
Optimal Yahtzee - a Hugging Face Space by simonjegou
Discover amazing ML apps made by the community
🎲 Did you know Yahtzee can be solved optimally in less than 100 lines of Python and under 5min with 2 vCPU?
I built a @gradio-hf.bsky.social app so you can try it yourself: huggingface.co/spaces/simon...
Implementation is based on the excellent paper "An Optimal Strategy for Yahtzee" (Glenn, 2006)
31.03.2025 15:07 — 👍 0 🔁 0 💬 0 📌 0

Fresh news from kvpress, our open source library for KV cache compression 🔥
1. We published a blog post with
@huggingface
2. We published a Space for you to try it
3. Following feedback from the research community, we added a bunch of presses and benchmarks
Links👇(1/2)
23.01.2025 10:03 — 👍 2 🔁 0 💬 1 📌 0
Relax, it's Santa
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
How do you find the permutation of words that minimize their perplexity as measured by an LLM ? In this year Kaggle Santa competition, I shared an approach to move to a continuous space where you can use gradient-descent using REINFORCE: www.kaggle.com/code/simjeg/...
03.12.2024 12:40 — 👍 2 🔁 1 💬 0 📌 0

💡 We've just released KV cache quantization in kvpress, our open source package for KV cache compression. Check it out : github.com/NVIDIA/kvpress.
Special thanks for Arthur Zucker and Marc Sun from @huggingface.bsky.social for their support 🤗
26.11.2024 13:23 — 👍 3 🔁 3 💬 0 📌 0
nice work ! Identifying patterns could be done on the fly:
bsky.app/profile/simj...
22.11.2024 07:35 — 👍 2 🔁 0 💬 0 📌 0

🚀 Excited to announce KVPress — our open-source library for efficient LLM KV cache compression!
👉 Check it out (and drop a ⭐): github.com/NVIDIA/kvpress
🔗 Full details in the thread 🧵 (1/4)
19.11.2024 14:25 — 👍 50 🔁 6 💬 2 📌 2
of course it's different ! transformer is an MLP predicting the parameters of another MLP 😀
21.11.2024 18:46 — 👍 1 🔁 0 💬 0 📌 0

Google Colab
You can reproduce this plot using this colab notebook: colab.research.google.com/drive/1DbAEm.... We used this property to create a new KV cache compression called Expected Attention in our kvpress repository:
20.11.2024 10:06 — 👍 3 🔁 0 💬 0 📌 0

Hidden states in LLM ~ follow normal distributions. Consequently, both queries and keys also follow a normal distribution and if you replace all queries and keys by their average counterpart, this magically explains the slash pattern observed in attention matrices
20.11.2024 10:06 — 👍 31 🔁 4 💬 2 📌 1
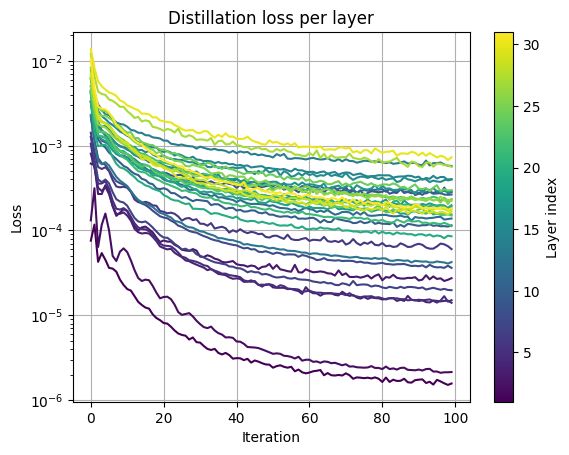
I created a DistillationPress that distills the (K,V) cache into a compressed (Kc,Vc) cache by minimizing ||A(q,K,V) - A(q,Kc,Vc)||^2. Checkout my notebook here: github.com/NVIDIA/kvpre.... More work needs to be done, it's just a first step (3/3)
20.11.2024 09:55 — 👍 5 🔁 1 💬 1 📌 0
KV cache quantization ? KV cache pruning ? KV cache approximation ? Replace "KV cache" by "MLP" and you'll see most of the research has already been explored🤯 So I gave it a try in within our new kvpress repo 👇 (2/3)
20.11.2024 09:55 — 👍 4 🔁 0 💬 1 📌 0
Ever noticed that the attention mechanism in transformers is essentially a two-layer MLP? 🤔
A(q, K, V) = V @ softmax(K / √d @ q)
Weights: K / √d and V
nonlinearity: softmax
💡This offers fresh insights into KV cache compression research 🧵(1/3)
20.11.2024 09:55 — 👍 56 🔁 5 💬 3 📌 0

