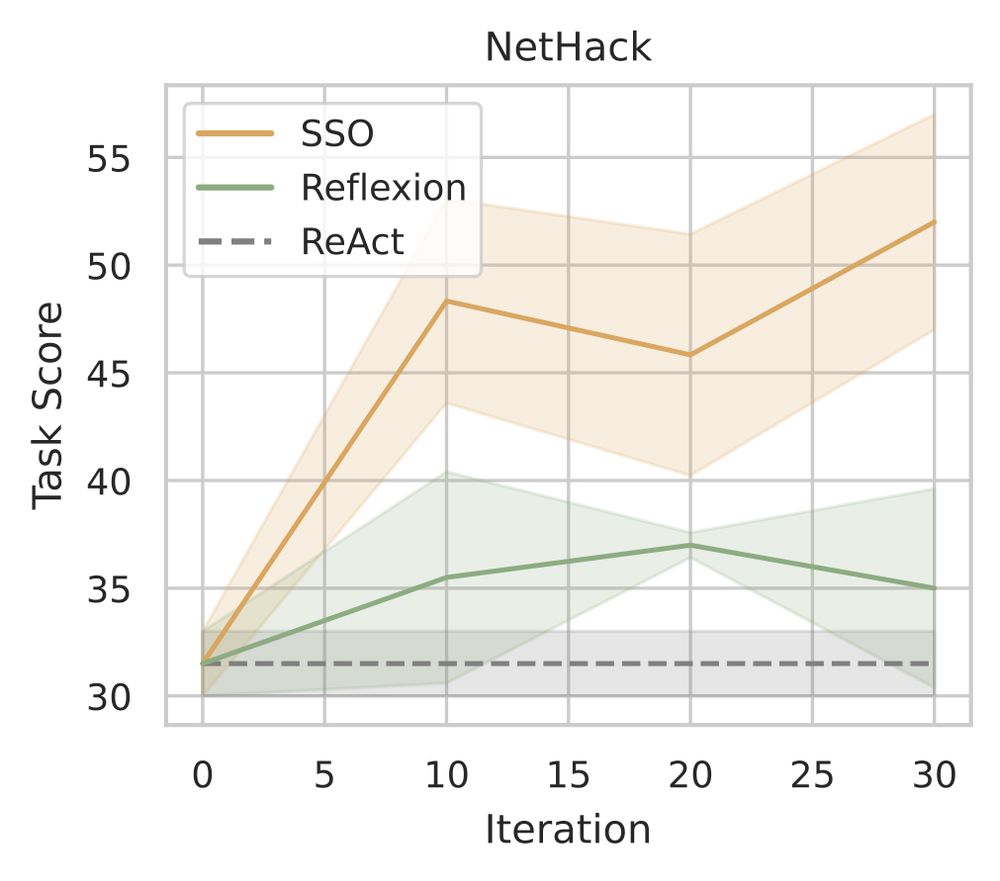
SSO outperforms Reflexion and ReAct on a NetHack benchmark.
Skill Set Optimization (SSO) achieves record task success rate in ScienceWorld and NetHack benchmarks, compared with existing memory-based language agents (ReAct, Reflexion, CLIN).
24.12.2024 03:47 — 👍 0 🔁 0 💬 1 📌 0
How to curate a skill set? Keep evicting skills that are rarely used in high-reward interactions. Here we rely on another prompt to tell us which skills it thinks actually informed actions in successful executions. We only keep those.
24.12.2024 03:47 — 👍 0 🔁 0 💬 1 📌 0
How to learn new skills? Take pairs (or more) of high-reward experiences that follow similar state trajectories and ask a language to describe their shared prototype, i.e. a joint abstraction of their end state + a list of abstract instructions that hint at their actions.
24.12.2024 03:47 — 👍 0 🔁 0 💬 1 📌 0
Here, skill = abstraction of initial state + subgoal + instructions list. We keep a set of those.
How to use a skill set? Retrieve the most relevant skills for the current state (highest similarity to skill initial state) and put them in context for the language agent.
24.12.2024 03:47 — 👍 0 🔁 0 💬 1 📌 0
I work at Sakana AI 🐟🐠🐡 → @sakanaai.bsky.social
https://sakana.ai/careers
The world's leading venue for collaborative research in theoretical computer science. Follow us at http://YouTube.com/SimonsInstitute.
Sr Principal Research Manager, Microsoft Research NYC. Machine Learning, AI Fairness.
Research Scientist at Google DeepMind and Professor of Computer Science and Engineering at the University of Michigan. Interested in Reinforcement Learning and Artificial Intelligence.
Foundation Models for Generalizable Autonomy.
Assistant Professor in AI Robotics, Georgia Tech
prev Berkeley, Stanford, Toronto, Nvidia
4th year PhD Candidate @ UCI working w/ Padhraic Smyth and Sameer Singh
Language scientist at UC Irvine
ML researcher, teacher, professor, Dad, Irish, ...
ML Research Scientist at Dell AI by day, RL Researcher at night
https://rushivarora.github.io
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
RS at Nvidia focussing on autonomous vehicles, simulation and RL. Opinions my own and do not represent those of my employer, Nvidia.
Professor a NYU; Chief AI Scientist at Meta.
Researcher in AI, Machine Learning, Robotics, etc.
ACM Turing Award Laureate.
http://yann.lecun.com
Bot. I daily tweet progress towards machine learning and computer vision conference deadlines. Maintained by @chriswolfvision.bsky.social
Faculty at the University of Pennsylvania. Lifelong machine learning for robotics and precision medicine: continual learning, transfer & multi-task learning, deep RL, multimodal ML, and human-AI collaboration. seas.upenn.edu/~eeaton
Research Goal: Understanding the computational and statistical principles required to design AI/RL agents.
Associate Professor at Polytechnique Montréal and Mila. 🇨🇦
academic.sologen.net
Came for the neuro; stayed for the AI. https://sean-escola.github.io/
🎓 Postdoctoral Researcher @UCIrvine 🤖 Artificial Intelligence and Robotics 📍 Los Angeles 🇺🇲