
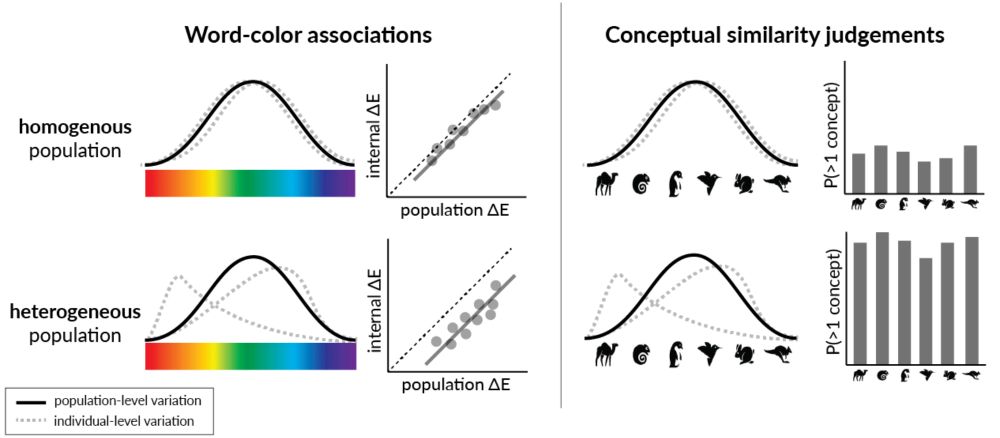
NEW blog post: Do modern #LLMs capture the conceptual diversity of human populations? #KempnerInstitute researchers find #alignment reduces conceptual diversity of language models. bit.ly/4hNjtiI
10.02.2025 15:19 — 👍 12 🔁 3 💬 0 📌 0
NEW blog post: Do modern #LLMs capture the conceptual diversity of human populations? #KempnerInstitute researchers find #alignment reduces conceptual diversity of language models. bit.ly/4hNjtiI
10.02.2025 15:19 — 👍 12 🔁 3 💬 0 📌 0
NEW in the #KempnerInstitute blog: learn about ProCyon, a multimodal foundation model to model, generate & predict protein phenotypes. Read it here: bit.ly/4fA8xUk
19.12.2024 19:22 — 👍 6 🔁 1 💬 0 📌 0
Calling college grads interested in intelligence research: the application for the #KempnerInstitute's post-bac program w/ the Harvard Kenneth C. Griffin Graduate School of Arts and Sciences Office for Equity, Diversity, Inclusion & Belonging is now open! Apply by Feb. 1, 2025.
t.co/jdJrzRegL0

NEW in the #KempnerInstitute blog: A method to predict how #LLMs scale w/ compute across different datasets. Read it here:
09.12.2024 20:44 — 👍 7 🔁 2 💬 0 📌 0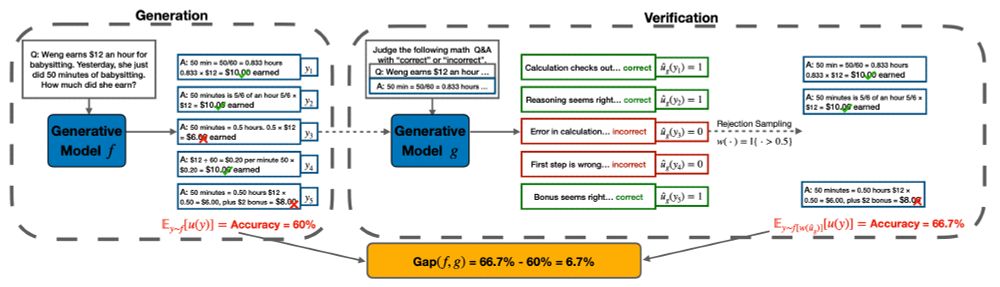
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)
06.12.2024 18:02 — 👍 12 🔁 4 💬 1 📌 1
NEW: we have an exciting opportunity for a tenure-track professor at the #KempnerInstitute and the John A. Paulson School of Engineering and Applied Sciences (SEAS). Read the full description & apply today: academicpositions.harvard.edu/postings/14362
#ML #AI
(5/n) 🤝 Shoutout to some great collaborators:
@hanlin_zhang, @depen_morwani, @vyasnikhil96, @uuujingfeng, @difanzou, @udayaghai
#AI #ML #ScalingLaws

(4/n) 🧠 Want theory? We provide rigorous justifications, provide critical hyperparameters, and characterize lr decay to the overtraining regime.
Check out the details here:
📄 arxiv.org/abs/2410.21676
📝 Blog: tinyurl.com/ysufbwsr

(3/n) 📊 From our controlled experiments on language models:
📈CBS increases as dataset size grows
🤏CBS remains weakly dependent on model size
Data size, not model size, drives parallel efficiency for large-scale pre-training.

(2/n) 🤔 How does CBS scale with model size and data size in pre-training? We find that CBS scales with data size and is largely invariant to model size. Prior beliefs that CBS scales with model size may have stemmed from Chinchilla’s coupled N-D scaling.
22.11.2024 20:19 — 👍 0 🔁 0 💬 1 📌 0
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.
22.11.2024 20:19 — 👍 16 🔁 4 💬 2 📌 0
How does test loss change as we change the training data? And how does this interact with scaling laws?
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.