69_26_DIR_AII_RAD
Reference: 69_26_DIR_AII_RAD
Job title: Research Area Director – Artificial Intelligence (RE4/R4)
About BSC
The Barcelona Supercomputing Center - Centro Naciona
Open position for an AI Research Area Director at BSC, one of the largest European supercomputing facilities!
Apply if you are into:
* Open research 🤲
* Responsible science 🤔
* State-of-the-art AI advances 🧠
* Young & active teams 🛝
GPUs are on us. Barcelona is waiting 😉
www.bsc.es/join-us/job-...
10.02.2026 14:50 —
👍 0
🔁 0
💬 0
📌 0

Are you into Chip Design, EDA or just like to do RTL code for fun? Check out the largest benchmarking of LLMs for Verilog generation: TuRTLe 🐢
It includes 40 open LLMs evaluated on 4 benchmarks, following 5 tasks. And its only growing!
huggingface.co/spaces/HPAI-...
arxiv.org/abs/2504.01986
03.06.2025 16:08 —
👍 3
🔁 2
💬 0
📌 0

So many healthcare LLMs, and yet so little information! Check out this table summarizing contributions, and find more details in our latest pre-print: arxiv.org/abs/2505.04388
22.05.2025 12:18 —
👍 0
🔁 0
💬 0
📌 0
Biology needs to be reduced to fundamental components so that mysticism and religion do not corrupt its might.
Same happens to LLMs. These are not thinking machines, in any definition of thinking we may agree on. And the NTP reduction clearly shows that.
21.05.2025 08:22 —
👍 1
🔁 0
💬 0
📌 0
Mostly agree here, though I would rather use the word mimic than persuade. Persuade entails a purpose, which I'm not sure LLMs have. That, is, does a mathematical function have a purpose?
21.05.2025 08:11 —
👍 9
🔁 0
💬 0
📌 0
Exactly! The most effective control measure, RAG, is still a patch that can provide no technical guarantee. Just a strong bias that models may not follow.
The sooner we understand the limits of LLMs, the sooner we'll learn to deploy them properly.
21.05.2025 08:08 —
👍 1
🔁 0
💬 0
📌 0
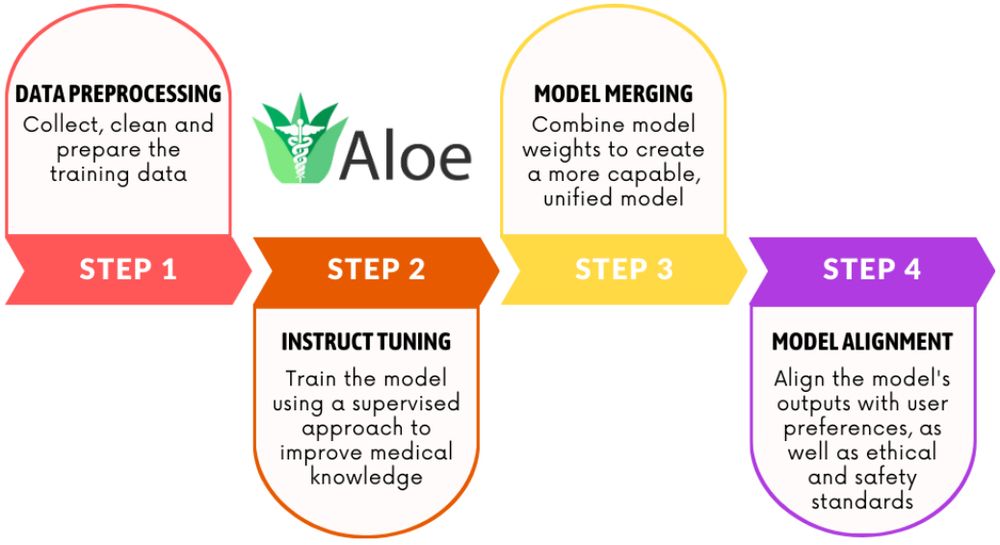

The Aloe Beta preprint includes full details on data & training setup.
Plus four different evaluation methods (including medical expert).
Plus a risk assessment of healthcare LLMs.
Two years of work condensed in a few pages, figures and tables.
Love open research!
huggingface.co/papers/2505....
21.05.2025 08:06 —
👍 0
🔁 0
💬 0
📌 0
350_25_CS_AIR_RE2
Reference: 350_25_CS_AIR_RE2
Job title: Research Engineer - AI Factory (RE2)
About BSC
The Barcelona Supercomputing Center - Centro Nacional de Supercomputación (BSC-
We just opened two MLOps Engineer positions at @bsc-cns.bsky.social
Our active and young research team needs someone to help sustain and improve our services, including HPC clusters, automated pipelines, artifact managements and much more!
Are you up for the challenge?
www.bsc.es/join-us/job-...
06.05.2025 17:03 —
👍 0
🔁 0
💬 0
📌 0
Last week our team presented this at NAACL. Check out the beautiful poster they put together 😍
06.05.2025 16:39 —
👍 1
🔁 0
💬 0
📌 0
Though both data sources have the same origin (visual inspection of embryo change) I'd expect features found by humans and features found by a neural net to be complementary.
I guess the intrinsic variance is what dominates here. We can only know so much about an embryo by just looking at it.
11.04.2025 14:35 —
👍 0
🔁 0
💬 0
📌 0
Working on a project for evaluating embryo quality using in-vitro fertilization data.
A random forest using morphokinetic features of embryo evolution visually annotated by experts, and a CNN directly using static images get similar performance. Separately AND together.
I find it surprising...
11.04.2025 14:35 —
👍 0
🔁 0
💬 1
📌 0
There are quite a lot of researchers who a so preoccupied with whether or not they could get the funding, they don't stop to think if they should.
Being chased by dinosaurs and writing grants. Same thing.
09.04.2025 08:32 —
👍 1
🔁 0
💬 0
📌 0

The recipe is simple 🧑🍳 :
1. A good open model 🍞
2. A properly tuned RAG pipeline 🍒
And you will be cooking a five star AI system ⭐ ⭐ ⭐ ⭐ ⭐
See you on the AIAI 2025 conference, where we will be presenting this work, done at @bsc-cns.bsky.social and @hpai.bsky.social
04.04.2025 14:35 —
👍 2
🔁 0
💬 0
📌 0


How expensive 🫰 is it to get the best LLM performance? How much cash needs to burn 💸 to get reliable responses? Pareto optimal plots answer these questions.
Our research shows it is economically feasible and scalable to achieve O1 level performance at a fraction of the cost.
buff.ly/ji1VHiV
04.04.2025 14:35 —
👍 2
🔁 0
💬 1
📌 0


Our LLM safety project, Egida, reached 2K downloads 😀
It includes +60K safety questions expanded with jailbreaking prompts.
The four models trained (and released) show strong signs of safety alignment and generalization capacity. Check out the 🤗 HF page and the paper for details!
buff.ly/kxFVyl2
01.04.2025 21:11 —
👍 0
🔁 0
💬 0
📌 0

TuRTLe Leaderboard - a Hugging Face Space by HPAI-BSC
A Unified Evaluation of LLMs for RTL Generation.
Today we release the TuRTLe leaderboard! 🐢
Are you in the Chip Design or EDA business? Wanna know which LLMs are best for the task? By integrating 4 benchmarks, TuRTLe evaluates:
* Syntax
* Functionality
* Synthesizability
* Power, Performance and Area metrics
huggingface.co/spaces/HPAI-...
01.04.2025 14:15 —
👍 1
🔁 0
💬 0
📌 0
Disclaimer: Only text questions were used to evaluate LLMs, unlike students. Student's score computed under the assumption that all questions were answered, which may not be the case.
buff.ly/3Xa9gFc
03.03.2025 15:35 —
👍 0
🔁 0
💬 0
📌 0

HPAI-BSC/CareQA · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
MIR is Spain's medical entrance exam. Best students reach an estimate accuracy of +90. Two or three every year.
We took MIR, '20-'24 to test open LLMs. Llama 3.1 based models, like Aloe, reach +80 in accuracy.
Deepseep R1 reaches +88. Boosted by a RAG system, 92.
buff.ly/4bbbXMw
buff.ly/4hLrhBV
03.03.2025 15:35 —
👍 0
🔁 0
💬 1
📌 0
After listening to the latest @fallofcivspod.bsky.social episode about the Mongolian Empire, by @paulcooper34.bsky.social , I realized Mongols and the Fremen from Dune share remarkable similarities.
Skilled warriors adapted to harsh environments, taking over a society they don't want to adopt.
28.02.2025 08:08 —
👍 1
🔁 0
💬 1
📌 0
I like the cell one 👍
I'm an empiricist, so we attack metrics by developing adversarial benchmarks that expose model shortcuts. Plus, its a lot of fun to show how fragile LLMs can be.
23.02.2025 18:26 —
👍 1
🔁 0
💬 0
📌 0
While writing a paper I consistently learn general insights that are too general or not tested enough to be sold as paper contributions, but are great for conversation :)
23.02.2025 09:13 —
👍 1
🔁 0
💬 1
📌 0
Human evaluation of LLMs is close to saturation. Models have been optimized so much for plausibility, that we are unable to tell good from bad. Only experts in expert domains can see a meaningful difference.
21.02.2025 17:41 —
👍 0
🔁 0
💬 0
📌 0

Automatic Evaluation of Healthcare LLMs Beyond Question-Answering
Current Large Language Models (LLMs) benchmarks are often based on open-ended or close-ended QA evaluations, avoiding the requirement of human labor. Close-ended measurements evaluate the factuality…
After a year working on LLM evaluation, our benchmarking paper is finally out (to be presented at NAACL 2025). Main lessons:
* All LLM evals are wrong, some are slightly useful.
* Goodhart's law. All the time. Everywhere.
* Do lots of different evals and hope for the best.
21.02.2025 15:35 —
👍 2
🔁 0
💬 1
📌 1
Evaluating LLMs is a bit like paleontology. Trying to understand the behavior of very complex entities by observing only noisy and partial evidence. How do paleontologists deal with the uncertainty and frustration? Do they also feel like doing alchemy instead of science?
21.02.2025 10:49 —
👍 0
🔁 0
💬 0
📌 0
Remarkable effort. Questionable motivation.
19.02.2025 20:45 —
👍 0
🔁 0
💬 0
📌 0
Wisdom from my 6y old daughter: "A king is a just person disguised as king."
19.02.2025 19:08 —
👍 0
🔁 0
💬 0
📌 0
Over and over again I keep finding @sarahooker.bsky.social papers to reference. This time about ELO rankings. She's always 2-3 years ahead...
19.02.2025 15:12 —
👍 1
🔁 0
💬 0
📌 0

Summary of LLM learning methods
So many keywords around LLM training, its easy to get lost.
For an incoming paper, did this little visual summary. Would you change anything?
18.02.2025 17:48 —
👍 0
🔁 0
💬 0
📌 0
Only two weeks until the deadline!
Submit your paper and see you in Germany :)
12.02.2025 17:12 —
👍 0
🔁 0
💬 0
📌 0