kvpress/notebooks/expected_attention.ipynb at main · NVIDIA/kvpress
LLM KV cache compression made easy. Contribute to NVIDIA/kvpress development by creating an account on GitHub.
This release also introduces a new method we developed: Expected Attention! 🎯 By leveraging the normal distribution of LLM hidden states, it measures the importance of each key-value pair. Learn more in this notebook: github.com/NVIDIA/kvpre... (4/4)
19.11.2024 14:25 — 👍 3 🔁 0 💬 0 📌 0
kvpress aims at helping researchers and developers to create and benchmark KV cache compression techniques offering a user-friendly repo built on 🤗 Transformers. All implemented methods are training free and model agnostic (3/4)
19.11.2024 14:25 — 👍 2 🔁 0 💬 1 📌 0
Long-context LLMs are resource-heavy due to KV cache growth: e.g., 1M tokens for Llama 3.1-70B (float16) needs 330GB of memory 😬. This challenge has driven intense research into KV cache compression, with many submissions to #ICLR2025. (2/4)
19.11.2024 14:25 — 👍 1 🔁 0 💬 1 📌 0
🚀 Excited to announce KVPress — our open-source library for efficient LLM KV cache compression!
👉 Check it out (and drop a ⭐): github.com/NVIDIA/kvpress
🔗 Full details in the thread 🧵 (1/4)
19.11.2024 14:25 — 👍 50 🔁 6 💬 2 📌 2
Research Scientist at valeo.ai | Teaching at Polytechnique, ENS | Alumni at Mines Paris, Inria, ENS | AI for Autonomous Driving, Computer Vision, Machine Learning | Robotics amateur
⚲ Paris, France 🔗 abursuc.github.io
Senior Lecturer #USydCompSci at the University of Sydney. Postdocs IBM Research and Stanford; PhD at Columbia. Converts ☕ into puns: sometimes theorems. He/him.
Professor at Wharton, studying AI and its implications for education, entrepreneurship, and work. Author of Co-Intelligence.
Book: https://a.co/d/bC2kSj1
Substack: https://www.oneusefulthing.org/
Web: https://mgmt.wharton.upenn.edu/profile/emollick
Open source developer building tools to help journalists, archivists, librarians and others analyze, explore and publish their data. https://datasette.io […]
[bridged from https://fedi.simonwillison.net/@simon on the fediverse by https://fed.brid.gy/ ]
AI policy researcher, wife guy in training, fan of cute animals and sci-fi. Started a Substack recently: https://milesbrundage.substack.com/
AI safety at Anthropic, on leave from a faculty job at NYU.
Views not employers'.
I think you should join Giving What We Can.
cims.nyu.edu/~sbowman
Professor, Santa Fe Institute. Research on AI, cognitive science, and complex systems.
Website: https://melaniemitchell.me
Substack: https://aiguide.substack.com/
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
Senior Staff Research Scientist, Google DeepMind
Affiliated Lecturer, University of Cambridge
Associate, Clare Hall
GDL Scholar, ELLIS @ellis.eu
🇷🇸🇲🇪🇧🇦
Independent AI researcher, creator of datasette.io and llm.datasette.io, building open source tools for data journalism, writing about a lot of stuff at https://simonwillison.net/
Co-founder and CEO at Hugging Face
A LLN - large language Nathan - (RL, RLHF, society, robotics), athlete, yogi, chef
Writes http://interconnects.ai
At Ai2 via HuggingFace, Berkeley, and normal places
Professor, Programmer in NYC.
Cornell, Hugging Face 🤗
I build tools that propel communities forward
The AI community building the future!
DeepMind Professor of AI @Oxford
Scientific Director @Aithyra
Chief Scientist @VantAI
ML Lead @ProjectCETI
geometric deep learning, graph neural networks, generative models, molecular design, proteins, bio AI, 🐎 🎶


















