

Codebase (Gapetron, Apache-2 licence): github.com/NathanGodey/...
12.11.2025 17:26 — 👍 2 🔁 0 💬 0 📌 0
Codebase (Gapetron, Apache-2 licence): github.com/NathanGodey/...
12.11.2025 17:26 — 👍 2 🔁 0 💬 0 📌 0
Models (OpenRAIL-M licence): huggingface.co/collections/...
12.11.2025 17:26 — 👍 1 🔁 1 💬 1 📌 0Thanks also to GENCI @gencifrance.bsky.social and CINES for compute support.
12.11.2025 17:26 — 👍 1 🔁 0 💬 1 📌 0Congratulations to Nathan Godey @nthngdy.bsky.social, Wissam Antoun @wissamantoun.bsky.social and Rian Touchent, who did most of the work, supervised by Djamé Seddah @zehavoc.bsky.social, myself, Éric de La Clergerie and Rachel Bawden @rachelbawden.bsky.social (in order of decreasing implication).
12.11.2025 17:26 — 👍 1 🔁 0 💬 1 📌 0Note: These models are research artefacts and are not designed for general public use or production environments.
12.11.2025 17:26 — 👍 0 🔁 0 💬 1 📌 0If you’d like to find out what we discovered, I encourage you to read Nathan's thread (reposted in the first post of this thread) as well as the paper, where we describe our experiments and findings in detail: arxiv.org/pdf/2510.25771
12.11.2025 17:26 — 👍 0 🔁 0 💬 1 📌 0Our main goal with this project was to deepen our understanding of language models' training dynamics and of the impact of the properties of their pretraining data. The results we obtained led us to take a closer look at a phenomenon whose impact is often underestimated: data contamination.
12.11.2025 17:26 — 👍 0 🔁 0 💬 1 📌 0I'm proud to share that at @inriaparisnlp.bsky.social we have released Gaperon — a suite of generative language models trained on French, English and code data, the largest of which has 24 billion parameters. Both the models and the code are being published under open licences. Short thread🧵
12.11.2025 17:26 — 👍 7 🔁 5 💬 1 📌 0
We are delighted to announce our next seminar by Hal Daumé III @haldaume3.bsky.social (@univofmaryland.bsky.social, currently on sabbatical at @sorbonne-universite.fr) entitled "Fairness and Trustworthiness in Generative Al" on Friday 20th June at 11am CEST.
18.06.2025 08:09 — 👍 9 🔁 3 💬 2 📌 0
Does your LLM truly comprehend the complexity of the code it generates? 🥰
Introducing our new non-saturated (for at least the coming week? 😉) benchmark:
✨BigO(Bench)✨ - Can LLMs Generate Code with Controlled Time and Space Complexity?
Check out the details below !👇
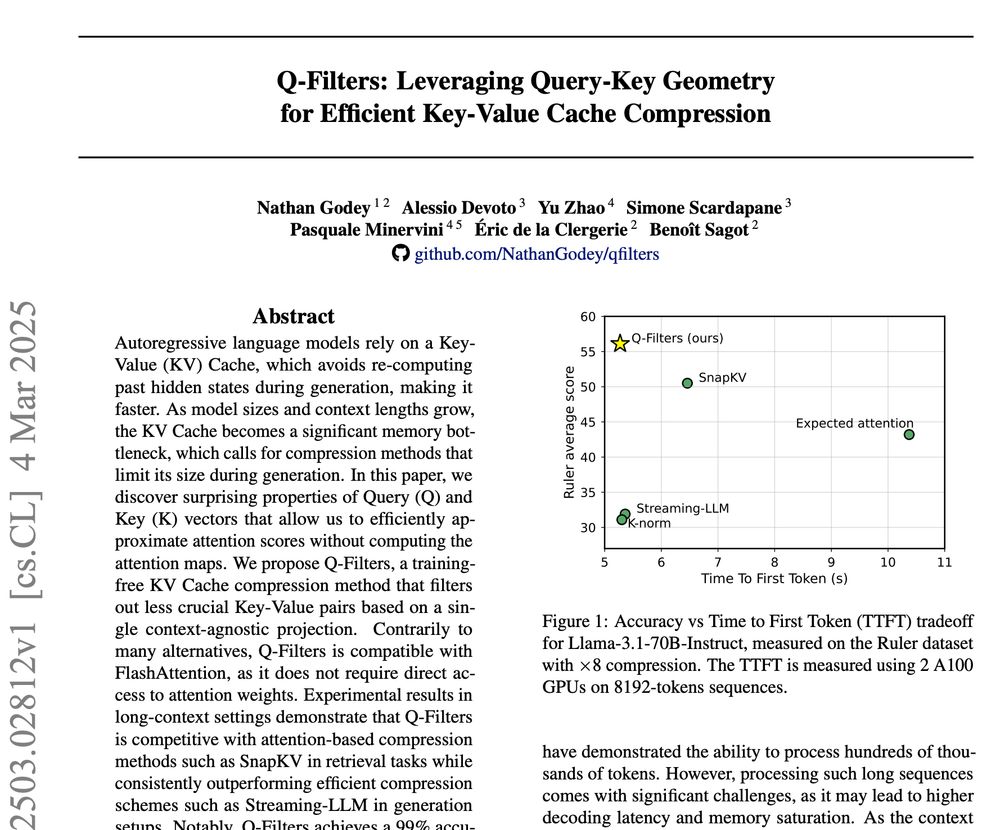
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention