
CMU LTI Summer 2026 Internship Program Application
We are looking for applicants for the Carnegie Mellon University Language Technology Institute's Summer 2026 "Language Technology for All" internship program.
The main goal of this internship is to pr...
🚀 Apply to CMU LTI’s Summer 2026 “Language Technology for All” internship! 🎓 Open to pre‑doctoral students new to language tech (non‑CS backgrounds welcome). 🔬 12–14 weeks in‑person in Pittsburgh — travel + stipend paid. 💸 Deadline: Feb 20, 11:59pm ET. Apply → forms.gle/cUu8g6wb27Hs...
02.02.2026 15:41 —
👍 14
🔁 12
💬 2
📌 0
Had such a great time presenting our tutorial on Interpretability Techniques for Speech Models at #Interspeech2025! 🔍
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
19.08.2025 21:23 —
👍 40
🔁 14
💬 2
📌 1
This wouldn't have been possible with my awesome co-first-author @mmiagshatoy.bsky.social and wonderful supervisors @shinjiw.bsky.social and @strubell.bsky.social!
I'll see you at Rotterdam, Wed 17:00-17:20 Area8-Oral4 (Streaming ASR)! (10/10)
15.08.2025 20:44 —
👍 0
🔁 0
💬 0
📌 0

There's also bunch of engineering tricks that can improve the performance. We provide a pareto-optimal baseline after applying all the available tricks, positioning our work as a foundation for future works in this direction. github.com/Masao-Someki... (9/n)
15.08.2025 20:44 —
👍 0
🔁 0
💬 1
📌 0

We also verified that DSUs are learnable with smaller weights (# of layers), i.e., more lightweight! This implies that we're using self-supervised models inefficiently when extracting DSUs. (8/n)
15.08.2025 20:44 —
👍 0
🔁 0
💬 1
📌 0

We verified that DSUs are learnable with limited attention size (window size), i.e., streamable! This implies that DSUs are temporally "local". (7/n)
15.08.2025 20:44 —
👍 0
🔁 0
💬 1
📌 0

After modifying the architecture, we fine-tune it with the DSUs extracted from the original full model. We're now understanding DSUs as "ground truth" for smaller models. (6/n)
15.08.2025 20:44 —
👍 0
🔁 0
💬 1
📌 0

However, the underlying Transformer model is heavy and non-streamable. We make the model more lightweight (via reducing # of layers) and streamable (via streaming window). (5/n)
15.08.2025 20:44 —
👍 0
🔁 0
💬 1
📌 0
Why DSUs?
(1) High transmission efficiency of ~0.6kbps (.wav files are around 512kbps, 3-4 orders of magnitude bigger!)
(2) Easy integration with LLMs (we can say DSUs are "tokenized speech")
(3) DSUs somewhat "acts" like phonemes (4/n)
15.08.2025 20:44 —
👍 0
🔁 0
💬 1
📌 0

A whirlwind overview of discrete speech units (DSUs): we first train a Transformer model with self-supervision (i.e., self-supervised speech models, S3Ms). Then, we simply apply k-means on top of it. Then, the k-means cluster indices becomes DSUs! (3/n)
15.08.2025 20:44 —
👍 0
🔁 0
💬 1
📌 0
In short, yes! Long story short:
(1) We are using self-supervised models inefficiently when extracting discrete speech units (DSUs), hence can be made more lightweight.
(2) DSUs do not require full temporal receptive field, hence streamable. (2/n)
15.08.2025 20:44 —
👍 0
🔁 0
💬 1
📌 0

Can we make discrete speech units lightweight🪶 and streamable🏎? Excited to share our new #Interspeech2025 paper: On-device Streaming Discrete Speech Units arxiv.org/abs/2506.01845 (1/n)
15.08.2025 20:44 —
👍 1
🔁 1
💬 2
📌 0

Catching crumbs from the table - Nature
In the face of metahuman science, humans have become metascientists.
www.nature.com/articles/350...
Ted Chiang. Catching crumbs from the table. Nature 405, 517 (2000). My favorite sci-fi short, which surprisingly well-summarizes what I actually do nowadays. I bet self-supervised speech models contain undiscovered theories on phonetics and phonology.
09.06.2025 19:36 —
👍 3
🔁 0
💬 0
📌 0

Check out my presentation and poster for more details. I'll see you at NAACL, 4/30 14:00-15:30 Poster Session C! youtu.be/ZRF4u1eThJM (9/9)
29.04.2025 17:00 —
👍 1
🔁 0
💬 0
📌 0

We provide an extensive benchmark containing both pathological and non-native speech, with 8 different methods and 4 different speech features. It measures how well does the speech features model each phonemes accurately. (7/n)
29.04.2025 17:00 —
👍 0
🔁 0
💬 1
📌 0
Based on the observation, we found out that using k-means + Gaussian Mixture Models (GMMs) are actually quite effective for modeling sound distributions.
It's different with classifiers! Classifiers model P(phoneme|sound), where ours model P(sound|phoneme). (6/n)
29.04.2025 17:00 —
👍 0
🔁 0
💬 1
📌 0

