If you're interested in semantic data processing, you can also check out related systems like DocETL from Shreya Shankar et al., LOTUS from Liana Patel et al., and Palimpzest from Chunwei Liu et al. (4/4)
11.09.2025 15:38 — 👍 0 🔁 0 💬 0 📌 0

Semlib: LLM-powered Data Processing
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs).
These operators are implemented in Semlib, a new library I built to help solve a class of semantic data processing problems that is underserved by current tools such as agents and conversational chatbots.
More on the story and use cases here: anishathalye.com/semlib/. (2/)
11.09.2025 15:36 — 👍 0 🔁 0 💬 1 📌 0

I replaced Python's built-in functions with semantic operators. (1/)
11.09.2025 15:36 — 👍 2 🔁 0 💬 1 📌 0
Current first-world problem: avoiding em-dashes so my writing doesn't look "AI-generated." Been using 'em since 2014, and yep—my blog posts are in Common Crawl. I guess I did this to myself?
10.09.2025 14:20 — 👍 1 🔁 0 💬 0 📌 0

Linearizability testing S2 with deterministic simulation
How we validate strong consistency
Always fun to see when a grad school side project grows to the point where it's powering real systems! Nice blog post from the S2 developers on how they do linearizability testing with deterministic simulation (using, among other tools, Porcupine): s2.dev/blog/lineari...
30.08.2025 14:39 — 👍 2 🔁 0 💬 0 📌 0

Coding agents follow "it's always your fault" a bit too well.
When they hit a compiler bug, they'll rearrange methods, tweak syntax, and go in circles rather than consider the tooling might be wrong.
Had to manually identify and minimize this mypy bug after Claude Code couldn't.
23.08.2025 17:05 — 👍 2 🔁 0 💬 1 📌 0
If you have suggestions for topics to cover in the next iteration of the course, please share them in this thread!
05.08.2025 17:43 — 👍 0 🔁 0 💬 0 📌 0

Missing Semester has grown past 100K subscribers on YouTube. Appreciate all the engagement and support!
We plan to teach another iteration of the course in January 2026, revising the curriculum and covering new topics like AI IDEs and vibe coding.
05.08.2025 17:42 — 👍 12 🔁 4 💬 2 📌 0

My favorite way to measure progress in AI: finding papers obsoleted by ChatGPT prompts
21.06.2025 15:16 — 👍 0 🔁 0 💬 1 📌 0
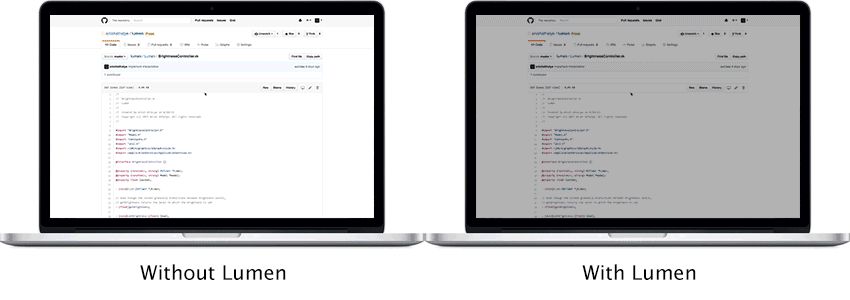
Ever get blinded when writing code late at night and you alt-tab from your dark-mode terminal to your browser? Made this little macOS utility to solve this little problem, just updated for the latest macOS.
No thanks to AI for hallucinating BrightnessKit.framework.
17.06.2025 17:07 — 👍 0 🔁 0 💬 1 📌 0

GitHub - cleanlab/aiuc-workshop: AI User Conference 2025 - Developer Day workshop
AI User Conference 2025 - Developer Day workshop - GitHub - cleanlab/aiuc-workshop: AI User Conference 2025 - Developer Day workshop
We did a workshop at AIUC that: (1) implements a RAG app on top of Cursor's docs, (2) reproduces the widely-publicized failure from last week, and (3) shows how to automatically catch and reproduce this failure. All slides/code are open-sourced here: github.com/cleanlab/aiu... (5/5)
24.04.2025 18:21 — 👍 0 🔁 0 💬 0 📌 0
What’s the solution? I believe that one ingredient will be intelligent systems that evaluate the output of these LLMs in real-time and keep them in check, building on and combining techniques like LLM-as-a-judge, using per-token logprobs, and statistical methods. (4/5)
24.04.2025 18:21 — 👍 0 🔁 0 💬 1 📌 0
Why do such failures occur? These next-token-prediction models are nondeterministic and can be fragile. And they’re not getting consistently better over time—OpenAI’s latest models like o3 and o4-mini show higher hallucination rates compared to previous versions. (3/5)
24.04.2025 18:21 — 👍 0 🔁 0 💬 1 📌 0
It’s been over a year since the well-publicized failures of Air Canada’s support bot and NYC’s MyCity bot. And these AI’s are still failing spectacularly in production, with the most recent debacle being Cursor’s AI going rogue and triggering a wave of cancellations. (2/5)
24.04.2025 18:21 — 👍 0 🔁 0 💬 1 📌 0
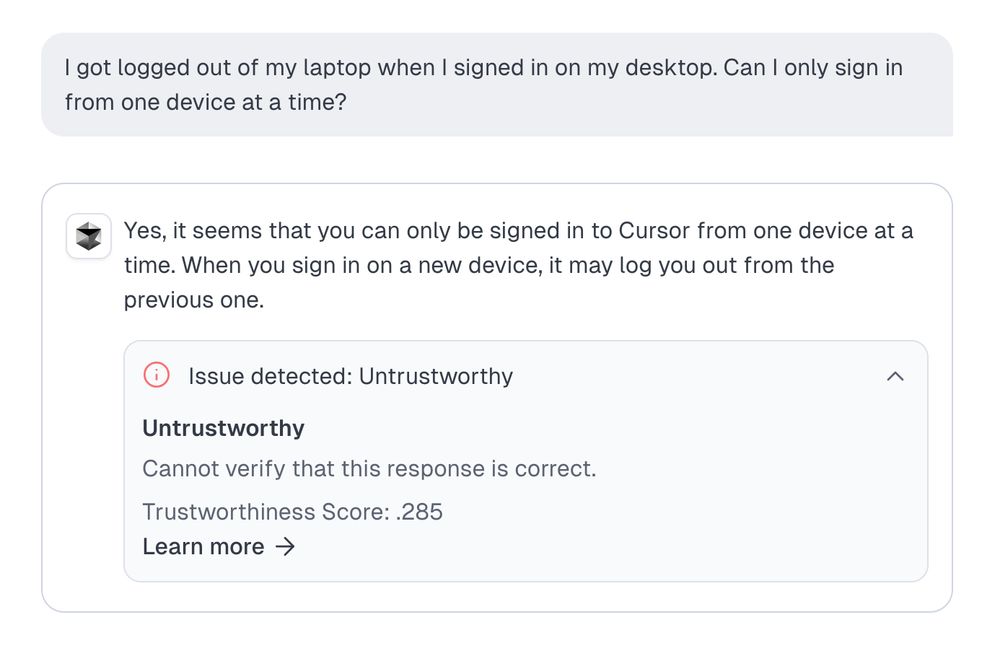
We reproduced (and fixed!) Cursor’s rogue customer support AI. (1/5)
24.04.2025 18:20 — 👍 0 🔁 0 💬 1 📌 0
I wonder if there's anything special in the Cursor Tab completion model or system prompt that induces this behavior.
16.04.2025 22:04 — 👍 0 🔁 0 💬 0 📌 0
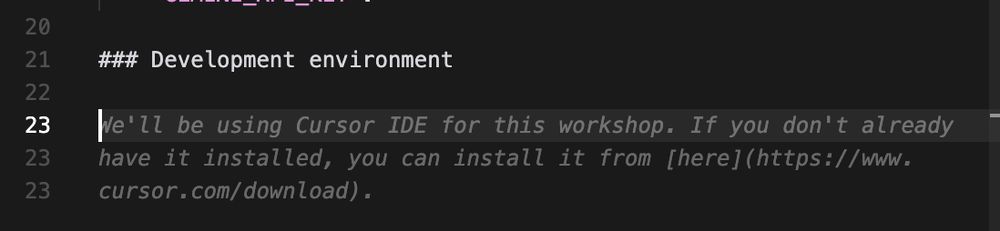
Coincidence, or genius growth hack? Cursor self-propagating through developer set-up instructions.