So, why is allophony important? We have to model each phonemes accurately for the atypical speech assessment task. It has direct applications to non-native and pathological speech assessment. (5/n)
29.04.2025 17:00 —
👍 0
🔁 0
💬 1
📌 0

Compared to traditional speech features like MFCC or Mel Spectrograms, self-supervised features are much superior in capturing allophony. (4/n)
29.04.2025 17:00 —
👍 0
🔁 0
💬 1
📌 0
A quick background on linguistics: this is supposed to happen! A single phoneme may have multiple realizations. For example, English /t/ is pronounced differently per context: [tʰ] in tap, [t] in stop, [ɾ] in butter, and [ʔ] in kitten. (3/n)
29.04.2025 17:00 —
👍 0
🔁 0
💬 1
📌 0

In short, yes! Even though self-supervised speech models are trained only from raw speech, they cluster via allophonic variations, i.e., different surrounding phonetic environments. (2/n)
29.04.2025 17:00 —
👍 0
🔁 0
💬 1
📌 0

Can self-supervised models 🤖 understand allophony 🗣? Excited to share my new #NAACL2025 paper: Leveraging Allophony in Self-Supervised Speech Models for Atypical Pronunciation Assessment arxiv.org/abs/2502.07029 (1/n)
29.04.2025 17:00 —
👍 15
🔁 10
💬 2
📌 0
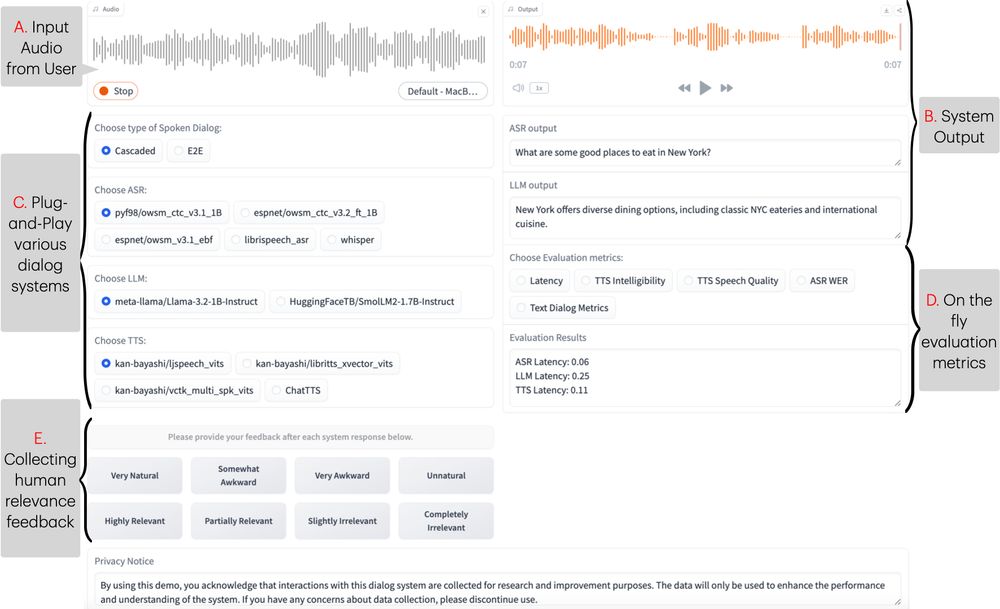
New #NAACL2025 demo, Excited to introduce ESPnet-SDS, a new open-source toolkit for building unified web interfaces for both cascaded & end-to-end spoken dialogue system, providing real-time evaluation, and more!
📜: arxiv.org/abs/2503.08533
Live Demo: huggingface.co/spaces/Siddh...
17.03.2025 14:29 —
👍 7
🔁 5
💬 1
📌 0
More from inside NIH:
Per a source with knowledge, for all internal research (of which there is like $10 billion worth or so), ALL purchasing shut down as of yesterday.
That means gloves, reagents, anything involved with lab work, which means a lot of that work will stop.
24.01.2025 16:24 —
👍 2620
🔁 1290
💬 87
📌 211
CMU LTI Language Technology for All Internship 2025 - Language Technologies Institute - School of Computer Science - Carnegie Mellon University
The LTI is currently seeking applicants for the summer 2025 Language Technology for All Internship
Are you a pre-doctoral student interested in language technologies, especially focusing on safe, fair and inclusive AI? Our Summer 2025 Language Technology for All Internship could be a great fit. See the link below for more info, and to apply:
lti.cs.cmu.edu/news-and-eve...
06.01.2025 21:24 —
👍 16
🔁 13
💬 2
📌 0

📣 #SpeechTech & #SpeechScience people
We are organizing a special session at #Interspeech2025 on: Interpretability in Audio & Speech Technology
Check out the special session website: sites.google.com/view/intersp...
Paper submission deadline 📆 12 February 2025
06.12.2024 21:29 —
👍 16
🔁 9
💬 1
📌 1