16.04.2025 22:02 — 👍 0 🔁 0 💬 1 📌 0
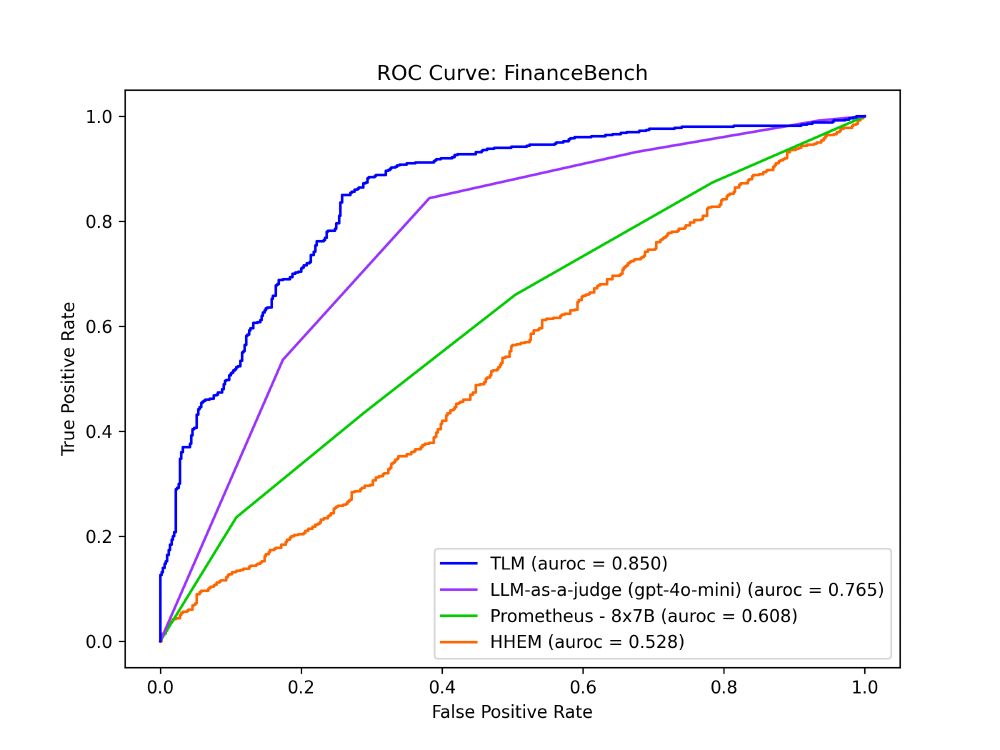
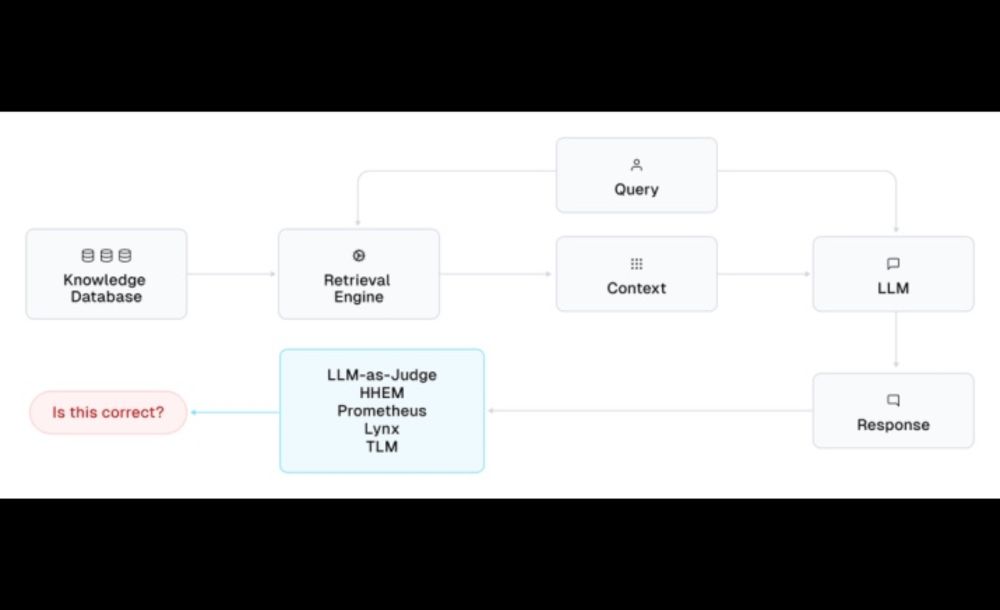
Is AI any good at evaluating AI? Is it turtles all the way down? We benchmarked evaluation models like LLM-as-a-judge, HHEM, Prometheus across 6 RAG applications. 1/2
07.04.2025 23:04 — 👍 1 🔁 0 💬 1 📌 0
And some repos are even organically suggested by ChatGPT. (3/3)
17.02.2025 18:03 — 👍 0 🔁 0 💬 0 📌 0
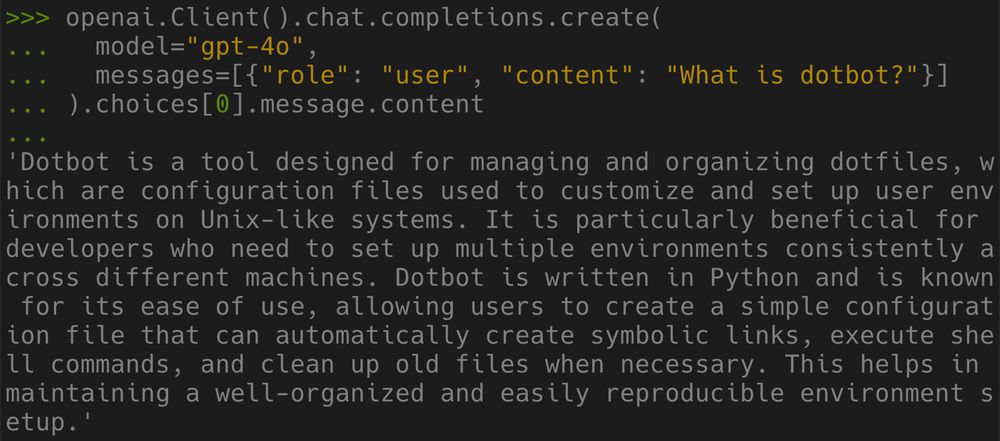
Some of this might be through web search / tool use, but for at least some, knowledge about the projects is actually part of LLM model weights. (2/3)
17.02.2025 18:03 — 👍 0 🔁 0 💬 1 📌 0
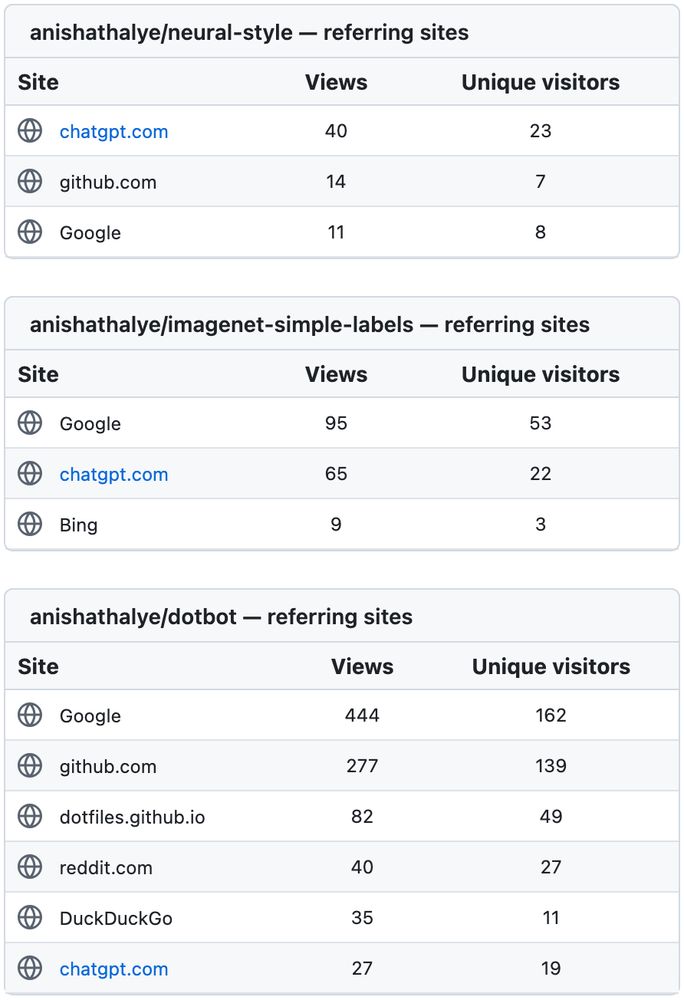
A substantial portion of traffic for some of my open-source projects comes from ChatGPT these days. Sometimes even a majority, beating traffic from Google. Time to prioritize LLM optimization over search engine optimization. (1/3)
17.02.2025 18:02 — 👍 1 🔁 0 💬 1 📌 0